 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification As Decoder: Trading Flexibility For Control In Neural Dialogue
Paper and Code
Oct 17, 2019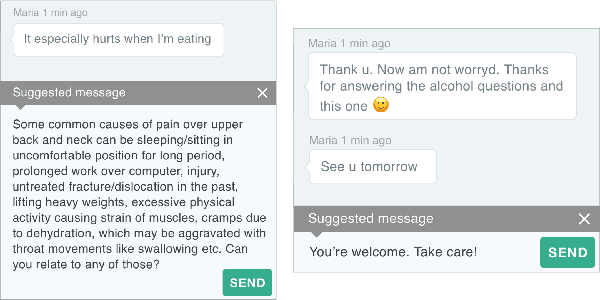
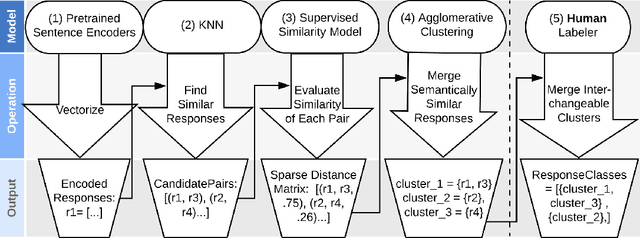
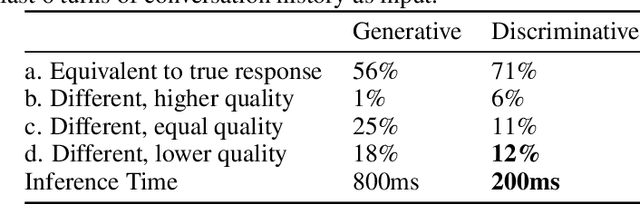
Generative seq2seq dialogue systems are trained to predict the next word in dialogues that have already occurred. They can learn from large unlabeled conversation datasets, build a deep understanding of conversational context, and generate a wide variety of responses. This flexibility comes at the cost of control. Undesirable responses in the training data will be reproduced by the model at inference time, and longer generations often don't make sense. Instead of generating responses one word at a time, we train a classifier to choose from a predefined list of full responses. The classifier is trained on (conversation context, response class) pairs, where each response class is a noisily labeled group of interchangeable responses. At inference, we generate the exemplar response associated with the predicted response class. Experts can edit and improve these exemplar responses over time without retraining the classifier or invalidating old training data. Human evaluation of 775 unseen doctor/patient conversations shows that this tradeoff improves responses. Only 12% of our discriminative approach's responses are worse than the doctor's response in the same conversational context, compared to 18% for the generative model. A discriminative model trained without any manual labeling of response classes achieves equal performance to the generative model.