 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
May 03, 2023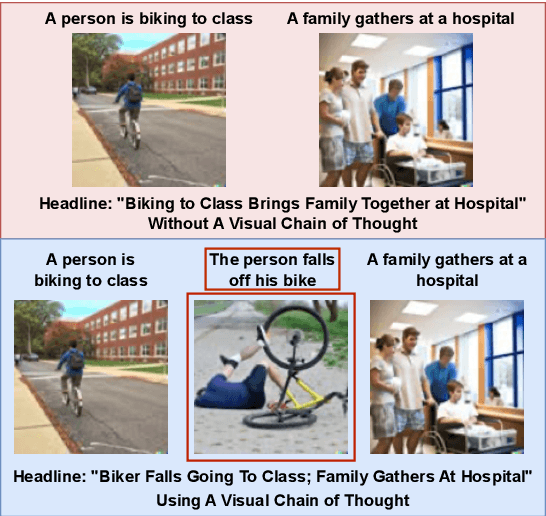

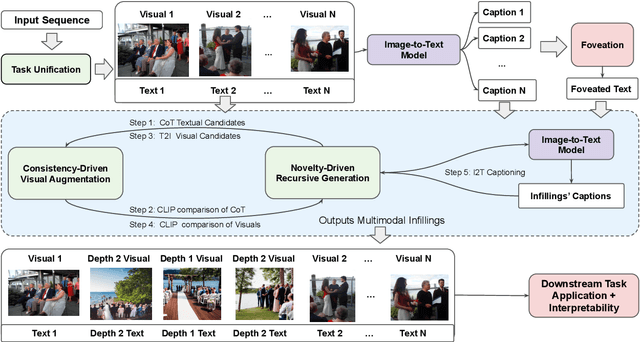
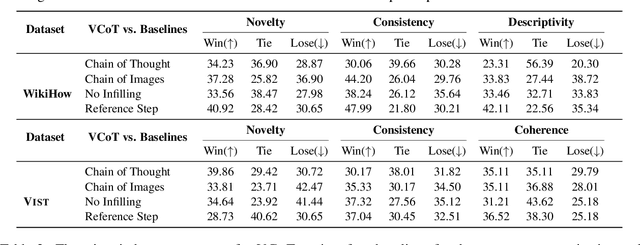
Recent advances in large language models elicit reasoning in a chain of thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain of thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain of thought baselines, which can be used to enhance downstream performance.
Investigating African-American Vernacular English in Transformer-Based Text Generation
Oct 29, 2020

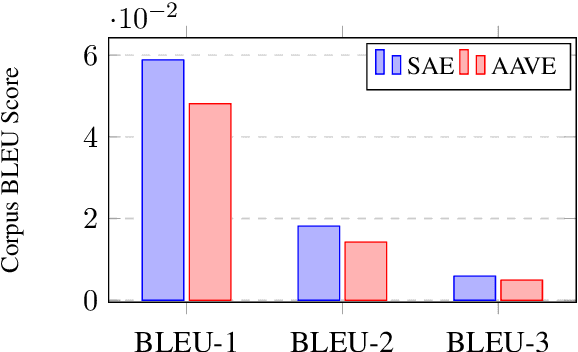
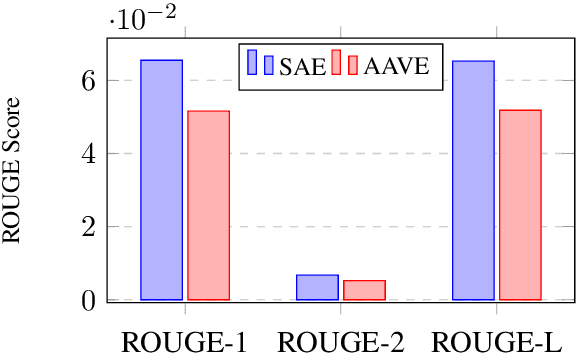
The growth of social media has encouraged the written use of African American Vernacular English (AAVE), which has traditionally been used only in oral contexts. However, NLP models have historically been developed using dominant English varieties, such as Standard American English (SAE), due to text corpora availability. We investigate the performance of GPT-2 on AAVE text by creating a dataset of intent-equivalent parallel AAVE/SAE tweet pairs, thereby isolating syntactic structure and AAVE- or SAE-specific language for each pair. We evaluate each sample and its GPT-2 generated text with pretrained sentiment classifiers and find that while AAVE text results in more classifications of negative sentiment than SAE, the use of GPT-2 generally increases occurrences of positive sentiment for both. Additionally, we conduct human evaluation of AAVE and SAE text generated with GPT-2 to compare contextual rigor and overall quality.
