 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluent but Unfeeling: The Emotional Blind Spots of Language Models
Sep 11, 2025The versatility of Large Language Models (LLMs) in natural language understanding has made them increasingly popular in mental health research. While many studies explore LLMs' capabilities in emotion recognition, a critical gap remains in evaluating whether LLMs align with human emotions at a fine-grained level. Existing research typically focuses on classifying emotions into predefined, limited categories, overlooking more nuanced expressions. To address this gap, we introduce EXPRESS, a benchmark dataset curated from Reddit communities featuring 251 fine-grained, self-disclosed emotion labels. Our comprehensive evaluation framework examines predicted emotion terms and decomposes them into eight basic emotions using established emotion theories, enabling a fine-grained comparison. Systematic testing of prevalent LLMs under various prompt settings reveals that accurately predicting emotions that align with human self-disclosed emotions remains challenging. Qualitative analysis further shows that while certain LLMs generate emotion terms consistent with established emotion theories and definitions, they sometimes fail to capture contextual cues as effectively as human self-disclosures. These findings highlight the limitations of LLMs in fine-grained emotion alignment and offer insights for future research aimed at enhancing their contextual understanding.
Large-Scale Analysis of Online Questions Related to Opioid Use Disorder on Reddit
Apr 10, 2025Opioid use disorder (OUD) is a leading health problem that affects individual well-being as well as general public health. Due to a variety of reasons, including the stigma faced by people using opioids, online communities for recovery and support were formed on different social media platforms. In these communities, people share their experiences and solicit information by asking questions to learn about opioid use and recovery. However, these communities do not always contain clinically verified information. In this paper, we study natural language questions asked in the context of OUD-related discourse on Reddit. We adopt transformer-based question detection along with hierarchical clustering across 19 subreddits to identify six coarse-grained categories and 69 fine-grained categories of OUD-related questions. Our analysis uncovers ten areas of information seeking from Reddit users in the context of OUD: drug sales, specific drug-related questions, OUD treatment, drug uses, side effects, withdrawal, lifestyle, drug testing, pain management and others, during the study period of 2018-2021. Our work provides a major step in improving the understanding of OUD-related questions people ask unobtrusively on Reddit. We finally discuss technological interventions and public health harm reduction techniques based on the topics of these questions.
* Accepted to ICWSM 2025
Exposure to Content Written by Large Language Models Can Reduce Stigma Around Opioid Use Disorder in Online Communities
Apr 08, 2025Widespread stigma, both in the offline and online spaces, acts as a barrier to harm reduction efforts in the context of opioid use disorder (OUD). This stigma is prominently directed towards clinically approved medications for addiction treatment (MAT), people with the condition, and the condition itself. Given the potential of artificial intelligence based technologies in promoting health equity, and facilitating empathic conversations, this work examines whether large language models (LLMs) can help abate OUD-related stigma in online communities. To answer this, we conducted a series of pre-registered randomized controlled experiments, where participants read LLM-generated, human-written, or no responses to help seeking OUD-related content in online communities. The experiment was conducted under two setups, i.e., participants read the responses either once (N = 2,141), or repeatedly for 14 days (N = 107). We found that participants reported the least stigmatized attitudes toward MAT after consuming LLM-generated responses under both the setups. This study offers insights into strategies that can foster inclusive online discourse on OUD, e.g., based on our findings LLMs can be used as an education-based intervention to promote positive attitudes and increase people's propensity toward MAT.
