 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Medical Diagnosis
Paper and Code
Oct 07, 2019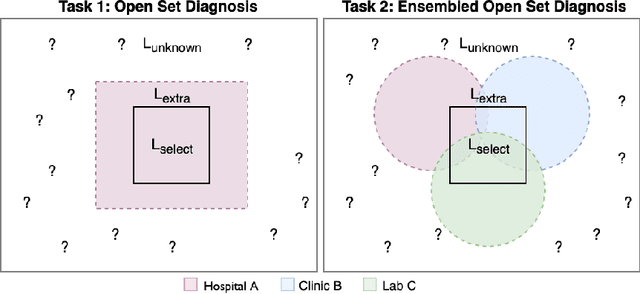
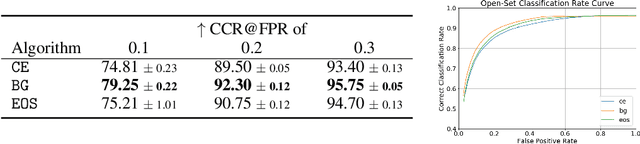
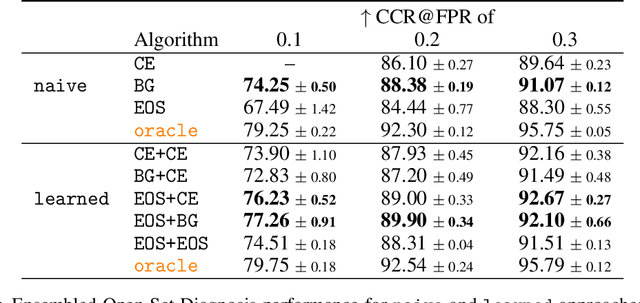

Machine-learned diagnosis models have shown promise as medical aides but are trained under a closed-set assumption, i.e. that models will only encounter conditions on which they have been trained. However, it is practically infeasible to obtain sufficient training data for every human condition, and once deployed such models will invariably face previously unseen conditions. We frame machine-learned diagnosis as an open-set learning problem, and study how state-of-the-art approaches compare. Further, we extend our study to a setting where training data is distributed across several healthcare sites that do not allow data pooling, and experiment with different strategies of building open-set diagnostic ensembles. Across both settings, we observe consistent gains from explicitly modeling unseen conditions, but find the optimal training strategy to vary across settings.