 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Policy Learning is Sensitive to Goal Space Design
Paper and Code
May 04, 2019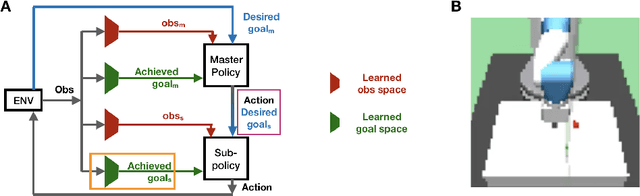
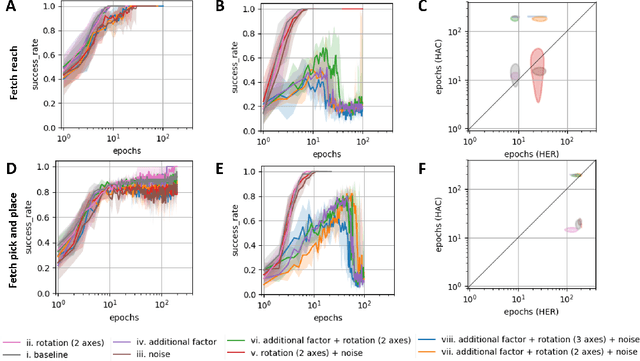


Hierarchy in reinforcement learning agents allows for control at multiple time scales yielding improved sample efficiency, the ability to deal with long time horizons and transferability of sub-policies to tasks outside the training distribution. It is often implemented as a master policy providing goals to a sub-policy. Ideally, we would like the goal-spaces to be learned, however, properties of optimal goal spaces still remain unknown and consequently there is no method yet to learn optimal goal spaces. Motivated by this, we systematically analyze how various modifications to the ground-truth goal-space affect learning in hierarchical models with the aim of identifying important properties of optimal goal spaces. Our results show that, while rotation of ground-truth goal spaces and noise had no effect, having additional unnecessary factors significantly impaired learning in hierarchical models.