 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning approaches for neural decoding: from CNNs to LSTMs and spikes to fMRI
May 19, 2020


Decoding behavior, perception, or cognitive state directly from neural signals has applications in brain-computer interface research as well as implications for systems neuroscience. In the last decade, deep learning has become the state-of-the-art method in many machine learning tasks ranging from speech recognition to image segmentation. The success of deep networks in other domains has led to a new wave of applications in neuroscience. In this article, we review deep learning approaches to neural decoding. We describe the architectures used for extracting useful features from neural recording modalities ranging from spikes to EEG. Furthermore, we explore how deep learning has been leveraged to predict common outputs including movement, speech, and vision, with a focus on how pretrained deep networks can be incorporated as priors for complex decoding targets like acoustic speech or images. Deep learning has been shown to be a useful tool for improving the accuracy and flexibility of neural decoding across a wide range of tasks, and we point out areas for future scientific development.
Unsupervised Discovery of Temporal Structure in Noisy Data with Dynamical Components Analysis
May 23, 2019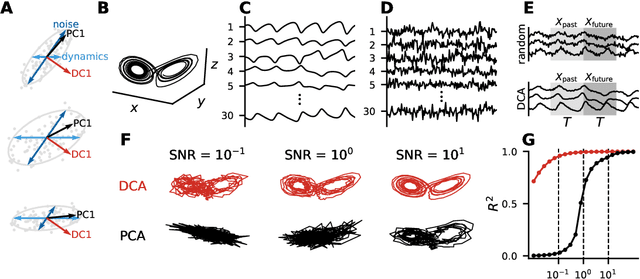
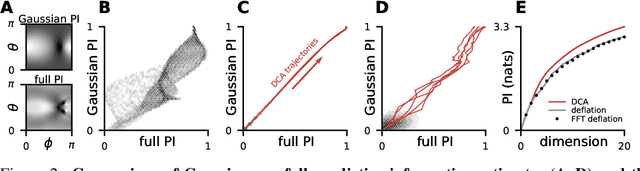
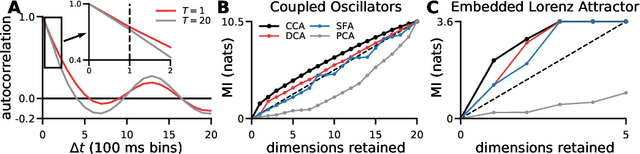
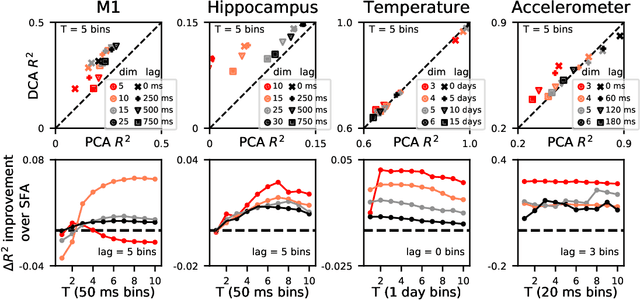
Linear dimensionality reduction methods are commonly used to extract low-dimensional structure from high-dimensional data. However, popular methods disregard temporal structure, rendering them prone to extracting noise rather than meaningful dynamics when applied to time series data. At the same time, many successful unsupervised learning methods for temporal, sequential and spatial data extract features which are predictive of their surrounding context. Combining these approaches, we introduce Dynamical Components Analysis (DCA), a linear dimensionality reduction method which discovers a subspace of high-dimensional time series data with maximal predictive information, defined as the mutual information between the past and future. We test DCA on synthetic examples and demonstrate its superior ability to extract dynamical structure compared to commonly used linear methods. We also apply DCA to several real-world datasets, showing that the dimensions extracted by DCA are more useful than those extracted by other methods for predicting future states and decoding auxiliary variables. Overall, DCA robustly extracts dynamical structure in noisy, high-dimensional data while retaining the computational efficiency and geometric interpretability of linear dimensionality reduction methods.
