 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Transfer Learning for Identifying Similar Questions: Matching User Questions to COVID-19 FAQs
Aug 04, 2020
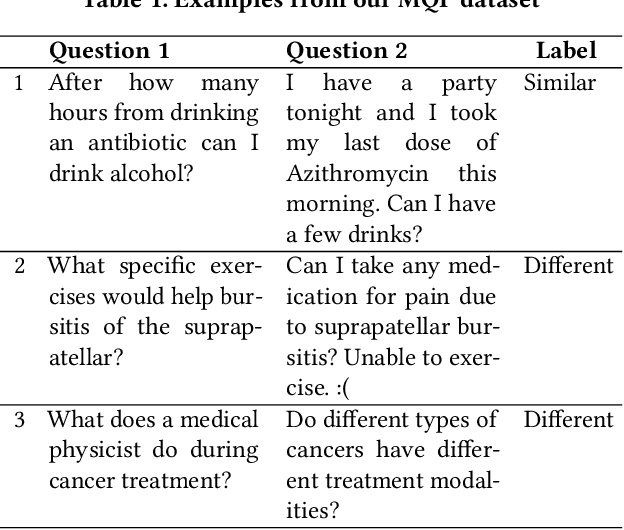
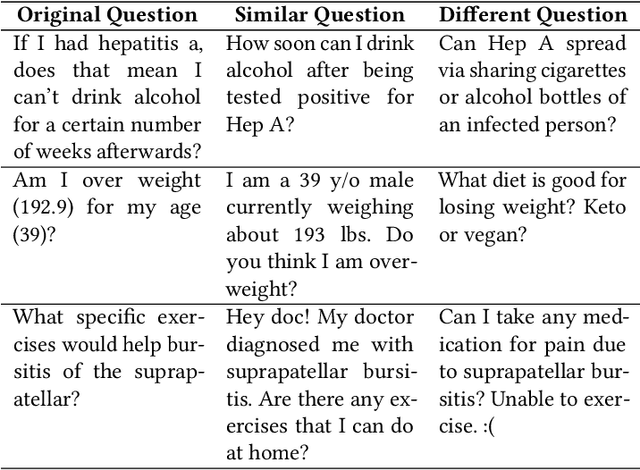
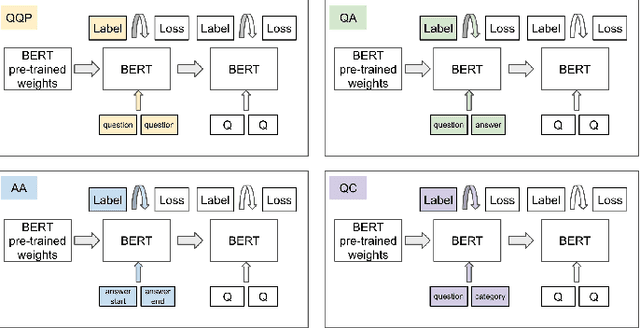
People increasingly search online for answers to their medical questions but the rate at which medical questions are asked online significantly exceeds the capacity of qualified people to answer them. This leaves many questions unanswered or inadequately answered. Many of these questions are not unique, and reliable identification of similar questions would enable more efficient and effective question answering schema. COVID-19 has only exacerbated this problem. Almost every government agency and healthcare organization has tried to meet the informational need of users by building online FAQs, but there is no way for people to ask their question and know if it is answered on one of these pages. While many research efforts have focused on the problem of general question similarity, these approaches do not generalize well to domains that require expert knowledge to determine semantic similarity, such as the medical domain. In this paper, we show how a double fine-tuning approach of pretraining a neural network on medical question-answer pairs followed by fine-tuning on medical question-question pairs is a particularly useful intermediate task for the ultimate goal of determining medical question similarity. While other pretraining tasks yield an accuracy below 78.7% on this task, our model achieves an accuracy of 82.6% with the same number of training examples, an accuracy of 80.0% with a much smaller training set, and an accuracy of 84.5% when the full corpus of medical question-answer data is used. We also describe a currently live system that uses the trained model to match user questions to COVID-related FAQs.
Classification as Decoder: Trading Flexibility for Control in Medical Dialogue
Nov 16, 2019
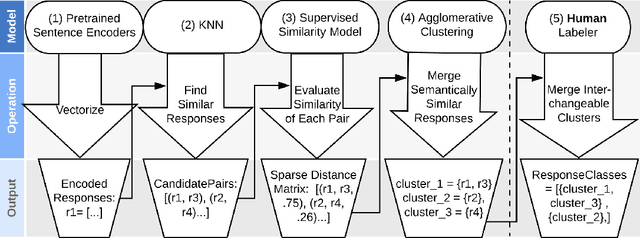
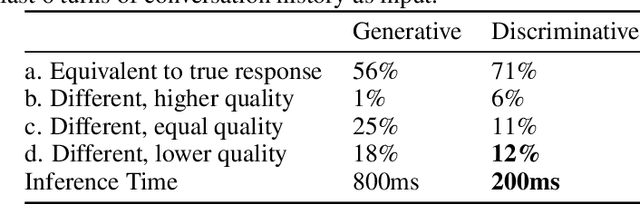
Generative seq2seq dialogue systems are trained to predict the next word in dialogues that have already occurred. They can learn from large unlabeled conversation datasets, build a deeper understanding of conversational context, and generate a wide variety of responses. This flexibility comes at the cost of control, a concerning tradeoff in doctor/patient interactions. Inaccuracies, typos, or undesirable content in the training data will be reproduced by the model at inference time. We trade a small amount of labeling effort and some loss of response variety in exchange for quality control. More specifically, a pretrained language model encodes the conversational context, and we finetune a classification head to map an encoded conversational context to a response class, where each class is a noisily labeled group of interchangeable responses. Experts can update these exemplar responses over time as best practices change without retraining the classifier or invalidating old training data. Expert evaluation of 775 unseen doctor/patient conversations shows that only 12% of the discriminative model's responses are worse than the what the doctor ended up writing, compared to 18% for the generative model.