Latent Hatred: A Benchmark for Understanding Implicit Hate Speech
Sep 11, 2021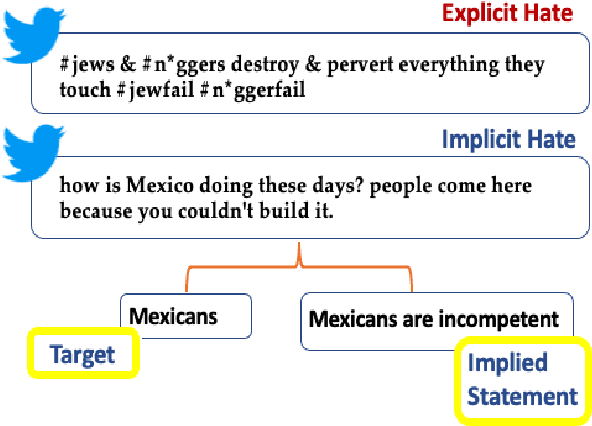
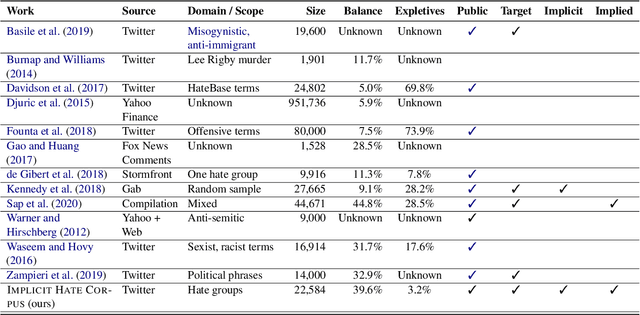
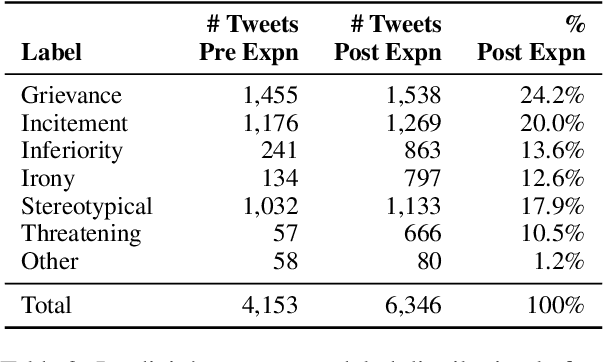

Hate speech has grown significantly on social media, causing serious consequences for victims of all demographics. Despite much attention being paid to characterize and detect discriminatory speech, most work has focused on explicit or overt hate speech, failing to address a more pervasive form based on coded or indirect language. To fill this gap, this work introduces a theoretically-justified taxonomy of implicit hate speech and a benchmark corpus with fine-grained labels for each message and its implication. We present systematic analyses of our dataset using contemporary baselines to detect and explain implicit hate speech, and we discuss key features that challenge existing models. This dataset will continue to serve as a useful benchmark for understanding this multifaceted issue.
Lifelong Learning of Hate Speech Classification on Social Media
Jun 05, 2021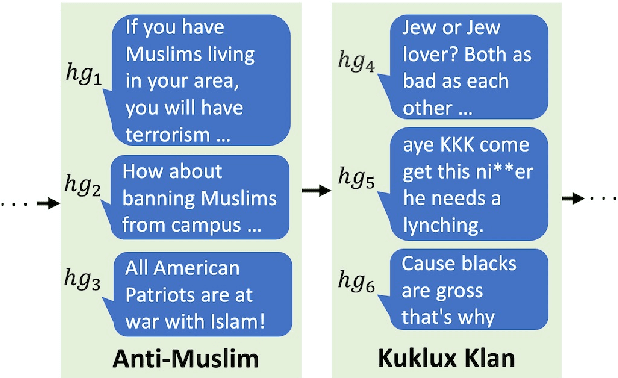
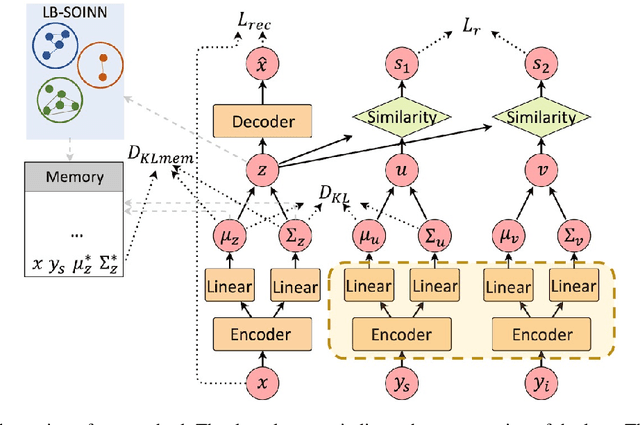
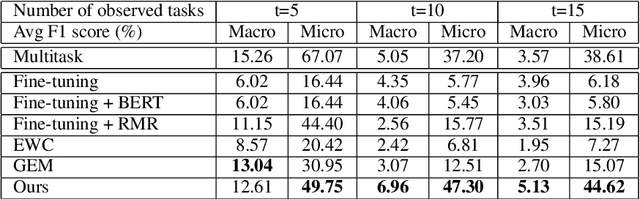
Existing work on automated hate speech classification assumes that the dataset is fixed and the classes are pre-defined. However, the amount of data in social media increases every day, and the hot topics changes rapidly, requiring the classifiers to be able to continuously adapt to new data without forgetting the previously learned knowledge. This ability, referred to as lifelong learning, is crucial for the real-word