Evaluating Transformer-Based Multilingual Text Classification
Apr 30, 2020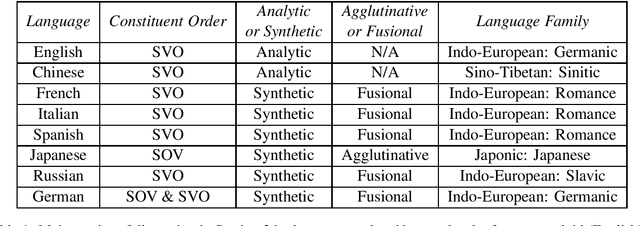
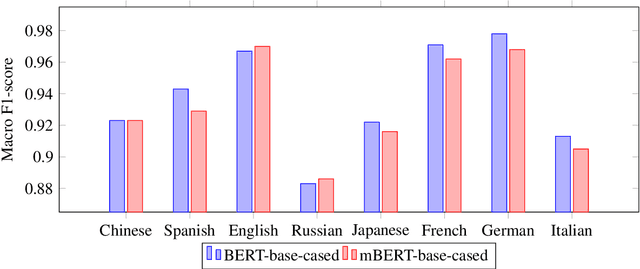
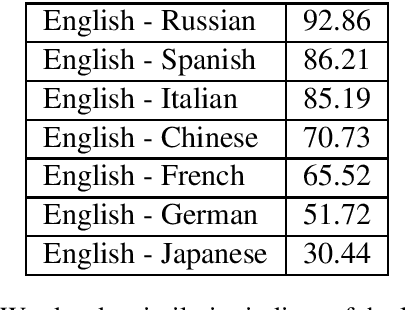
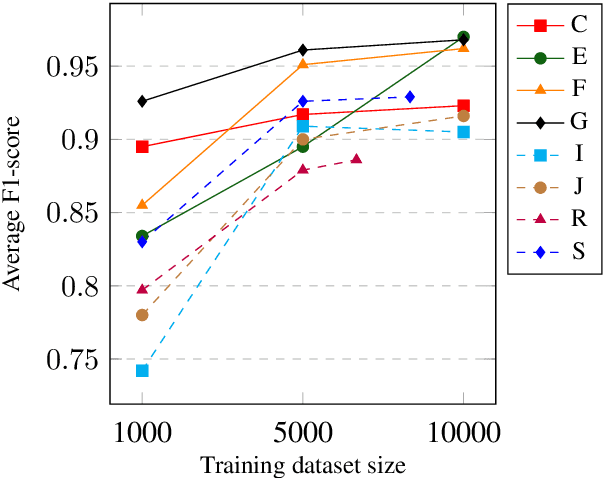
As NLP tools become ubiquitous in today's technological landscape, they are increasingly applied to languages with a variety of typological structures. However, NLP research does not focus primarily on typological differences in its analysis of state-of-the-art language models. As a result, NLP tools perform unequally across languages with different syntactic and morphological structures. Through a detailed discussion of word order typology, morphological typology, and comparative linguistics, we identify which variables most affect language modeling efficacy; in addition, we calculate word order and morphological similarity indices to aid our empirical study. We then use this background to support our analysis of an experiment we conduct using multi-class text classification on eight languages and eight models.
