 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Dataset for Learning to Intervene in Online Hate Speech
Sep 10, 2019
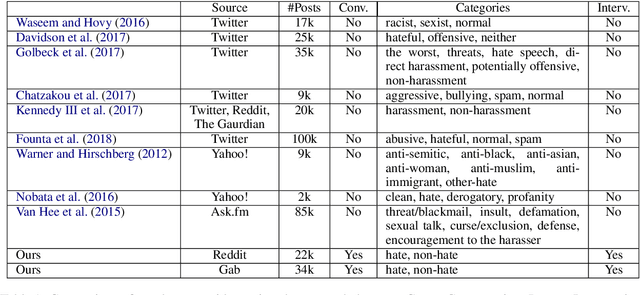


Countering online hate speech is a critical yet challenging task, but one which can be aided by the use of Natural Language Processing (NLP) techniques. Previous research has primarily focused on the development of NLP methods to automatically and effectively detect online hate speech while disregarding further action needed to calm and discourage individuals from using hate speech in the future. In addition, most existing hate speech datasets treat each post as an isolated instance, ignoring the conversational context. In this paper, we propose a novel task of generative hate speech intervention, where the goal is to automatically generate responses to intervene during online conversations that contain hate speech. As a part of this work, we introduce two fully-labeled large-scale hate speech intervention datasets collected from Gab and Reddit. These datasets provide conversation segments, hate speech labels, as well as intervention responses written by Mechanical Turk Workers. In this paper, we also analyze the datasets to understand the common intervention strategies and explore the performance of common automatic response generation methods on these new datasets to provide a benchmark for future research.
Collaborative Evolutionary Reinforcement Learning
May 06, 2019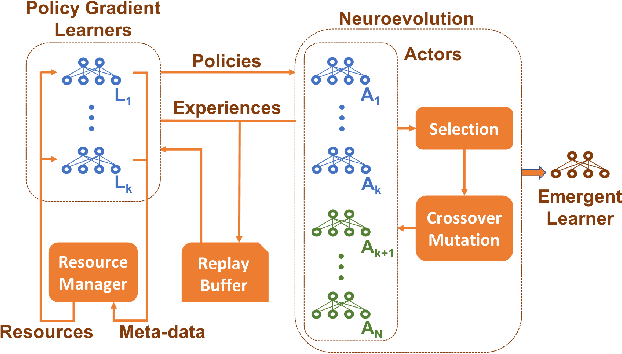
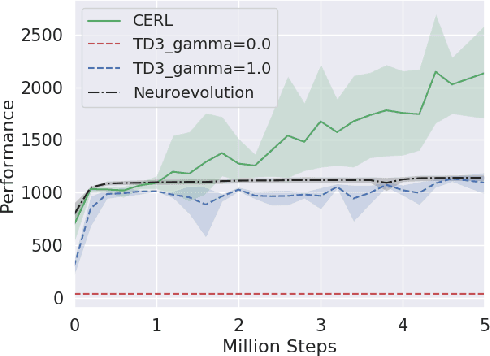
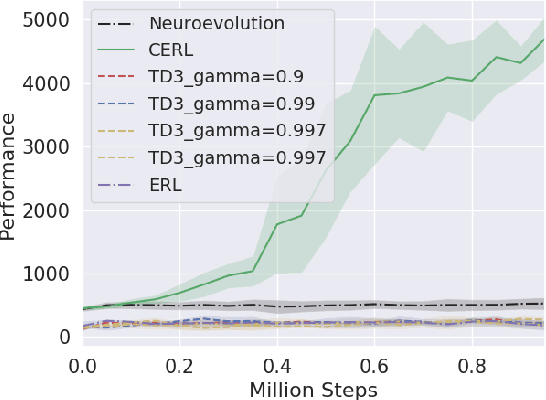
Deep reinforcement learning algorithms have been successfully applied to a range of challenging control tasks. However, these methods typically struggle with achieving effective exploration and are extremely sensitive to the choice of hyperparameters. One reason is that most approaches use a noisy version of their operating policy to explore - thereby limiting the range of exploration. In this paper, we introduce Collaborative Evolutionary Reinforcement Learning (CERL), a scalable framework that comprises a portfolio of policies that simultaneously explore and exploit diverse regions of the solution space. A collection of learners - typically proven algorithms like TD3 - optimize over varying time-horizons leading to this diverse portfolio. All learners contribute to and use a shared replay buffer to achieve greater sample efficiency. Computational resources are dynamically distributed to favor the best learners as a form of online algorithm selection. Neuroevolution binds this entire process to generate a single emergent learner that exceeds the capabilities of any individual learner. Experiments in a range of continuous control benchmarks demonstrate that the emergent learner significantly outperforms its composite learners while remaining overall more sample-efficient - notably solving the Mujoco Humanoid benchmark where all of its composite learners (TD3) fail entirely in isolation.
Few-shot NLG with Pre-trained Language Model
Apr 21, 2019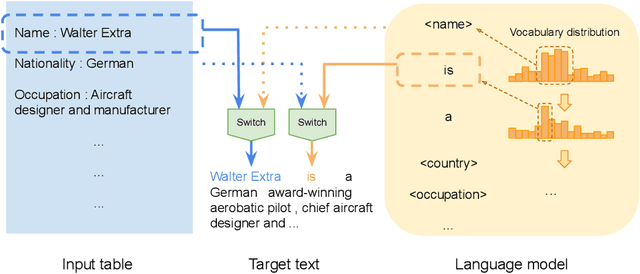