Domain-Relevant Embeddings for Medical Question Similarity
Nov 15, 2019
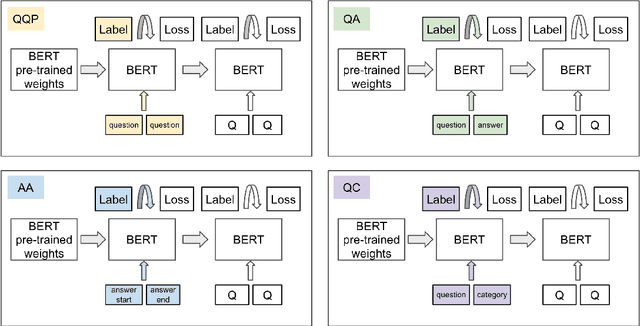

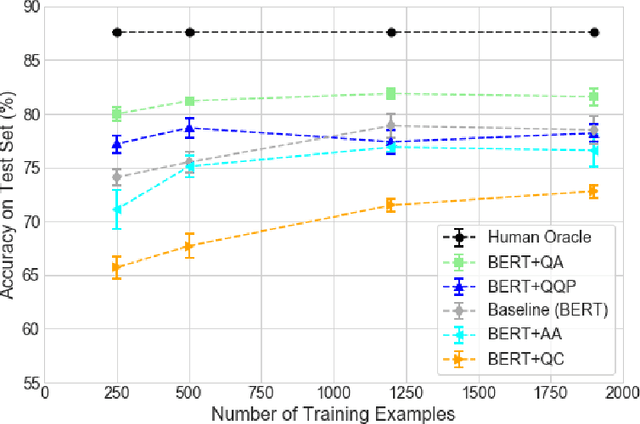
The rate at which medical questions are asked online far exceeds the capacity of qualified people to answer them, and many of these questions are not unique. Identifying same-question pairs could enable questions to be answered more effectively. While many research efforts have focused on the problem of general question similarity for non-medical applications, these approaches do not generalize well to the medical domain, where medical expertise is often required to determine semantic similarity. In this paper, we show how a semi-supervised approach of pre-training a neural network on medical question-answer pairs is a particularly useful intermediate task for the ultimate goal of determining medical question similarity. While other pre-training tasks yield an accuracy below 78.7% on this task, our model achieves an accuracy of 82.6% with the same number of training examples, and an accuracy of 80.0% with a much smaller training set.
Classification As Decoder: Trading Flexibility For Control In Neural Dialogue
Oct 17, 2019Generative seq2seq dialogue systems are trained to predict the next word in dialogues that have already occurred. They can learn from large unlabeled conversation datasets, build a deep understanding of conversational context, and generate a wide variety of responses. This flexibility comes at the cost of control. Undesirable responses in the training data will be reproduced by the model at inference time, and longer generations often don't make sense. Instead of generating responses one word at a time, we train a classifier to choose from a predefined list of full responses. The classifier is trained on (conversation context, response class) pairs, where each response class is a noisily labeled group of interchangeable responses. At inference, we generate the exemplar response associated with the predicted response class. Experts can edit and improve these exemplar responses over time without retraining the classifier or invalidating old training data. Human evaluation of 775 unseen doctor/patient conversations shows that this tradeoff improves responses. Only 12% of our discriminative approach's responses are worse than the doctor's response in the same conversational context, compared to 18% for the generative model. A discriminative model trained without any manual labeling of response classes achieves equal performance to the generative model.
