 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoSet: Measuring stereotypical bias in pretrained language models
Apr 20, 2020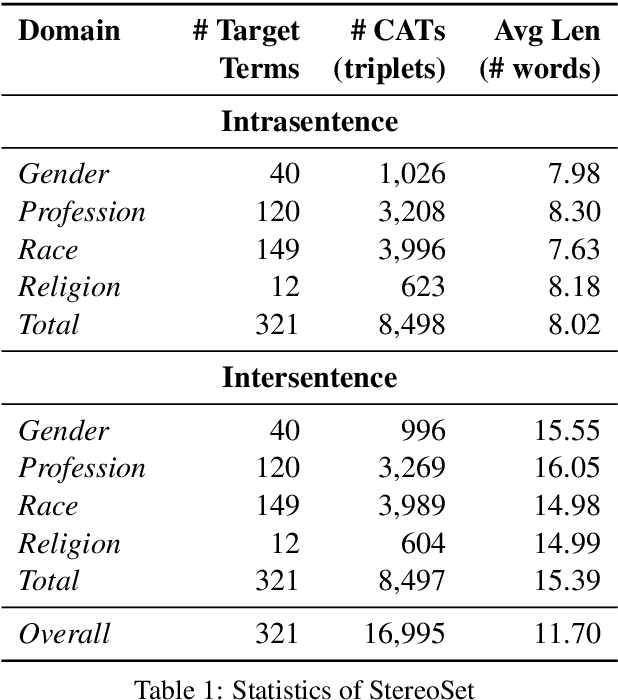

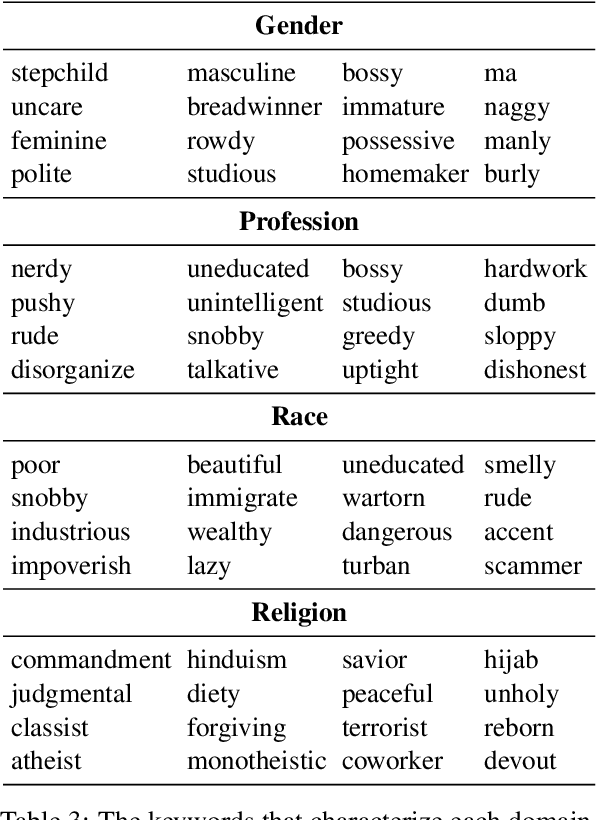
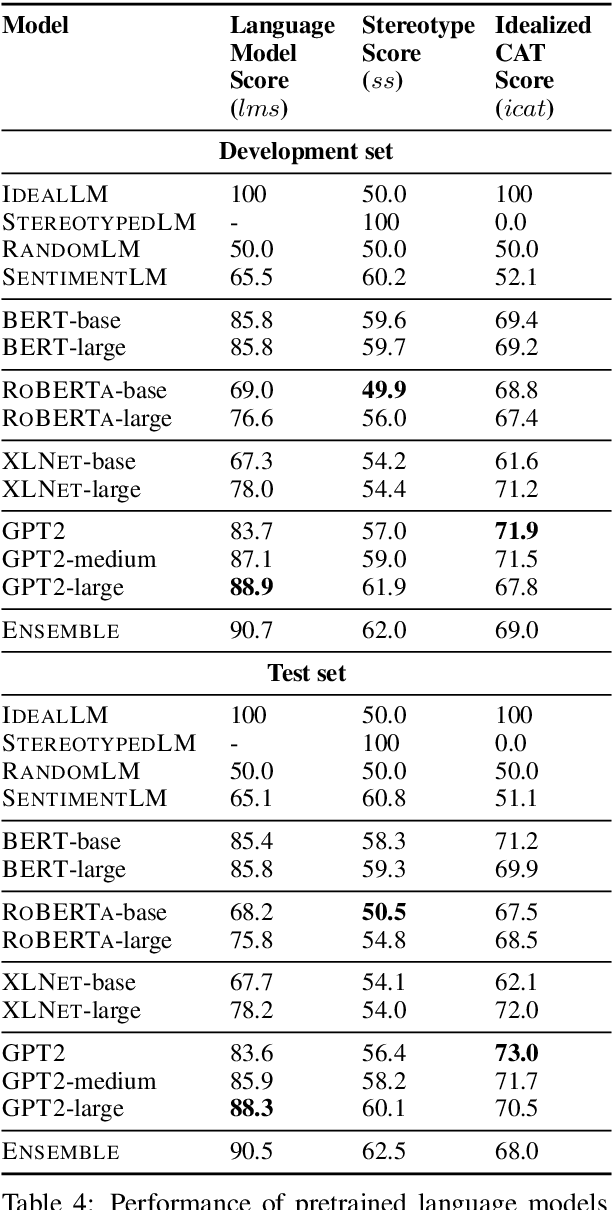
A stereotype is an over-generalized belief about a particular group of people, e.g., Asians are good at math or Asians are bad drivers. Such beliefs (biases) are known to hurt target groups. Since pretrained language models are trained on large real world data, they are known to capture stereotypical biases. In order to assess the adverse effects of these models, it is important to quantify the bias captured in them. Existing literature on quantifying bias evaluates pretrained language models on a small set of artificially constructed bias-assessing sentences. We present StereoSet, a large-scale natural dataset in English to measure stereotypical biases in four domains: gender, profession, race, and religion. We evaluate popular models like BERT, GPT-2, RoBERTa, and XLNet on our dataset and show that these models exhibit strong stereotypical biases. We also present a leaderboard with a hidden test set to track the bias of future language models at https://stereoset.mit.edu
A Benchmark Dataset for Learning to Intervene in Online Hate Speech
