 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Hidden Factors of Variation in Deep Networks
Paper and Code
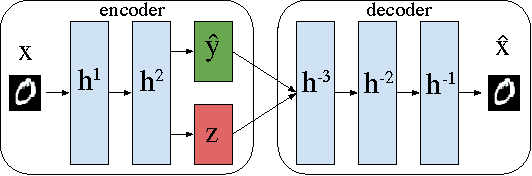
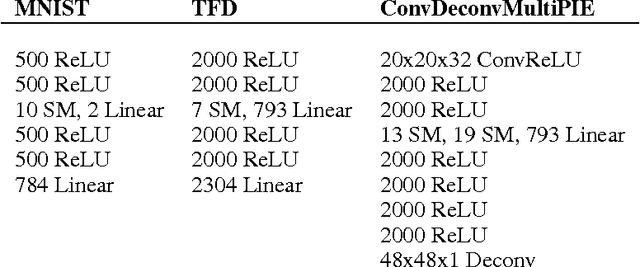


Deep learning has enjoyed a great deal of success because of its ability to learn useful features for tasks such as classification. But there has been less exploration in learning the factors of variation apart from the classification signal. By augmenting autoencoders with simple regularization terms during training, we demonstrate that standard deep architectures can discover and explicitly represent factors of variation beyond those relevant for categorization. We introduce a cross-covariance penalty (XCov) as a method to disentangle factors like handwriting style for digits and subject identity in faces. We demonstrate this on the MNIST handwritten digit database, the Toronto Faces Database (TFD) and the Multi-PIE dataset by generating manipulated instances of the data. Furthermore, we demonstrate these deep networks can extrapolate `hidden' variation in the supervised signal.