 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot NLG with Pre-trained Language Model
Apr 21, 2019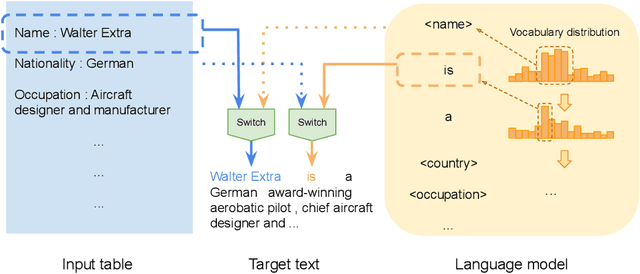

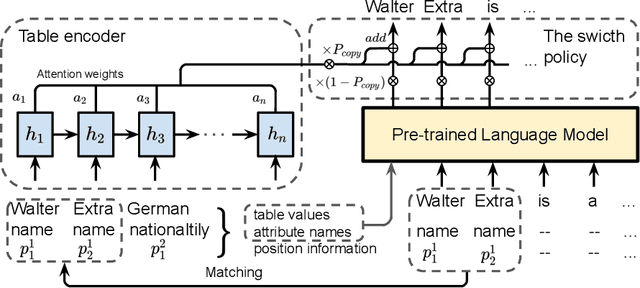

Natural language generation (NLG) from structured data or knowledge is essential for many NLP research areas. While previous neural-based end-to-end approaches have made significant progress on several benchmarks, their data-hungry nature makes them hard to be widely adopted for real-world applications. Hence, in this work, we propose the new task of few-shot natural language generation. Motivated by how humans tend to summarize tabulated data, we propose a simple yet effective approach and show that it not only demonstrates strong performance but also provides good generalization across domains. Design on model architecture is based on two aspects: content selection/copying from input data, and language modeling to compose coherent sentences, which can be acquired from prior knowledge. Accordingly, we employ a pre-trained domain-independent language model to serve as the prior, while the content selection/copying can be learned with only a few in-domain training instances, thus attaining the few-shot learning objective. To demonstrate that our approach generalizes across domains, we curated table-to-text data from multiple domains. With just 200 training samples, across all domains, our approach outperforms the strongest baseline by an average of over 8.0 BLEU points. We will make our code and data publicly available.