Hangul Fonts Dataset: a Hierarchical and Compositional Dataset for Interrogating Learned Representations
May 23, 2019
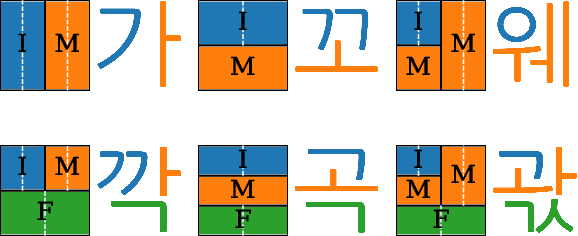

Interpretable representations of data are useful for testing a hypothesis or to distinguish between multiple potential hypotheses about the data. In contrast, applied machine learning, and specifically deep learning (DL), is often used in contexts where performance is valued over interpretability. Indeed, deep networks (DNs) are often treated as ``black boxes'', and it is not well understood what and how they learn from a given dataset. This lack of understanding seriously hinders adoption of DNs as data analysis tools in science and poses numerous research questions. One problem is that current deep learning research datasets either have very little hierarchical structure or are too complex for their structure to be analyzed, impeding precise predictions of hierarchical representations. To address this gap, we present a benchmark dataset with known hierarchical and compositional structure and a set of methods for performing hypothesis-driven data analysis using DNs. The Hangul Fonts Dataset is composed of 35 fonts, each with 11,172 written syllables consisting of 19 initial consonants, 21 medial vowels, and 28 final consonants. The rules for combining and modifying individual Hangul characters into blocks can be encoded, with translation, scaling, and style variation that depend on precise block content, as well as naturalistic variation across fonts. Thus, the Hangul Fonts Dataset will provide an intermediate complexity dataset with well-defined, hierarchical features to interrogate learned representations. We first present a summary of the structure of the dataset. Using a set of unsupervised and supervised methods, we find that deep network representations contain structure related to the geometrical hierarchy of the characters. Our results lay the foundation for a better understanding of what deep networks learn from complex, structured datasets.
Learning overcomplete, low coherence dictionaries with linear inference
Oct 16, 2018
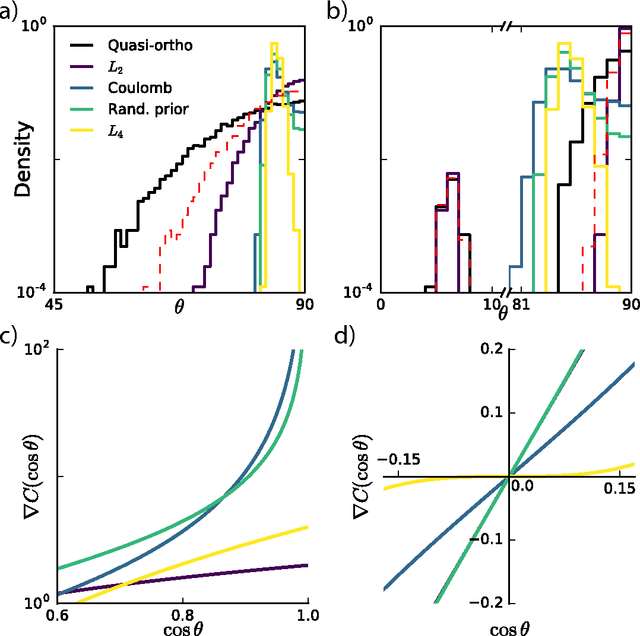
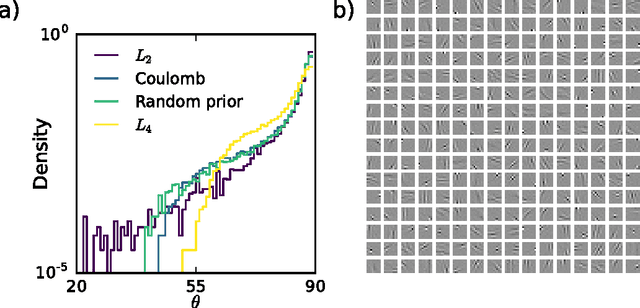

Finding overcomplete latent representations of data has applications in data analysis, signal processing, machine learning, theoretical neuroscience and many other fields. In an overcomplete representation, the number of latent features exceeds the data dimensionality, which is useful when the data is undersampled by the measurements (compressed sensing, information bottlenecks in neural systems) or composed from multiple complete sets of linear features, each spanning the data space. Independent Components Analysis (ICA) is a linear technique for learning sparse latent representations, which typically has a lower computational cost than sparse coding, its nonlinear, recurrent counterpart. While well suited for finding complete representations, we show that overcompleteness poses a challenge to existing ICA algorithms. Specifically, the coherence control in existing ICA algorithms, necessary to prevent the formation of duplicate dictionary features, is ill-suited in the overcomplete case. We show that in this case several existing ICA algorithms have undesirable global minima that maximize coherence. Further, by comparing ICA algorithms on synthetic data and natural images to the computationally more expensive sparse coding solution, we show that the coherence control biases the exploration of the data manifold, sometimes yielding suboptimal solutions. We provide a theoretical explanation of these failures and, based on the theory, propose improved overcomplete ICA algorithms. All told, this study contributes new insights into and methods for coherence control for linear ICA, some of which are applicable to many other, potentially nonlinear, unsupervised learning methods.