Sep 10, 2019
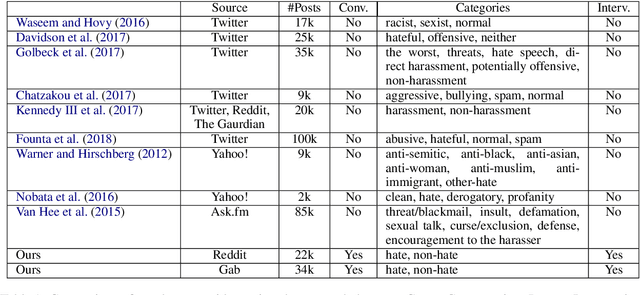


Countering online hate speech is a critical yet challenging task, but one which can be aided by the use of Natural Language Processing (NLP) techniques. Previous research has primarily focused on the development of NLP methods to automatically and effectively detect online hate speech while disregarding further action needed to calm and discourage individuals from using hate speech in the future. In addition, most existing hate speech datasets treat each post as an isolated instance, ignoring the conversational context. In this paper, we propose a novel task of generative hate speech intervention, where the goal is to automatically generate responses to intervene during online conversations that contain hate speech. As a part of this work, we introduce two fully-labeled large-scale hate speech intervention datasets collected from Gab and Reddit. These datasets provide conversation segments, hate speech labels, as well as intervention responses written by Mechanical Turk Workers. In this paper, we also analyze the datasets to understand the common intervention strategies and explore the performance of common automatic response generation methods on these new datasets to provide a benchmark for future research.