 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Internet Quality Estimation using Self-Tuning Kernel Regression
Nov 04, 2023



Modeling and estimation for spatial data are ubiquitous in real life, frequently appearing in weather forecasting, pollution detection, and agriculture. Spatial data analysis often involves processing datasets of enormous scale. In this work, we focus on large-scale internet-quality open datasets from Ookla. We look into estimating mobile (cellular) internet quality at the scale of a state in the United States. In particular, we aim to conduct estimation based on highly {\it imbalanced} data: Most of the samples are concentrated in limited areas, while very few are available in the rest, posing significant challenges to modeling efforts. We propose a new adaptive kernel regression approach that employs self-tuning kernels to alleviate the adverse effects of data imbalance in this problem. Through comparative experimentation on two distinct mobile network measurement datasets, we demonstrate that the proposed self-tuning kernel regression method produces more accurate predictions, with the potential to be applied in other applications.
Towards Understanding Gender Bias in Relation Extraction
Nov 09, 2019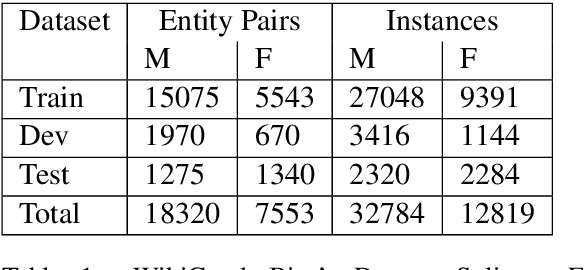
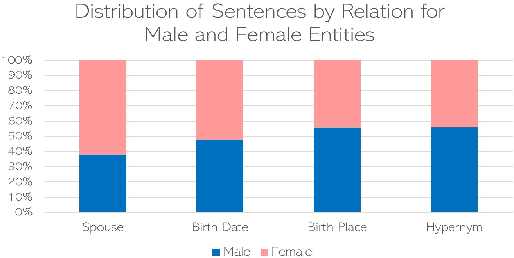
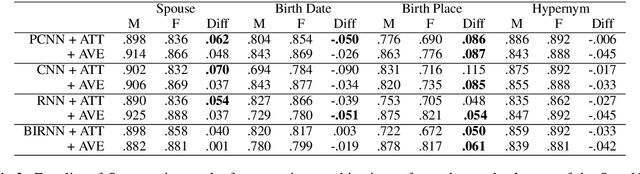
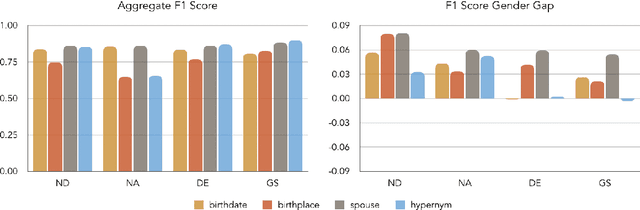
Recent developments in Neural Relation Extraction (NRE) have made significant strides towards Automated Knowledge Base Construction (AKBC). While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to our knowledge to evaluate social biases in NRE systems. We create WikiGenderBias, a distantly supervised dataset with a human annotated test set. WikiGenderBias has sentences specifically curated to analyze gender bias in relation extraction systems. We use WikiGenderBias to evaluate systems for bias and find that NRE systems exhibit gender biased predictions and lay groundwork for future evaluation of bias in NRE. We also analyze how name anonymization, hard debiasing for word embeddings, and counterfactual data augmentation affect gender bias in predictions and performance.
