 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Training Flexible Robots using Deep Reinforcement Learning
Jul 13, 2019



The use of robotics in controlled environments has flourished over the last several decades and training robots to perform tasks using control strategies developed from dynamical models of their hardware have proven very effective. However, in many real-world settings, the uncertainties of the environment, the safety requirements and generalized capabilities that are expected of robots make rigid industrial robots unsuitable. This created great research interest into developing control strategies for flexible robot hardware for which building dynamical models are challenging. In this paper, inspired by the success of deep reinforcement learning (DRL) in other areas, we systematically study the efficacy of policy search methods using DRL in training flexible robots. Our results indicate that DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility. We also note that DRL using Deep Deterministic Policy Gradients can be sensitive to the choice of sensors and adding more informative sensors does not necessarily make the task easier to learn.
Collaborative Evolutionary Reinforcement Learning
May 06, 2019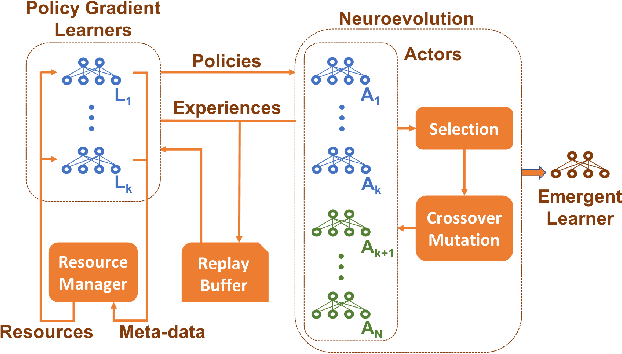
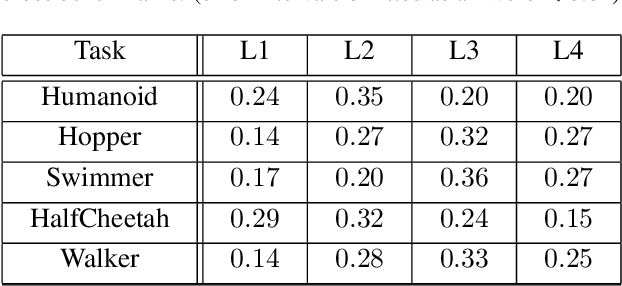
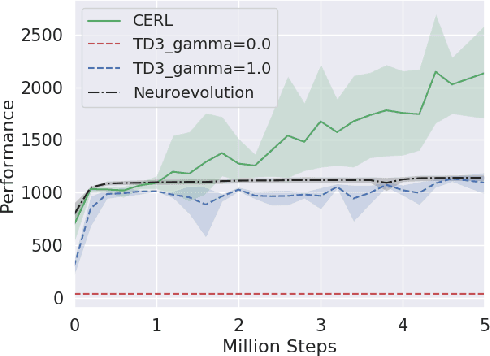
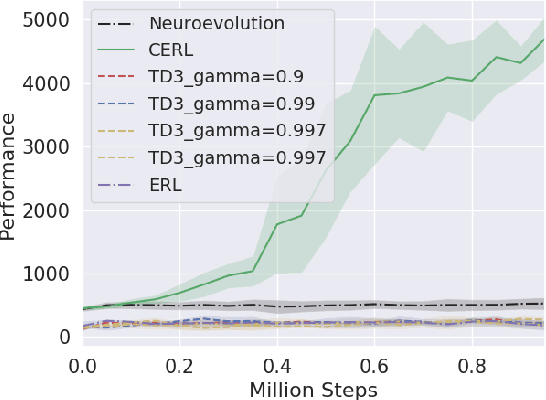
Deep reinforcement learning algorithms have been successfully applied to a range of challenging control tasks. However, these methods typically struggle with achieving effective exploration and are extremely sensitive to the choice of hyperparameters. One reason is that most approaches use a noisy version of their operating policy to explore - thereby limiting the range of exploration. In this paper, we introduce Collaborative Evolutionary Reinforcement Learning (CERL), a scalable framework that comprises a portfolio of policies that simultaneously explore and exploit diverse regions of the solution space. A collection of learners - typically proven algorithms like TD3 - optimize over varying time-horizons leading to this diverse portfolio. All learners contribute to and use a shared replay buffer to achieve greater sample efficiency. Computational resources are dynamically distributed to favor the best learners as a form of online algorithm selection. Neuroevolution binds this entire process to generate a single emergent learner that exceeds the capabilities of any individual learner. Experiments in a range of continuous control benchmarks demonstrate that the emergent learner significantly outperforms its composite learners while remaining overall more sample-efficient - notably solving the Mujoco Humanoid benchmark where all of its composite learners (TD3) fail entirely in isolation.
Hierarchical Policy Learning is Sensitive to Goal Space Design
May 04, 2019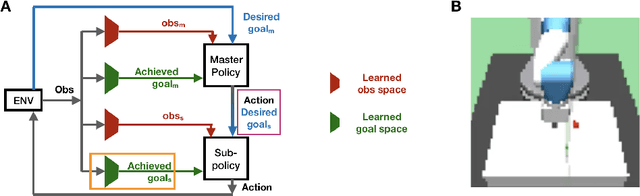
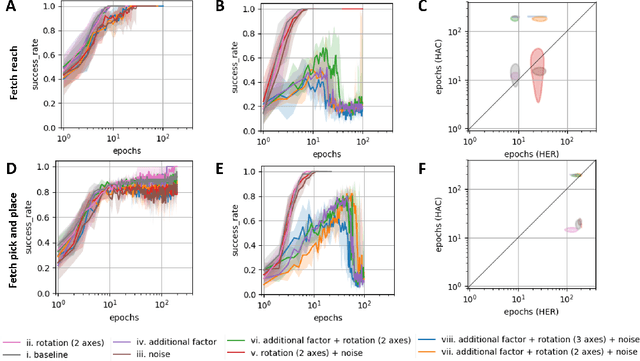