application of hate speech classifiers in social media. In this work, we propose lifelong learning of hate speech classification on social media. To alleviate catastrophic forgetting, we propose to use Variational Representation Learning (VRL) along with a memory module based on LB-SOINN (Load-Balancing Self-Organizing Incremental Neural Network). Experimentally, we show that combining variational representation learning and the LB-SOINN memory module achieves better performance than the commonly-used lifelong learning techniques.
Towards Understanding Gender Bias in Relation Extraction
Nov 09, 2019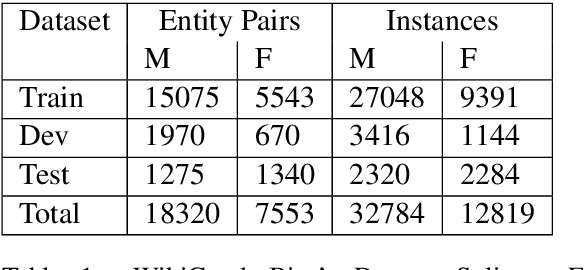
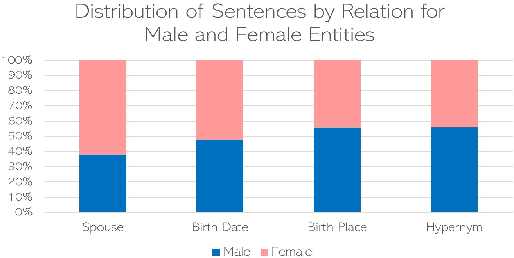
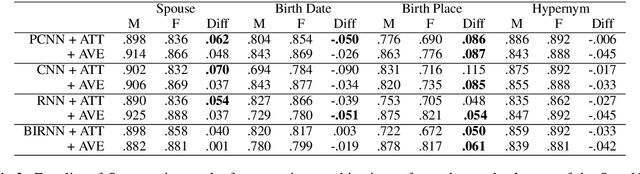
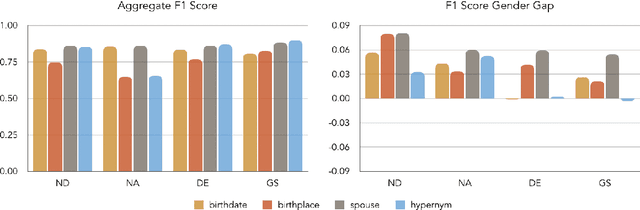
Recent developments in Neural Relation Extraction (NRE) have made significant strides towards Automated Knowledge Base Construction (AKBC). While much attention has been dedicated towards improvements in accuracy, there have been no attempts in the literature to our knowledge to evaluate social biases in NRE systems. We create WikiGenderBias, a distantly supervised dataset with a human annotated test set. WikiGenderBias has sentences specifically curated to analyze gender bias in relation extraction systems. We use WikiGenderBias to evaluate systems for bias and find that NRE systems exhibit gender biased predictions and lay groundwork for future evaluation of bias in NRE. We also analyze how name anonymization, hard debiasing for word embeddings, and counterfactual data augmentation affect gender bias in predictions and performance.