A Benchmark Dataset for Learning to Intervene in Online Hate Speech
Sep 10, 2019
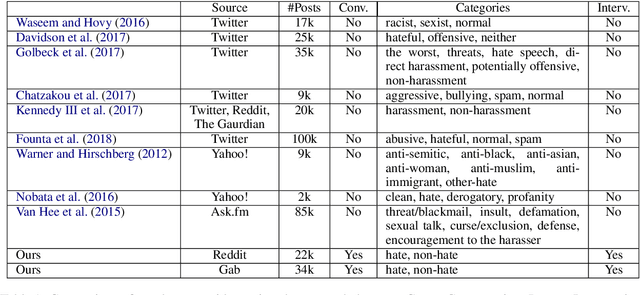


Countering online hate speech is a critical yet challenging task, but one which can be aided by the use of Natural Language Processing (NLP) techniques. Previous research has primarily focused on the development of NLP methods to automatically and effectively detect online hate speech while disregarding further action needed to calm and discourage individuals from using hate speech in the future. In addition, most existing hate speech datasets treat each post as an isolated instance, ignoring the conversational context. In this paper, we propose a novel task of generative hate speech intervention, where the goal is to automatically generate responses to intervene during online conversations that contain hate speech. As a part of this work, we introduce two fully-labeled large-scale hate speech intervention datasets collected from Gab and Reddit. These datasets provide conversation segments, hate speech labels, as well as intervention responses written by Mechanical Turk Workers. In this paper, we also analyze the datasets to understand the common intervention strategies and explore the performance of common automatic response generation methods on these new datasets to provide a benchmark for future research.
Mitigating Gender Bias in Natural Language Processing: Literature Review
Jun 21, 2019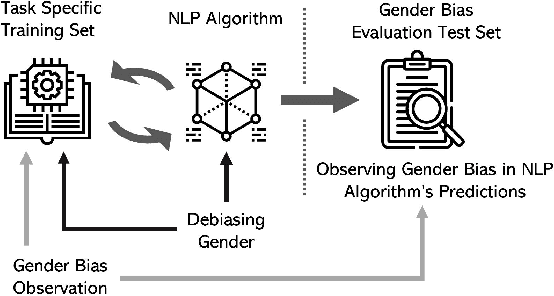


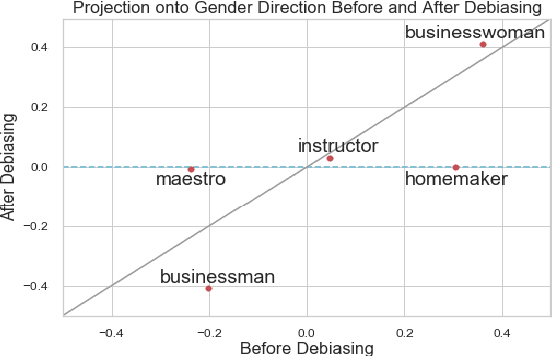
As Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
Learning to Decipher Hate Symbols
Apr 04, 2019
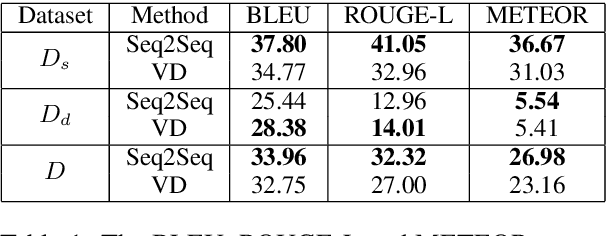
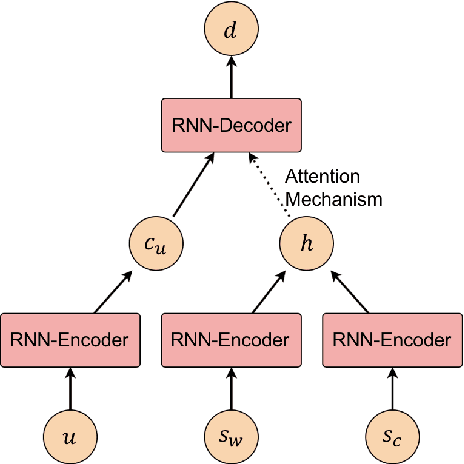
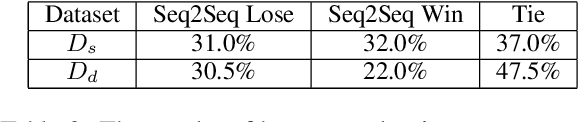
Existing computational models to understand hate speech typically frame the problem as a simple classification task, bypassing the understanding of hate symbols (e.g., 14 words, kigy) and their secret connotations. In this paper, we propose a novel task of deciphering hate symbols. To do this, we leverage the Urban Dictionary and collected a new, symbol-rich Twitter corpus of hate speech. We investigate neural network latent context models for deciphering hate symbols. More specifically, we study Sequence-to-Sequence models and show how they are able to crack the ciphers based on context. Furthermore, we propose a novel Variational Decipher and show how it can generalize better to unseen hate symbols in a more challenging testing setting.
