 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Policy Learning is Sensitive to Goal Space Design
May 04, 2019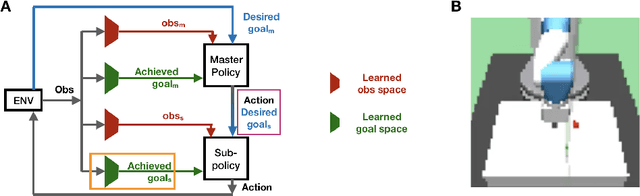
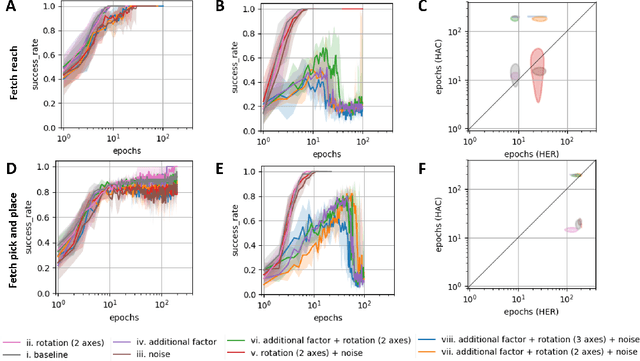


Hierarchy in reinforcement learning agents allows for control at multiple time scales yielding improved sample efficiency, the ability to deal with long time horizons and transferability of sub-policies to tasks outside the training distribution. It is often implemented as a master policy providing goals to a sub-policy. Ideally, we would like the goal-spaces to be learned, however, properties of optimal goal spaces still remain unknown and consequently there is no method yet to learn optimal goal spaces. Motivated by this, we systematically analyze how various modifications to the ground-truth goal-space affect learning in hierarchical models with the aim of identifying important properties of optimal goal spaces. Our results show that, while rotation of ground-truth goal spaces and noise had no effect, having additional unnecessary factors significantly impaired learning in hierarchical models.
Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
Jan 30, 2018The Deep Learning (DL) community sees many novel topologies published each year. Achieving high performance on each new topology remains challenging, as each requires some level of manual effort. This issue is compounded by the proliferation of frameworks and hardware platforms. The current approach, which we call "direct optimization", requires deep changes within each framework to improve the training performance for each hardware backend (CPUs, GPUs, FPGAs, ASICs) and requires $\mathcal{O}(fp)$ effort; where $f$ is the number of frameworks and $p$ is the number of platforms. While optimized kernels for deep-learning primitives are provided via libraries like Intel Math Kernel Library for Deep Neural Networks (MKL-DNN), there are several compiler-inspired ways in which performance can be further optimized. Building on our experience creating neon (a fast deep learning library on GPUs), we developed Intel nGraph, a soon to be open-sourced C++ library to simplify the realization of optimized deep learning performance across frameworks and hardware platforms. Initially-supported frameworks include TensorFlow, MXNet, and Intel neon framework. Initial backends are Intel Architecture CPUs (CPU), the Intel(R) Nervana Neural Network Processor(R) (NNP), and NVIDIA GPUs. Currently supported compiler optimizations include efficient memory management and data layout abstraction. In this paper, we describe our overall architecture and its core components. In the future, we envision extending nGraph API support to a wider range of frameworks, hardware (including FPGAs and ASICs), and compiler optimizations (training versus inference optimizations, multi-node and multi-device scaling via efficient sub-graph partitioning, and HW-specific compounding of operations).