Spiking Linear Dynamical Systems on Neuromorphic Hardware for Low-Power Brain-Machine Interfaces
Jun 05, 2018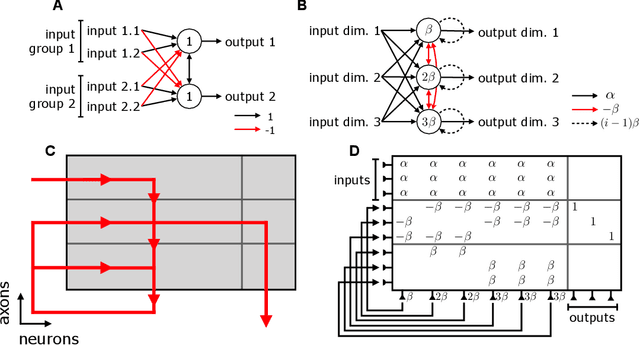
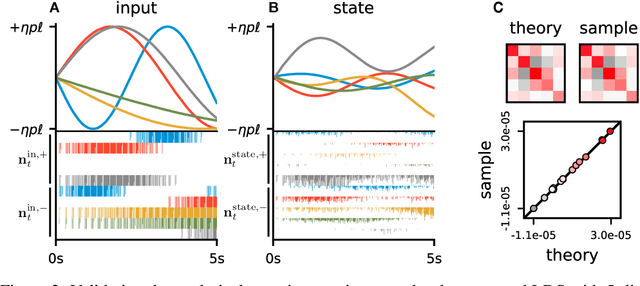
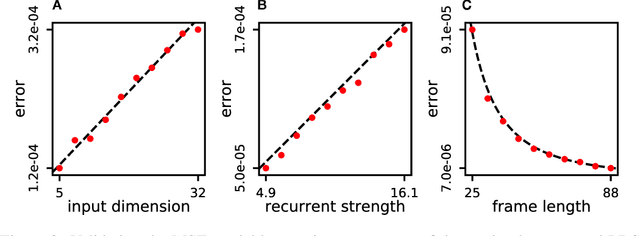
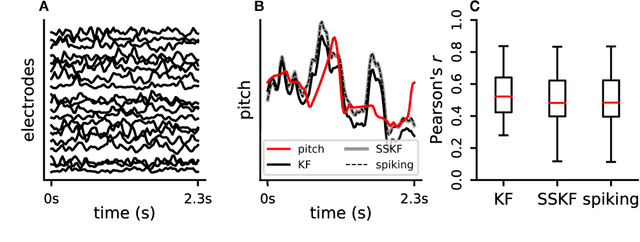
Neuromorphic architectures achieve low-power operation by using many simple spiking neurons in lieu of traditional hardware. Here, we develop methods for precise linear computations in spiking neural networks and use these methods to map the evolution of a linear dynamical system (LDS) onto an existing neuromorphic chip: IBM's TrueNorth. We analytically characterize, and numerically validate, the discrepancy between the spiking LDS state sequence and that of its non-spiking counterpart. These analytical results shed light on the multiway tradeoff between time, space, energy, and accuracy in neuromorphic computation. To demonstrate the utility of our work, we implemented a neuromorphic Kalman filter (KF) and used it for offline decoding of human vocal pitch from neural data. The neuromorphic KF could be used for low-power filtering in domains beyond neuroscience, such as navigation or robotics.
