 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction
May 23, 2023Despite constituting 65% of all internet traffic in 2023, video content is underrepresented in generative AI research. Meanwhile, recent large language models (LLMs) have become increasingly integrated with capabilities in the visual modality. Integrating video with LLMs is a natural next step, so how can this gap be bridged? To advance video reasoning, we propose a new research direction of VideoCOT on video keyframes, which leverages the multimodal generative abilities of vision-language models to enhance video reasoning while reducing the computational complexity of processing hundreds or thousands of frames. We introduce VIP, an inference-time dataset that can be used to evaluate VideoCOT, containing 1) a variety of real-life videos with keyframes and corresponding unstructured and structured scene descriptions, and 2) two new video reasoning tasks: video infilling and scene prediction. We benchmark various vision-language models on VIP, demonstrating the potential to use vision-language models and LLMs to enhance video chain of thought reasoning.
Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
May 03, 2023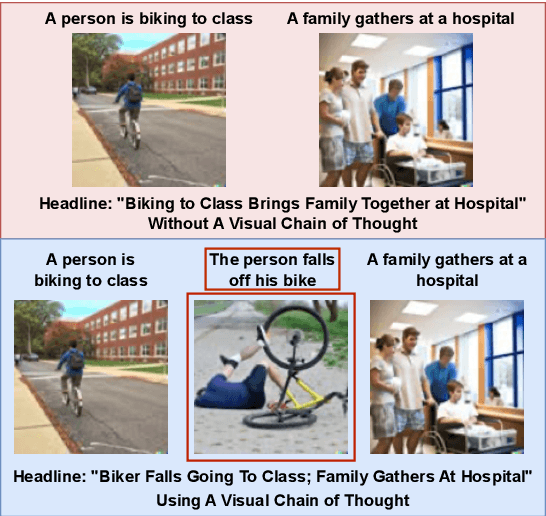

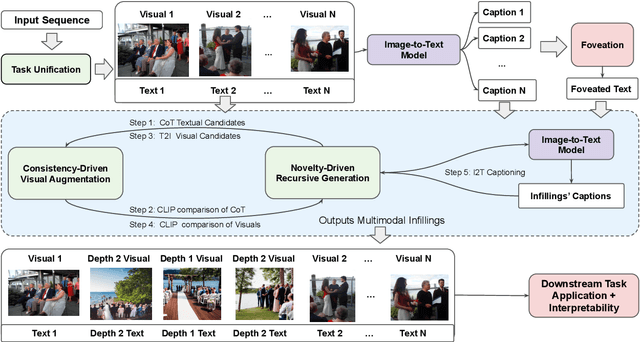
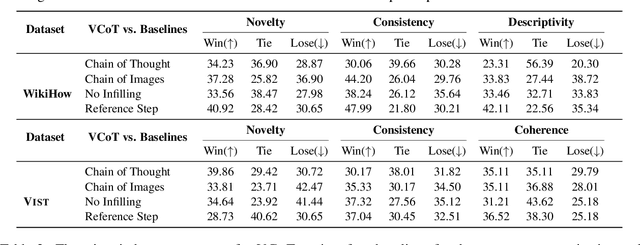
Recent advances in large language models elicit reasoning in a chain of thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain of thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain of thought baselines, which can be used to enhance downstream performance.