Flexpoint: An Adaptive Numerical Format for Efficient Training of Deep Neural Networks
Dec 02, 2017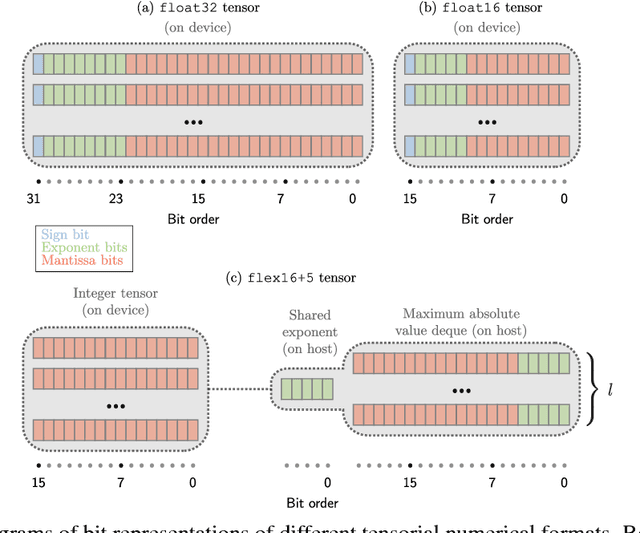
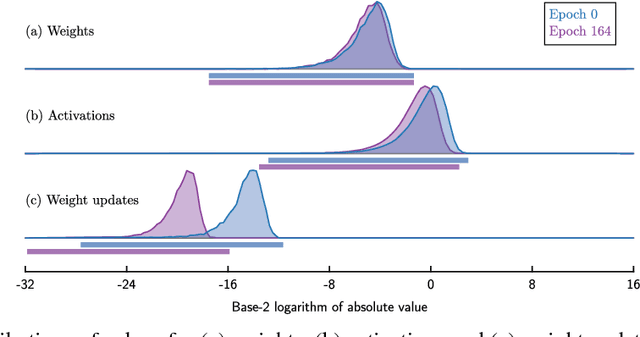
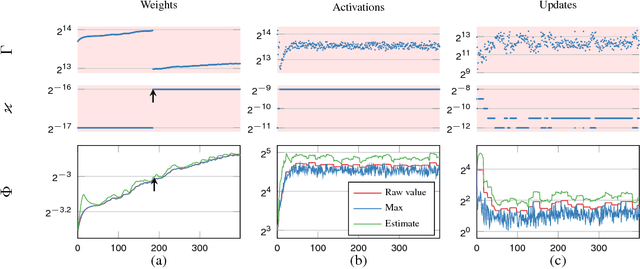
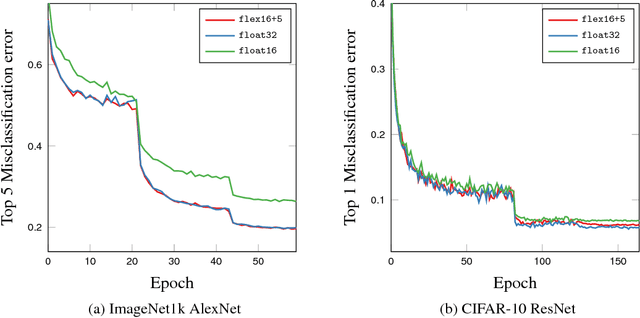
Deep neural networks are commonly developed and trained in 32-bit floating point format. Significant gains in performance and energy efficiency could be realized by training and inference in numerical formats optimized for deep learning. Despite advances in limited precision inference in recent years, training of neural networks in low bit-width remains a challenging problem. Here we present the Flexpoint data format, aiming at a complete replacement of 32-bit floating point format training and inference, designed to support modern deep network topologies without modifications. Flexpoint tensors have a shared exponent that is dynamically adjusted to minimize overflows and maximize available dynamic range. We validate Flexpoint by training AlexNet, a deep residual network and a generative adversarial network, using a simulator implemented with the neon deep learning framework. We demonstrate that 16-bit Flexpoint closely matches 32-bit floating point in training all three models, without any need for tuning of model hyperparameters. Our results suggest Flexpoint as a promising numerical format for future hardware for training and inference.
Discovering Hidden Factors of Variation in Deep Networks
Jun 17, 2015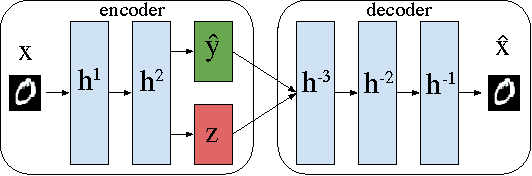
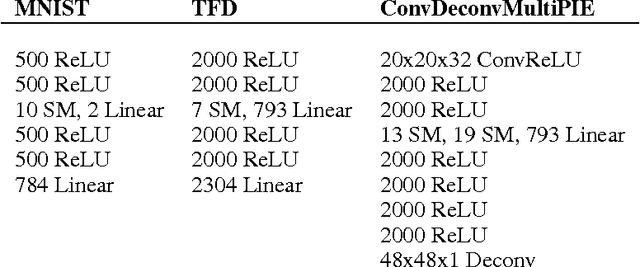


Deep learning has enjoyed a great deal of success because of its ability to learn useful features for tasks such as classification. But there has been less exploration in learning the factors of variation apart from the classification signal. By augmenting autoencoders with simple regularization terms during training, we demonstrate that standard deep architectures can discover and explicitly represent factors of variation beyond those relevant for categorization. We introduce a cross-covariance penalty (XCov) as a method to disentangle factors like handwriting style for digits and subject identity in faces. We demonstrate this on the MNIST handwritten digit database, the Toronto Faces Database (TFD) and the Multi-PIE dataset by generating manipulated instances of the data. Furthermore, we demonstrate these deep networks can extrapolate `hidden' variation in the supervised signal.