 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePharmacoMatch: Efficient 3D Pharmacophore Screening through Neural Subgraph Matching
Sep 10, 2024
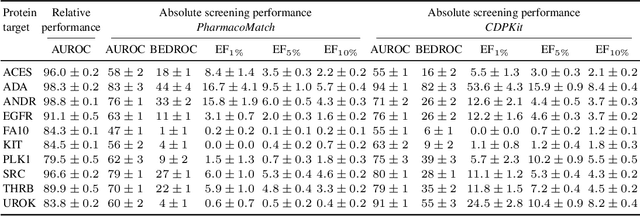
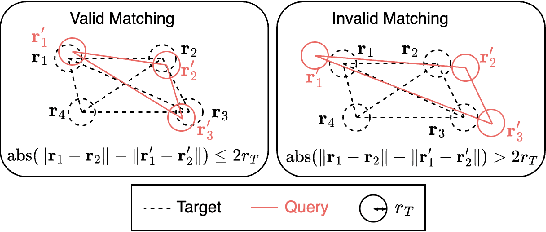

The increasing size of screening libraries poses a significant challenge for the development of virtual screening methods for drug discovery, necessitating a re-evaluation of traditional approaches in the era of big data. Although 3D pharmacophore screening remains a prevalent technique, its application to very large datasets is limited by the computational cost associated with matching query pharmacophores to database ligands. In this study, we introduce PharmacoMatch, a novel contrastive learning approach based on neural subgraph matching. Our method reinterprets pharmacophore screening as an approximate subgraph matching problem and enables efficient querying of conformational databases by encoding query-target relationships in the embedding space. We conduct comprehensive evaluations of the learned representations and benchmark our method on virtual screening datasets in a zero-shot setting. Our findings demonstrate significantly shorter runtimes for pharmacophore matching, offering a promising speed-up for screening very large datasets.