Mitigating Gender Bias in Natural Language Processing: Literature Review
Jun 21, 2019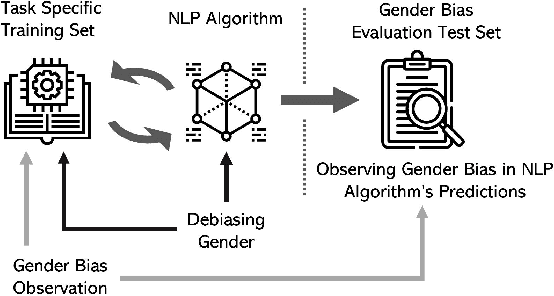


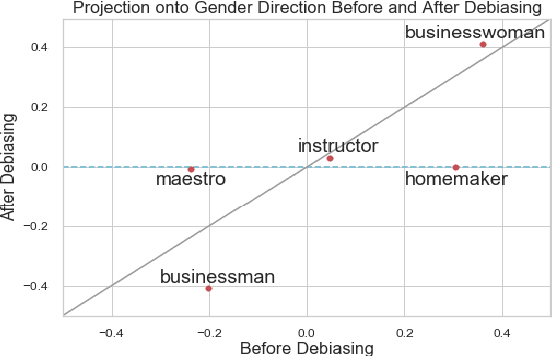
As Natural Language Processing (NLP) and Machine Learning (ML) tools rise in popularity, it becomes increasingly vital to recognize the role they play in shaping societal biases and stereotypes. Although NLP models have shown success in modeling various applications, they propagate and may even amplify gender bias found in text corpora. While the study of bias in artificial intelligence is not new, methods to mitigate gender bias in NLP are relatively nascent. In this paper, we review contemporary studies on recognizing and mitigating gender bias in NLP. We discuss gender bias based on four forms of representation bias and analyze methods recognizing gender bias. Furthermore, we discuss the advantages and drawbacks of existing gender debiasing methods. Finally, we discuss future studies for recognizing and mitigating gender bias in NLP.
Learning to Decipher Hate Symbols
Apr 04, 2019
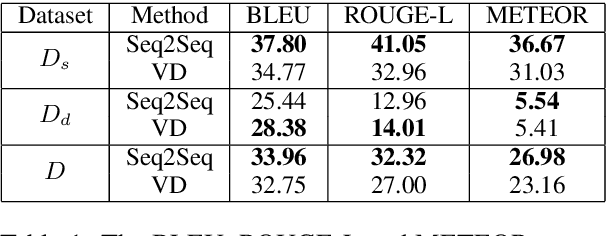
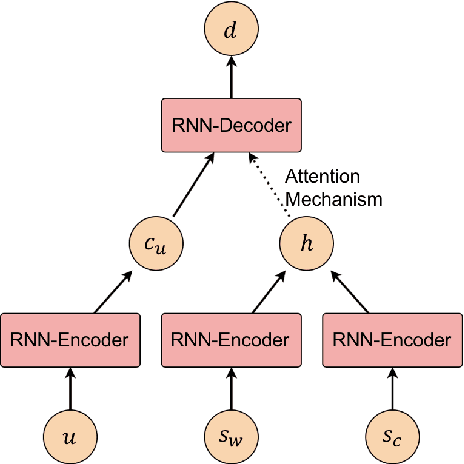
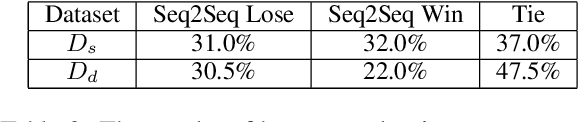
Existing computational models to understand hate speech typically frame the problem as a simple classification task, bypassing the understanding of hate symbols (e.g., 14 words, kigy) and their secret connotations. In this paper, we propose a novel task of deciphering hate symbols. To do this, we leverage the Urban Dictionary and collected a new, symbol-rich Twitter corpus of hate speech. We investigate neural network latent context models for deciphering hate symbols. More specifically, we study Sequence-to-Sequence models and show how they are able to crack the ciphers based on context. Furthermore, we propose a novel Variational Decipher and show how it can generalize better to unseen hate symbols in a more challenging testing setting.