Open Set Medical Diagnosis
Oct 07, 2019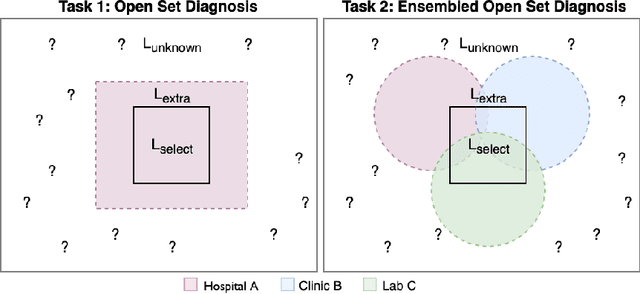
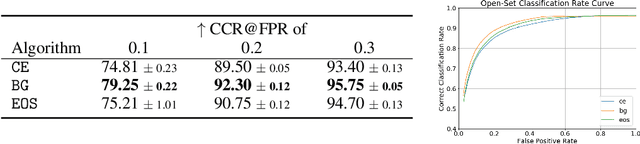
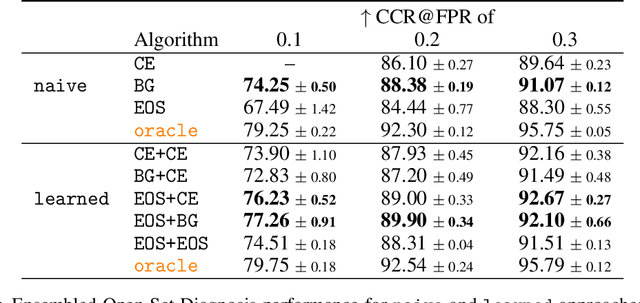

Machine-learned diagnosis models have shown promise as medical aides but are trained under a closed-set assumption, i.e. that models will only encounter conditions on which they have been trained. However, it is practically infeasible to obtain sufficient training data for every human condition, and once deployed such models will invariably face previously unseen conditions. We frame machine-learned diagnosis as an open-set learning problem, and study how state-of-the-art approaches compare. Further, we extend our study to a setting where training data is distributed across several healthcare sites that do not allow data pooling, and experiment with different strategies of building open-set diagnostic ensembles. Across both settings, we observe consistent gains from explicitly modeling unseen conditions, but find the optimal training strategy to vary across settings.
Prototypical Clustering Networks for Dermatological Disease Diagnosis
Nov 07, 2018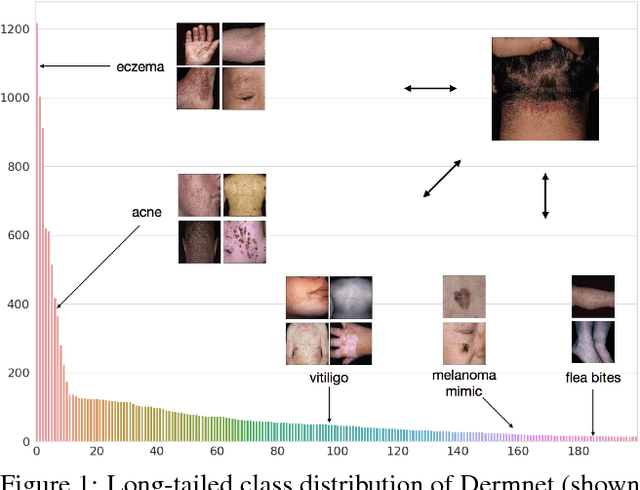
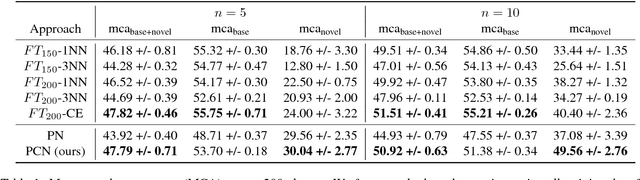
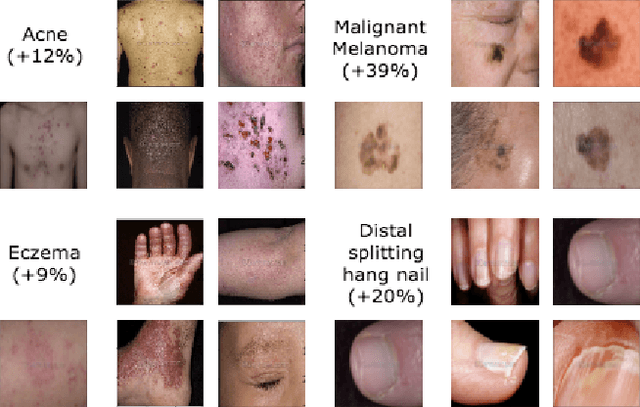
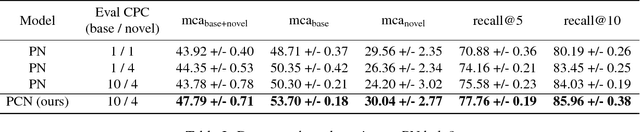
We consider the problem of image classification for the purpose of aiding doctors in dermatological diagnosis. Dermatological diagnosis poses two major challenges for standard off-the-shelf techniques: First, the data distribution is typically extremely long tailed. Second, intra-class variability is often large. To address the first issue, we formulate the problem as low-shot learning, where once deployed, a base classifier must rapidly generalize to diagnose novel conditions given very few labeled examples. To model diverse classes effectively, we propose Prototypical Clustering Networks (PCN), an extension to Prototypical Networks that learns a mixture of prototypes for each class. Prototypes are initialized for each class via clustering and refined via an online update scheme. Classification is performed by measuring similarity to a weighted combination of prototypes within a class, where the weights are the inferred cluster responsibilities. We demonstrate the strengths of our approach in effective diagnosis on a realistic dataset of dermatological conditions.