 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation theoretic analysis of computational models as a tool to understand the neural basis of behaviors
Jun 02, 2021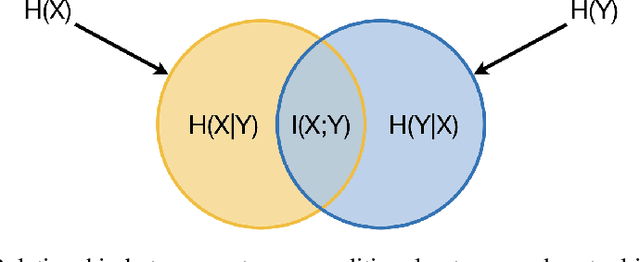
One of the greatest research challenges of this century is to understand the neural basis for how behavior emerges in brain-body-environment systems. To this end, research has flourished along several directions but have predominantly focused on the brain. While there is in an increasing acceptance and focus on including the body and environment in studying the neural basis of behavior, animal researchers are often limited by technology or tools. Computational models provide an alternative framework within which one can study model systems where ground-truth can be measured and interfered with. These models act as a hypothesis generation framework that would in turn guide experimentation. Furthermore, the ability to intervene as we please, allows us to conduct in-depth analysis of these models in a way that cannot be performed in natural systems. For this purpose, information theory is emerging as a powerful tool that can provide insights into the operation of these brain-body-environment models. In this work, I provide an introduction, a review and discussion to make a case for how information theoretic analysis of computational models is a potent research methodology to help us better understand the neural basis of behavior.
On Training Flexible Robots using Deep Reinforcement Learning
Jul 13, 2019



The use of robotics in controlled environments has flourished over the last several decades and training robots to perform tasks using control strategies developed from dynamical models of their hardware have proven very effective. However, in many real-world settings, the uncertainties of the environment, the safety requirements and generalized capabilities that are expected of robots make rigid industrial robots unsuitable. This created great research interest into developing control strategies for flexible robot hardware for which building dynamical models are challenging. In this paper, inspired by the success of deep reinforcement learning (DRL) in other areas, we systematically study the efficacy of policy search methods using DRL in training flexible robots. Our results indicate that DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility. We also note that DRL using Deep Deterministic Policy Gradients can be sensitive to the choice of sensors and adding more informative sensors does not necessarily make the task easier to learn.
Hierarchical Policy Learning is Sensitive to Goal Space Design
May 04, 2019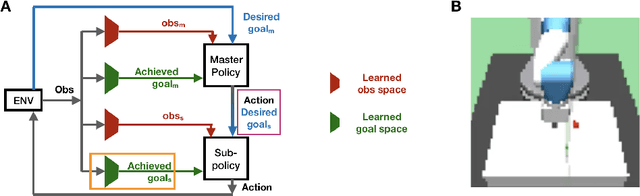
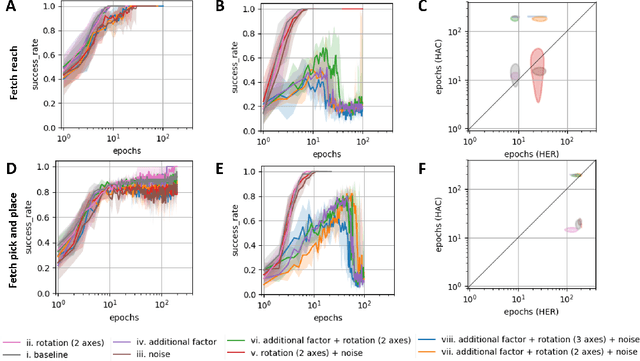


Hierarchy in reinforcement learning agents allows for control at multiple time scales yielding improved sample efficiency, the ability to deal with long time horizons and transferability of sub-policies to tasks outside the training distribution. It is often implemented as a master policy providing goals to a sub-policy. Ideally, we would like the goal-spaces to be learned, however, properties of optimal goal spaces still remain unknown and consequently there is no method yet to learn optimal goal spaces. Motivated by this, we systematically analyze how various modifications to the ground-truth goal-space affect learning in hierarchical models with the aim of identifying important properties of optimal goal spaces. Our results show that, while rotation of ground-truth goal spaces and noise had no effect, having additional unnecessary factors significantly impaired learning in hierarchical models.
Multifunctionality in embodied agents: Three levels of neural reuse
May 16, 2018
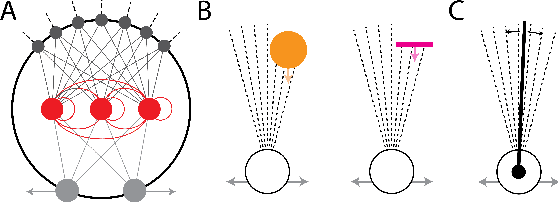
The brain in conjunction with the body is able to adapt to new environments and perform multiple behaviors through reuse of neural resources and transfer of existing behavioral traits. Although mechanisms that underlie this ability are not well understood, they are largely attributed to neuromodulation. In this work, we demonstrate that an agent can be multifunctional using the same sensory and motor systems across behaviors, in the absence of modulatory mechanisms. Further, we lay out the different levels at which neural reuse can occur through a dynamical filtering of the brain-body-environment system's operation: structural network, autonomous dynamics, and transient dynamics. Notably, transient dynamics reuse could only be explained by studying the brain-body-environment system as a whole and not just the brain. The multifunctional agent we present here demonstrates neural reuse at all three levels.