Leveraging Intra-User and Inter-User Representation Learning for Automated Hate Speech Detection
Sep 14, 2018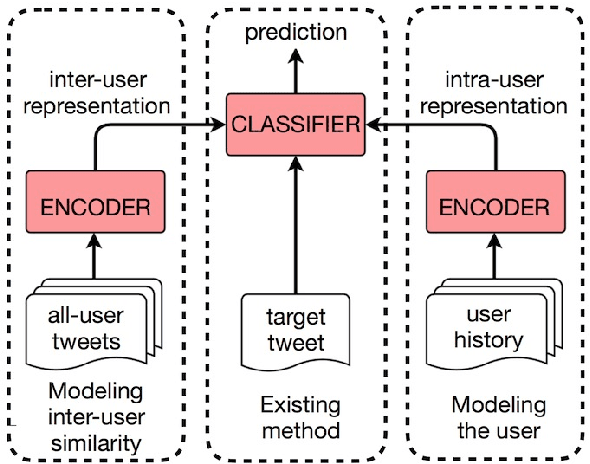
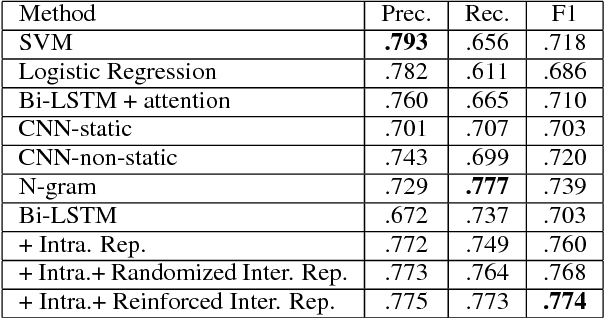
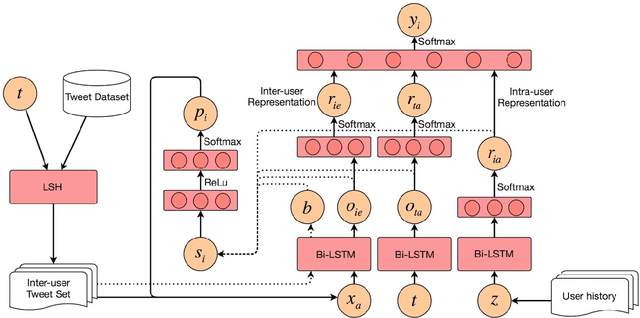
Hate speech detection is a critical, yet challenging problem in Natural Language Processing (NLP). Despite the existence of numerous studies dedicated to the development of NLP hate speech detection approaches, the accuracy is still poor. The central problem is that social media posts are short and noisy, and most existing hate speech detection solutions take each post as an isolated input instance, which is likely to yield high false positive and negative rates. In this paper, we radically improve automated hate speech detection by presenting a novel model that leverages intra-user and inter-user representation learning for robust hate speech detection on Twitter. In addition to the target Tweet, we collect and analyze the user's historical posts to model intra-user Tweet representations. To suppress the noise in a single Tweet, we also model the similar Tweets posted by all other users with reinforced inter-user representation learning techniques. Experimentally, we show that leveraging these two representations can significantly improve the f-score of a strong bidirectional LSTM baseline model by 10.1%.