Deep learning as a tool for neural data analysis: speech classification and cross-frequency coupling in human sensorimotor cortex
Mar 26, 2018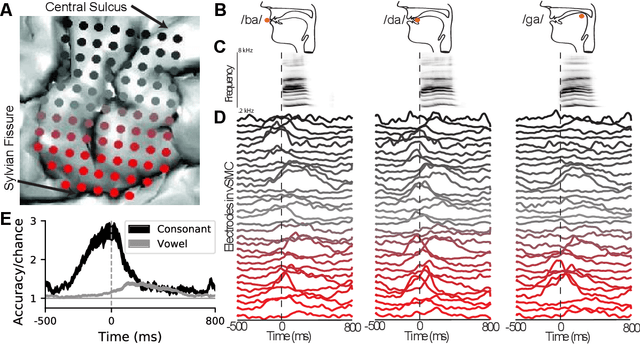
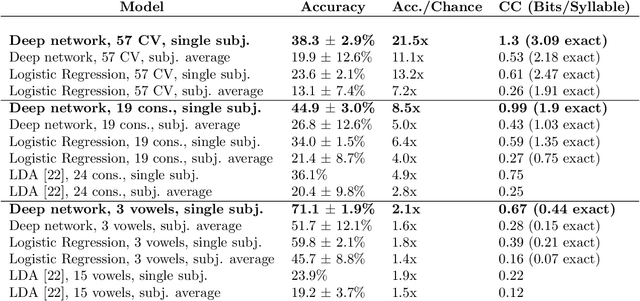
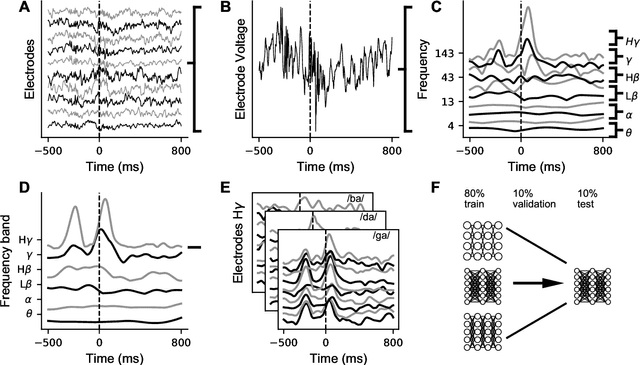
A fundamental challenge in neuroscience is to understand what structure in the world is represented in spatially distributed patterns of neural activity from multiple single-trial measurements. This is often accomplished by learning a simple, linear transformations between neural features and features of the sensory stimuli or motor task. While successful in some early sensory processing areas, linear mappings are unlikely to be ideal tools for elucidating nonlinear, hierarchical representations of higher-order brain areas during complex tasks, such as the production of speech by humans. Here, we apply deep networks to predict produced speech syllables from cortical surface electric potentials recorded from human sensorimotor cortex. We found that deep networks had higher decoding prediction accuracy compared to baseline models, and also exhibited greater improvements in accuracy with increasing dataset size. We further demonstrate that deep network's confusions revealed hierarchical latent structure in the neural data, which recapitulated the underlying articulatory nature of speech motor control. Finally, we used deep networks to compare task-relevant information in different neural frequency bands, and found that the high-gamma band contains the vast majority of information relevant for the speech prediction task, with little-to-no additional contribution from lower-frequencies. Together, these results demonstrate the utility of deep networks as a data analysis tool for neuroscience.