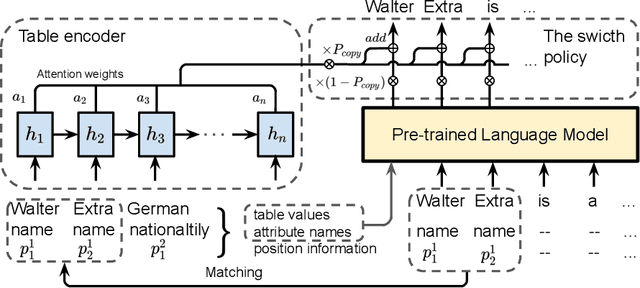

Natural language generation (NLG) from structured data or knowledge is essential for many NLP research areas. While previous neural-based end-to-end approaches have made significant progress on several benchmarks, their data-hungry nature makes them hard to be widely adopted for real-world applications. Hence, in this work, we propose the new task of few-shot natural language generation. Motivated by how humans tend to summarize tabulated data, we propose a simple yet effective approach and show that it not only demonstrates strong performance but also provides good generalization across domains. Design on model architecture is based on two aspects: content selection/copying from input data, and language modeling to compose coherent sentences, which can be acquired from prior knowledge. Accordingly, we employ a pre-trained domain-independent language model to serve as the prior, while the content selection/copying can be learned with only a few in-domain training instances, thus attaining the few-shot learning objective. To demonstrate that our approach generalizes across domains, we curated table-to-text data from multiple domains. With just 200 training samples, across all domains, our approach outperforms the strongest baseline by an average of over 8.0 BLEU points. We will make our code and data publicly available.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
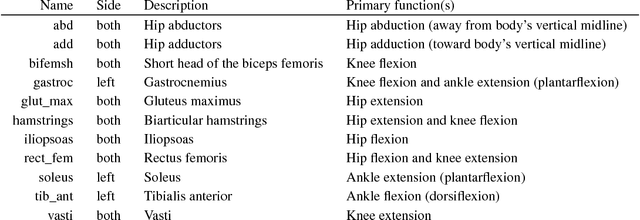
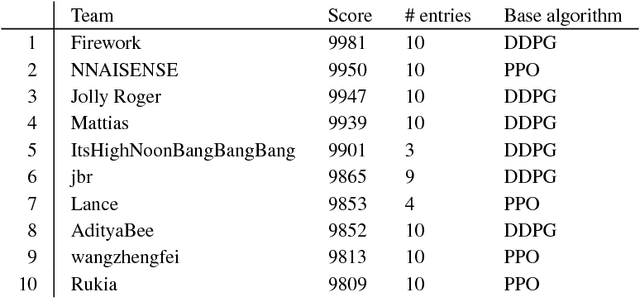

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.