 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDDxAgent: A Unified Modular Agent Framework for Explainable Automatic Differential Diagnosis
Feb 26, 2025Differential Diagnosis (DDx) is a fundamental yet complex aspect of clinical decision-making, in which physicians iteratively refine a ranked list of possible diseases based on symptoms, antecedents, and medical knowledge. While recent advances in large language models have shown promise in supporting DDx, existing approaches face key limitations, including single-dataset evaluations, isolated optimization of components, unrealistic assumptions about complete patient profiles, and single-attempt diagnosis. We introduce a Modular Explainable DDx Agent (MEDDxAgent) framework designed for interactive DDx, where diagnostic reasoning evolves through iterative learning, rather than assuming a complete patient profile is accessible. MEDDxAgent integrates three modular components: (1) an orchestrator (DDxDriver), (2) a history taking simulator, and (3) two specialized agents for knowledge retrieval and diagnosis strategy. To ensure robust evaluation, we introduce a comprehensive DDx benchmark covering respiratory, skin, and rare diseases. We analyze single-turn diagnostic approaches and demonstrate the importance of iterative refinement when patient profiles are not available at the outset. Our broad evaluation demonstrates that MEDDxAgent achieves over 10% accuracy improvements in interactive DDx across both large and small LLMs, while offering critical explainability into its diagnostic reasoning process.
PharmacoMatch: Efficient 3D Pharmacophore Screening through Neural Subgraph Matching
Sep 10, 2024
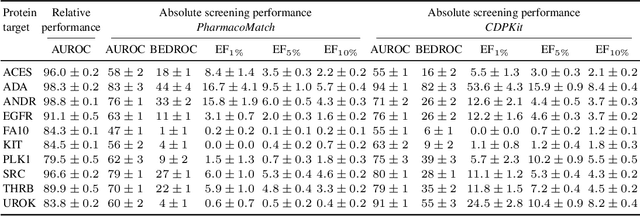
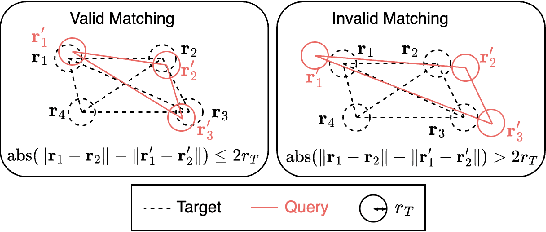

The increasing size of screening libraries poses a significant challenge for the development of virtual screening methods for drug discovery, necessitating a re-evaluation of traditional approaches in the era of big data. Although 3D pharmacophore screening remains a prevalent technique, its application to very large datasets is limited by the computational cost associated with matching query pharmacophores to database ligands. In this study, we introduce PharmacoMatch, a novel contrastive learning approach based on neural subgraph matching. Our method reinterprets pharmacophore screening as an approximate subgraph matching problem and enables efficient querying of conformational databases by encoding query-target relationships in the embedding space. We conduct comprehensive evaluations of the learned representations and benchmark our method on virtual screening datasets in a zero-shot setting. Our findings demonstrate significantly shorter runtimes for pharmacophore matching, offering a promising speed-up for screening very large datasets.
Let's Think Frame by Frame: Evaluating Video Chain of Thought with Video Infilling and Prediction
May 23, 2023Despite constituting 65% of all internet traffic in 2023, video content is underrepresented in generative AI research. Meanwhile, recent large language models (LLMs) have become increasingly integrated with capabilities in the visual modality. Integrating video with LLMs is a natural next step, so how can this gap be bridged? To advance video reasoning, we propose a new research direction of VideoCOT on video keyframes, which leverages the multimodal generative abilities of vision-language models to enhance video reasoning while reducing the computational complexity of processing hundreds or thousands of frames. We introduce VIP, an inference-time dataset that can be used to evaluate VideoCOT, containing 1) a variety of real-life videos with keyframes and corresponding unstructured and structured scene descriptions, and 2) two new video reasoning tasks: video infilling and scene prediction. We benchmark various vision-language models on VIP, demonstrating the potential to use vision-language models and LLMs to enhance video chain of thought reasoning.
Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
May 03, 2023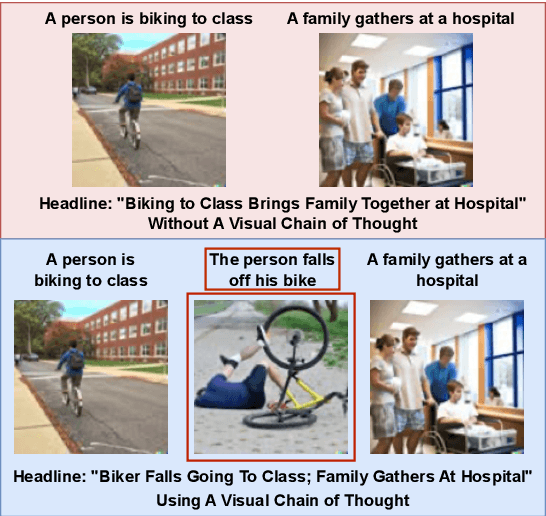

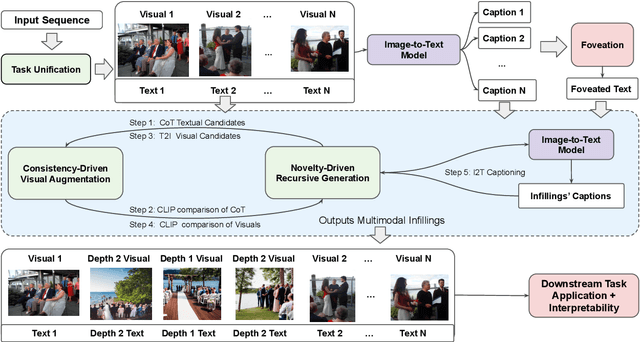
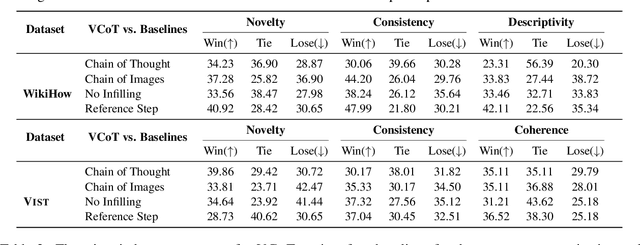
Recent advances in large language models elicit reasoning in a chain of thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain of thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain of thought baselines, which can be used to enhance downstream performance.