 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncrementally Improving Graph WaveNet Performance on Traffic Prediction
Dec 11, 2019
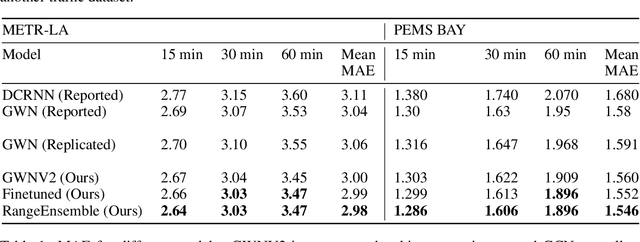


We present a series of modifications which improve upon Graph WaveNet's previously state-of-the-art performance on the METR-LA traffic prediction task. The goal of this task is to predict the future speed of traffic at each sensor in a network using the past hour of sensor readings. Graph WaveNet (GWN) is a spatio-temporal graph neural network which interleaves graph convolution to aggregate information from nearby sensors and dilated convolutions to aggregate information from the past. We improve GWN by (1) using better hyperparameters, (2) adding connections that allow larger gradients to flow back to the early convolutional layers, and (3) pretraining on an easier short-term traffic prediction task. These modifications reduce the mean absolute error by .06 on the METR-LA task, nearly equal to GWN's improvement over its predecessor. These improvements generalize to the PEMS-BAY dataset, with similar relative magnitude. We also show that ensembling separate models for short-and long-term predictions further improves performance. Code is available at https://github.com/sshleifer/Graph-WaveNet .
Domain-Relevant Embeddings for Medical Question Similarity
Nov 15, 2019
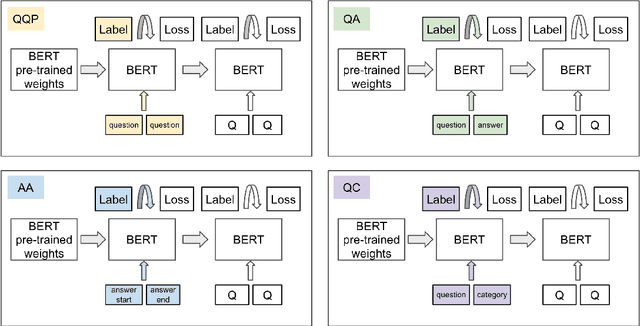

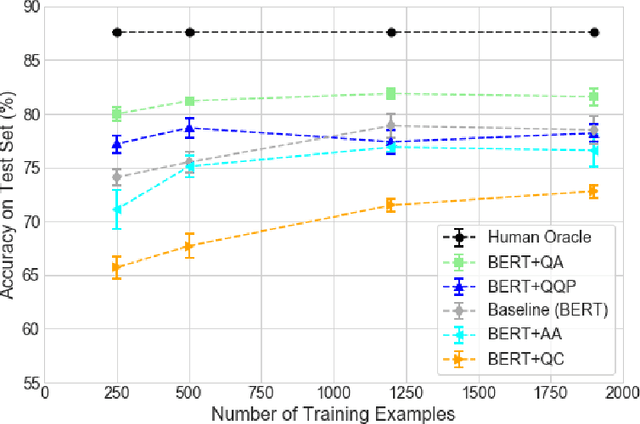
The rate at which medical questions are asked online far exceeds the capacity of qualified people to answer them, and many of these questions are not unique. Identifying same-question pairs could enable questions to be answered more effectively. While many research efforts have focused on the problem of general question similarity for non-medical applications, these approaches do not generalize well to the medical domain, where medical expertise is often required to determine semantic similarity. In this paper, we show how a semi-supervised approach of pre-training a neural network on medical question-answer pairs is a particularly useful intermediate task for the ultimate goal of determining medical question similarity. While other pre-training tasks yield an accuracy below 78.7% on this task, our model achieves an accuracy of 82.6% with the same number of training examples, and an accuracy of 80.0% with a much smaller training set.