SafeRoute: Learning to Navigate Streets Safely in an Urban Environment
Nov 03, 2018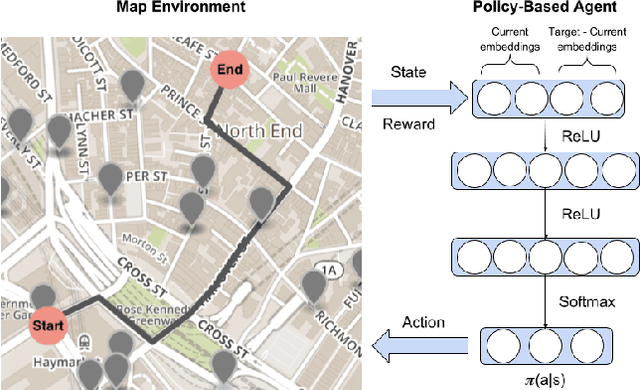
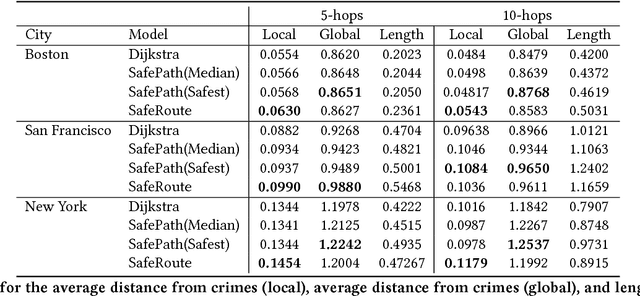
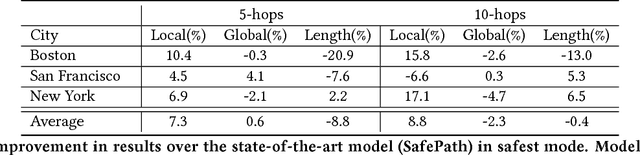
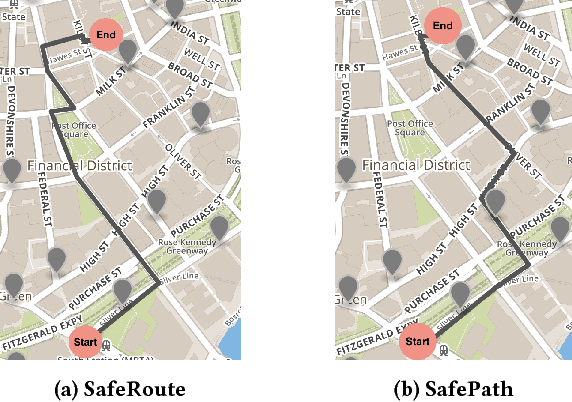
Recent studies show that 85% of women have changed their traveled route to avoid harassment and assault. Despite this, current mapping tools do not empower users with information to take charge of their personal safety. We propose SafeRoute, a novel solution to the problem of navigating cities and avoiding street harassment and crime. Unlike other street navigation applications, SafeRoute introduces a new type of path generation via deep reinforcement learning. This enables us to successfully optimize for multi-criteria path-finding and incorporate representation learning within our framework. Our agent learns to pick favorable streets to create a safe and short path with a reward function that incorporates safety and efficiency. Given access to recent crime reports in many urban cities, we train our model for experiments in Boston, New York, and San Francisco. We test our model on areas of these cities, specifically the populated downtown regions where tourists and those unfamiliar with the streets walk. We evaluate SafeRoute and successfully improve over state-of-the-art methods by up to 17% in local average distance from crimes while decreasing path length by up to 7%.
