 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Gender-Seniority Compound Bias in Natural Language Generation
May 19, 2022

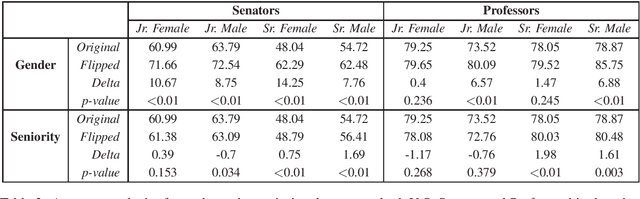

Women are often perceived as junior to their male counterparts, even within the same job titles. While there has been significant progress in the evaluation of gender bias in natural language processing (NLP), existing studies seldom investigate how biases toward gender groups change when compounded with other societal biases. In this work, we investigate how seniority impacts the degree of gender bias exhibited in pretrained neural generation models by introducing a novel framework for probing compound bias. We contribute a benchmark robustness-testing dataset spanning two domains, U.S. senatorship and professorship, created using a distant-supervision method. Our dataset includes human-written text with underlying ground truth and paired counterfactuals. We then examine GPT-2 perplexity and the frequency of gendered language in generated text. Our results show that GPT-2 amplifies bias by considering women as junior and men as senior more often than the ground truth in both domains. These results suggest that NLP applications built using GPT-2 may harm women in professional capacities.
Investigating African-American Vernacular English in Transformer-Based Text Generation
Oct 29, 2020

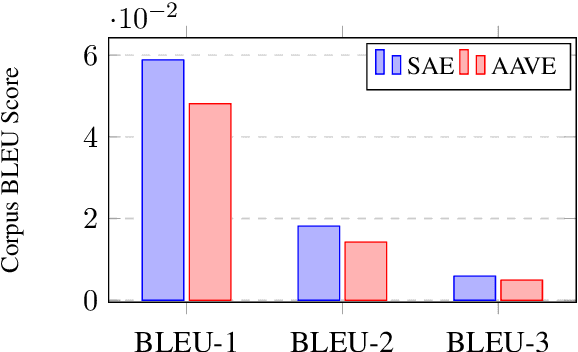
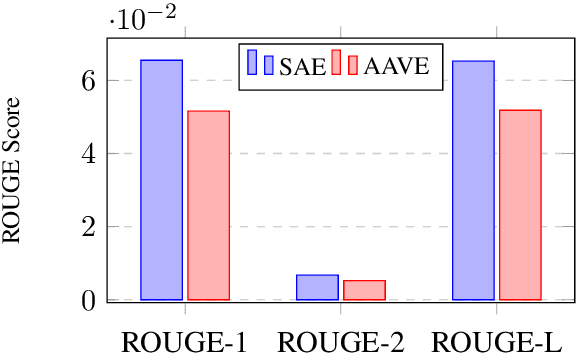
The growth of social media has encouraged the written use of African American Vernacular English (AAVE), which has traditionally been used only in oral contexts. However, NLP models have historically been developed using dominant English varieties, such as Standard American English (SAE), due to text corpora availability. We investigate the performance of GPT-2 on AAVE text by creating a dataset of intent-equivalent parallel AAVE/SAE tweet pairs, thereby isolating syntactic structure and AAVE- or SAE-specific language for each pair. We evaluate each sample and its GPT-2 generated text with pretrained sentiment classifiers and find that while AAVE text results in more classifications of negative sentiment than SAE, the use of GPT-2 generally increases occurrences of positive sentiment for both. Additionally, we conduct human evaluation of AAVE and SAE text generated with GPT-2 to compare contextual rigor and overall quality.
Evaluating Transformer-Based Multilingual Text Classification
Apr 30, 2020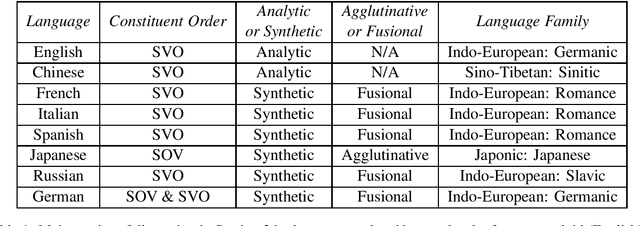
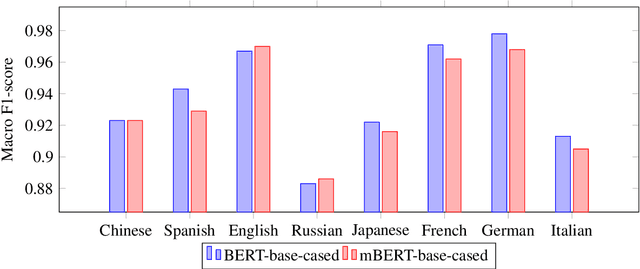
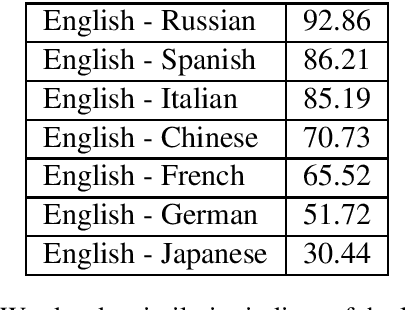
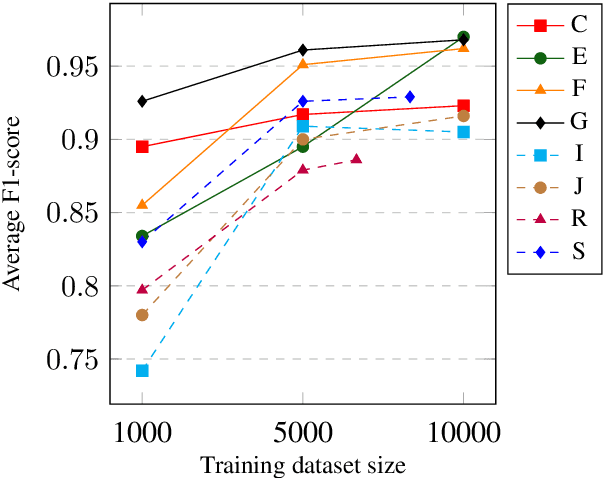
As NLP tools become ubiquitous in today's technological landscape, they are increasingly applied to languages with a variety of typological structures. However, NLP research does not focus primarily on typological differences in its analysis of state-of-the-art language models. As a result, NLP tools perform unequally across languages with different syntactic and morphological structures. Through a detailed discussion of word order typology, morphological typology, and comparative linguistics, we identify which variables most affect language modeling efficacy; in addition, we calculate word order and morphological similarity indices to aid our empirical study. We then use this background to support our analysis of an experiment we conduct using multi-class text classification on eight languages and eight models.