Hierarchical CVAE for Fine-Grained Hate Speech Classification
Aug 31, 2018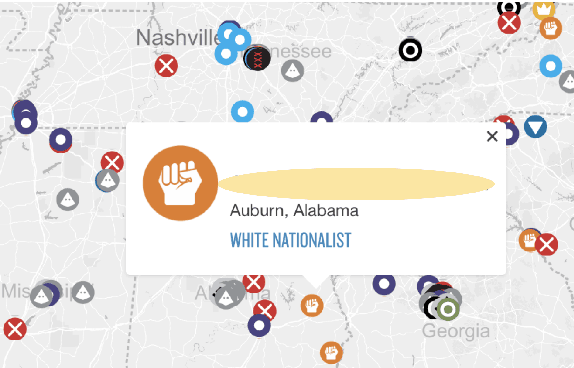
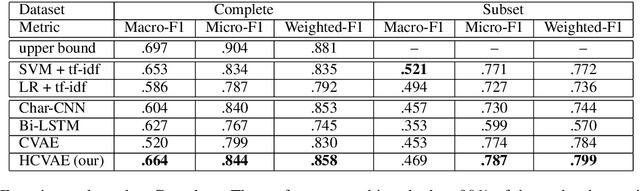
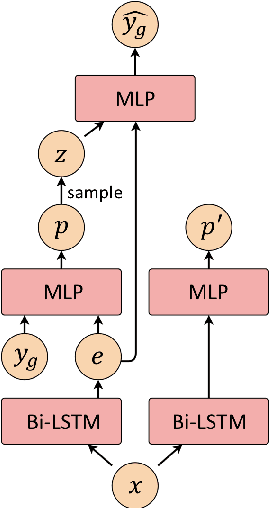
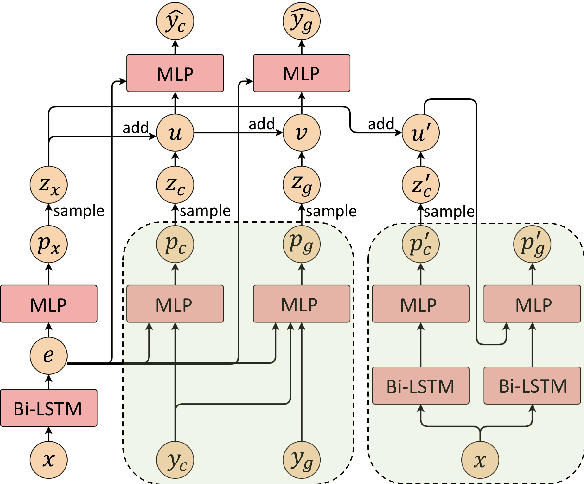
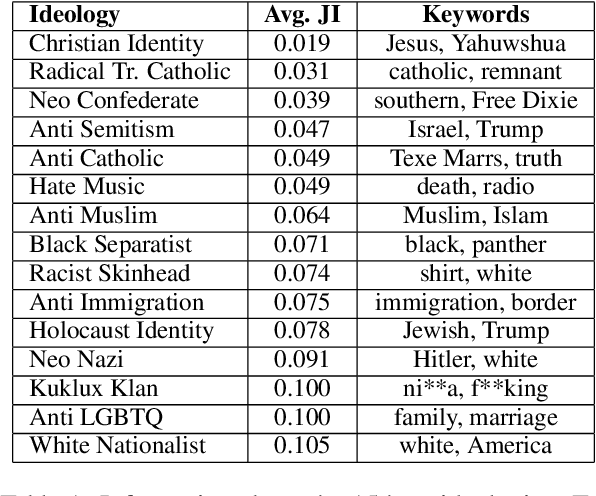
Existing work on automated hate speech detection typically focuses on binary classification or on differentiating among a small set of categories. In this paper, we propose a novel method on a fine-grained hate speech classification task, which focuses on differentiating among 40 hate groups of 13 different hate group categories. We first explore the Conditional Variational Autoencoder (CVAE) as a discriminative model and then extend it to a hierarchical architecture to utilize the additional hate category information for more accurate prediction. Experimentally, we show that incorporating the hate category information for training can significantly improve the classification performance and our proposed model outperforms commonly-used discriminative models.