 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHangul Fonts Dataset: a Hierarchical and Compositional Dataset for Interrogating Learned Representations
May 23, 2019
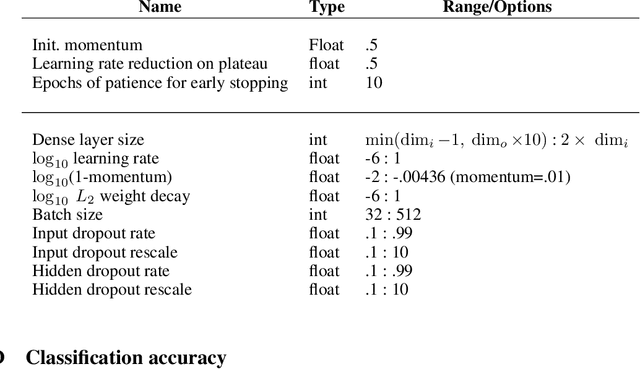
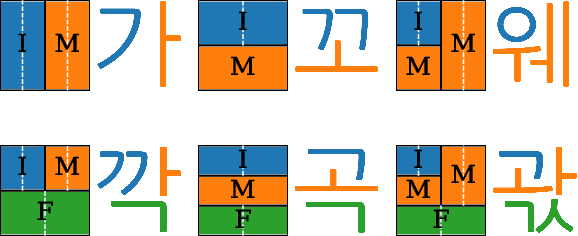

Interpretable representations of data are useful for testing a hypothesis or to distinguish between multiple potential hypotheses about the data. In contrast, applied machine learning, and specifically deep learning (DL), is often used in contexts where performance is valued over interpretability. Indeed, deep networks (DNs) are often treated as ``black boxes'', and it is not well understood what and how they learn from a given dataset. This lack of understanding seriously hinders adoption of DNs as data analysis tools in science and poses numerous research questions. One problem is that current deep learning research datasets either have very little hierarchical structure or are too complex for their structure to be analyzed, impeding precise predictions of hierarchical representations. To address this gap, we present a benchmark dataset with known hierarchical and compositional structure and a set of methods for performing hypothesis-driven data analysis using DNs. The Hangul Fonts Dataset is composed of 35 fonts, each with 11,172 written syllables consisting of 19 initial consonants, 21 medial vowels, and 28 final consonants. The rules for combining and modifying individual Hangul characters into blocks can be encoded, with translation, scaling, and style variation that depend on precise block content, as well as naturalistic variation across fonts. Thus, the Hangul Fonts Dataset will provide an intermediate complexity dataset with well-defined, hierarchical features to interrogate learned representations. We first present a summary of the structure of the dataset. Using a set of unsupervised and supervised methods, we find that deep network representations contain structure related to the geometrical hierarchy of the characters. Our results lay the foundation for a better understanding of what deep networks learn from complex, structured datasets.