Hierarchy in reinforcement learning agents allows for control at multiple time scales yielding improved sample efficiency, the ability to deal with long time horizons and transferability of sub-policies to tasks outside the training distribution. It is often implemented as a master policy providing goals to a sub-policy. Ideally, we would like the goal-spaces to be learned, however, properties of optimal goal spaces still remain unknown and consequently there is no method yet to learn optimal goal spaces. Motivated by this, we systematically analyze how various modifications to the ground-truth goal-space affect learning in hierarchical models with the aim of identifying important properties of optimal goal spaces. Our results show that, while rotation of ground-truth goal spaces and noise had no effect, having additional unnecessary factors significantly impaired learning in hierarchical models.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
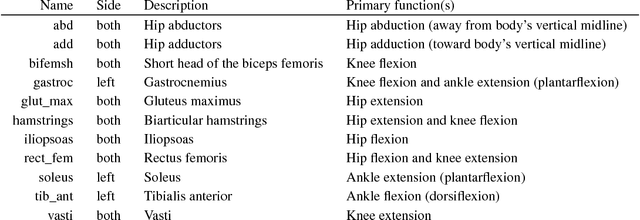
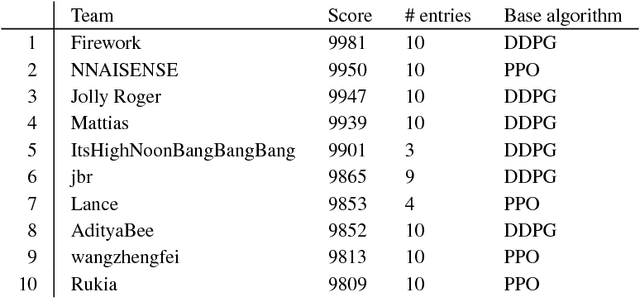

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.