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016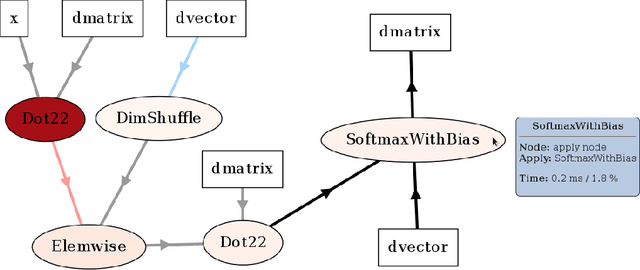
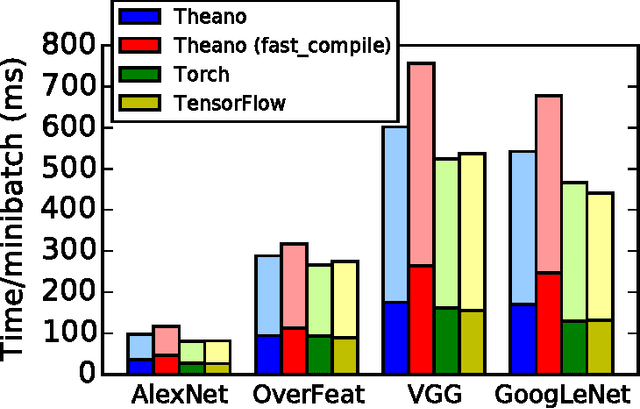
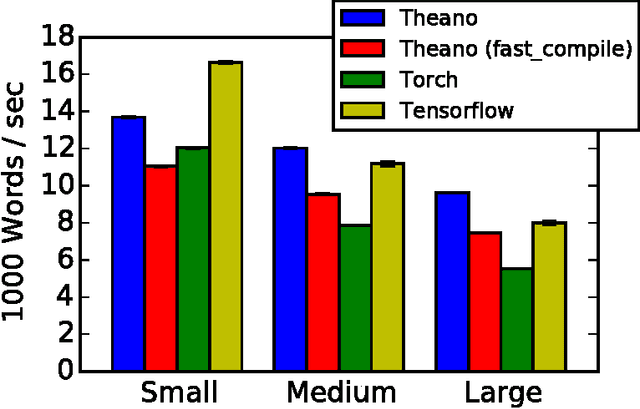
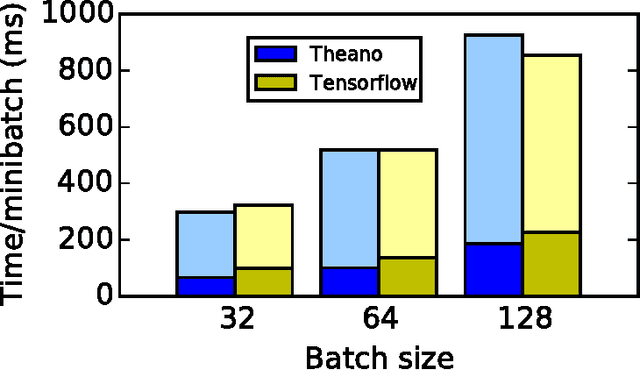
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Discovering Hidden Factors of Variation in Deep Networks
Jun 17, 2015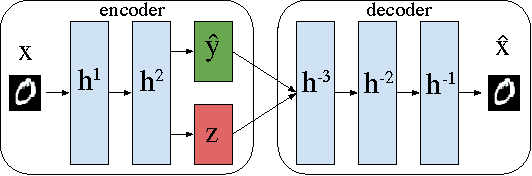
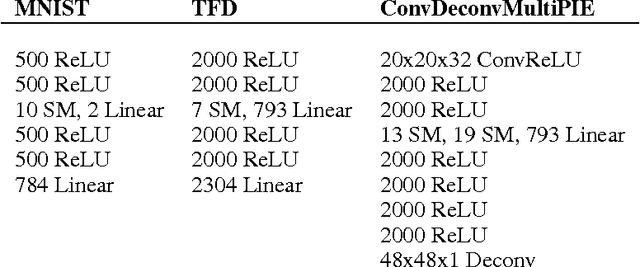


Deep learning has enjoyed a great deal of success because of its ability to learn useful features for tasks such as classification. But there has been less exploration in learning the factors of variation apart from the classification signal. By augmenting autoencoders with simple regularization terms during training, we demonstrate that standard deep architectures can discover and explicitly represent factors of variation beyond those relevant for categorization. We introduce a cross-covariance penalty (XCov) as a method to disentangle factors like handwriting style for digits and subject identity in faces. We demonstrate this on the MNIST handwritten digit database, the Toronto Faces Database (TFD) and the Multi-PIE dataset by generating manipulated instances of the data. Furthermore, we demonstrate these deep networks can extrapolate `hidden' variation in the supervised signal.