Hierarchical CVAE for Fine-Grained Hate Speech Classification
Aug 31, 2018
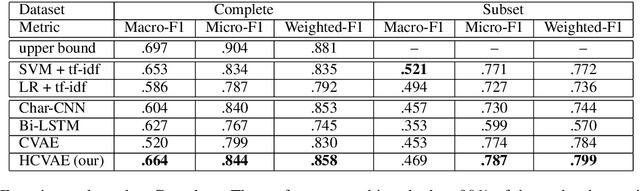
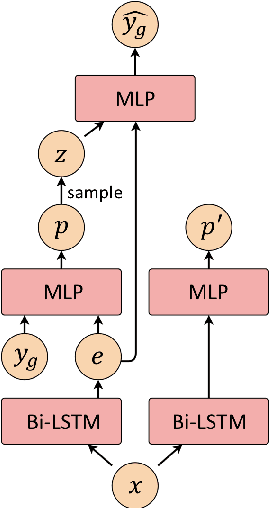
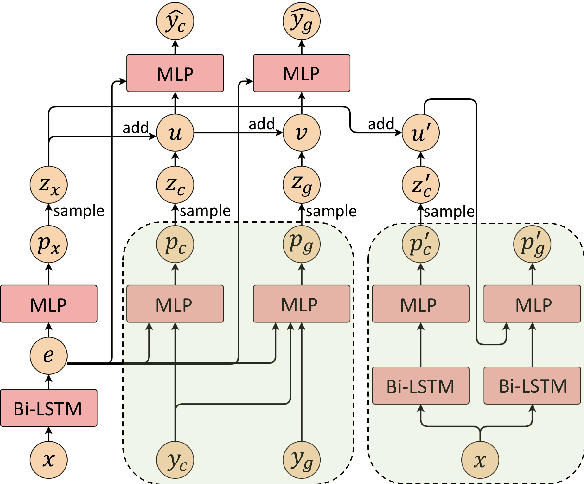
Existing work on automated hate speech detection typically focuses on binary classification or on differentiating among a small set of categories. In this paper, we propose a novel method on a fine-grained hate speech classification task, which focuses on differentiating among 40 hate groups of 13 different hate group categories. We first explore the Conditional Variational Autoencoder (CVAE) as a discriminative model and then extend it to a hierarchical architecture to utilize the additional hate category information for more accurate prediction. Experimentally, we show that incorporating the hate category information for training can significantly improve the classification performance and our proposed model outperforms commonly-used discriminative models.
Hate Lingo: A Target-based Linguistic Analysis of Hate Speech in Social Media
Apr 11, 2018



While social media empowers freedom of expression and individual voices, it also enables anti-social behavior, online harassment, cyberbullying, and hate speech. In this paper, we deepen our understanding of online hate speech by focusing on a largely neglected but crucial aspect of hate speech -- its target: either "directed" towards a specific person or entity, or "generalized" towards a group of people sharing a common protected characteristic. We perform the first linguistic and psycholinguistic analysis of these two forms of hate speech and reveal the presence of interesting markers that distinguish these types of hate speech. Our analysis reveals that Directed hate speech, in addition to being more personal and directed, is more informal, angrier, and often explicitly attacks the target (via name calling) with fewer analytic words and more words suggesting authority and influence. Generalized hate speech, on the other hand, is dominated by religious hate, is characterized by the use of lethal words such as murder, exterminate, and kill; and quantity words such as million and many. Altogether, our work provides a data-driven analysis of the nuances of online-hate speech that enables not only a deepened understanding of hate speech and its social implications but also its detection.