Towards Understanding Gender Bias in Relation Extraction
Nov 09, 2019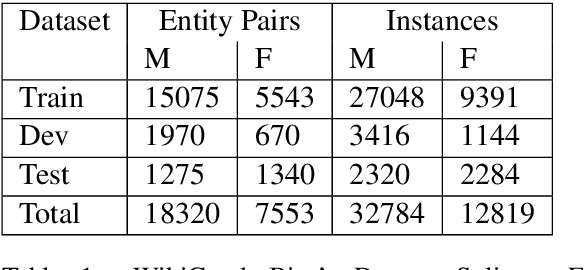
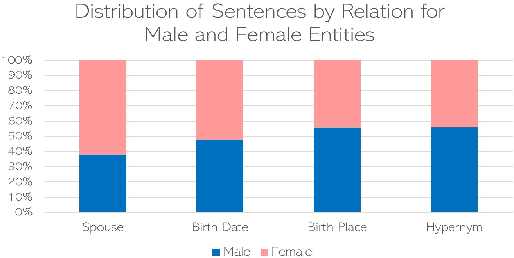
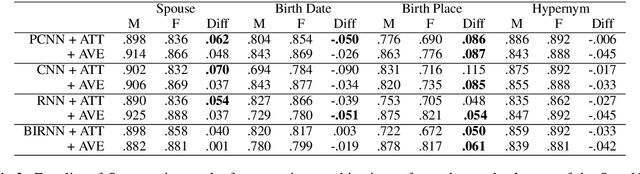
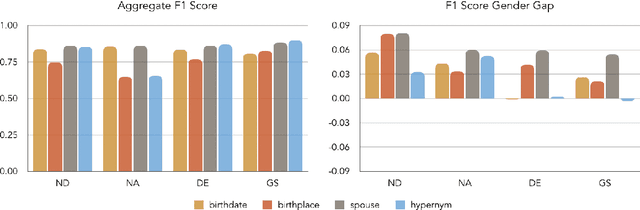
Recent developments in Neural Relation Extraction (NRE) have made significant strides towards Automated Knowledge Base Construction (AKBC). While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to our knowledge to evaluate social biases in NRE systems. We create WikiGenderBias, a distantly supervised dataset with a human annotated test set. WikiGenderBias has sentences specifically curated to analyze gender bias in relation extraction systems. We use WikiGenderBias to evaluate systems for bias and find that NRE systems exhibit gender biased predictions and lay groundwork for future evaluation of bias in NRE. We also analyze how name anonymization, hard debiasing for word embeddings, and counterfactual data augmentation affect gender bias in predictions and performance.
Mitigating Gender Bias in Natural Language Processing: Literature Review
Jun 21, 2019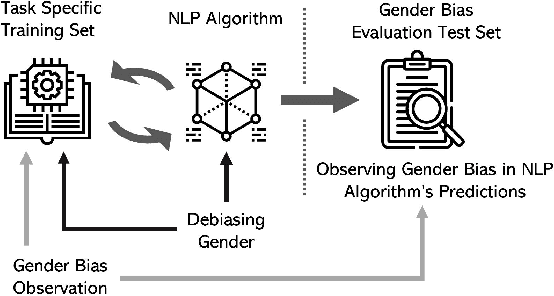


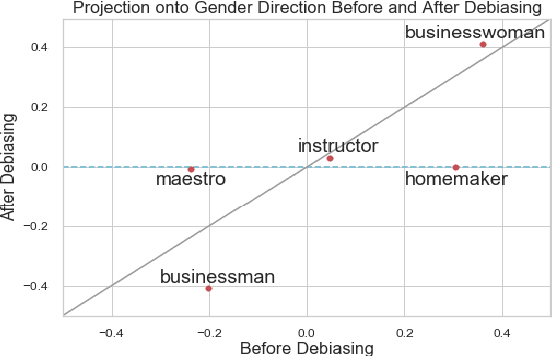
As Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.