 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREPE: A Convolutional Representation for Pitch Estimation
Feb 17, 2018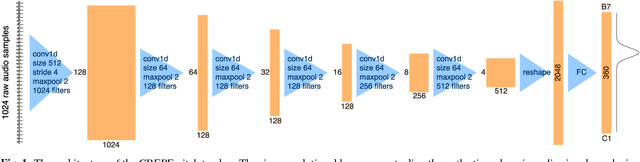
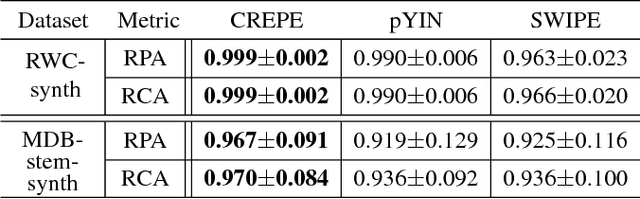
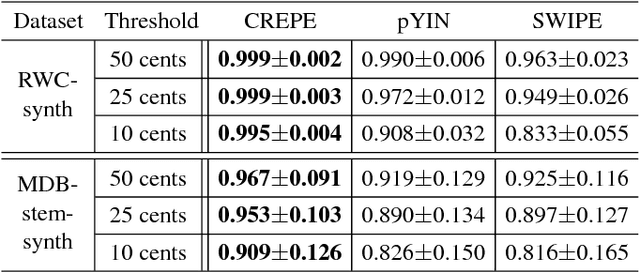
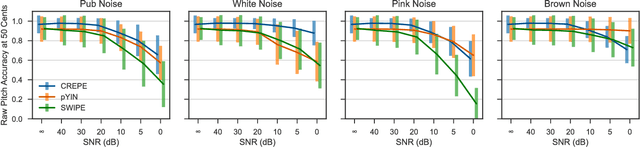
The task of estimating the fundamental frequency of a monophonic sound recording, also known as pitch tracking, is fundamental to audio processing with multiple applications in speech processing and music information retrieval. To date, the best performing techniques, such as the pYIN algorithm, are based on a combination of DSP pipelines and heuristics. While such techniques perform very well on average, there remain many cases in which they fail to correctly estimate the pitch. In this paper, we propose a data-driven pitch tracking algorithm, CREPE, which is based on a deep convolutional neural network that operates directly on the time-domain waveform. We show that the proposed model produces state-of-the-art results, performing equally or better than pYIN. Furthermore, we evaluate the model's generalizability in terms of noise robustness. A pre-trained version of CREPE is made freely available as an open-source Python module for easy application.
Superhuman Accuracy on the SNEMI3D Connectomics Challenge
May 31, 2017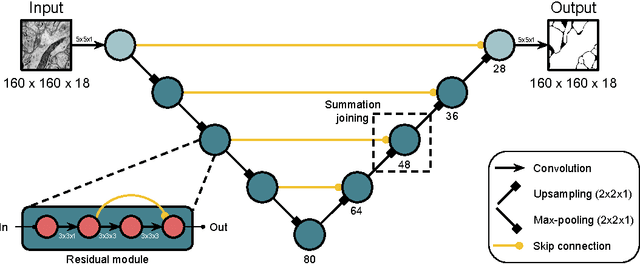
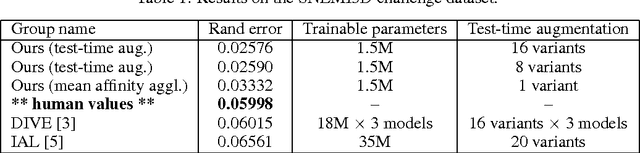
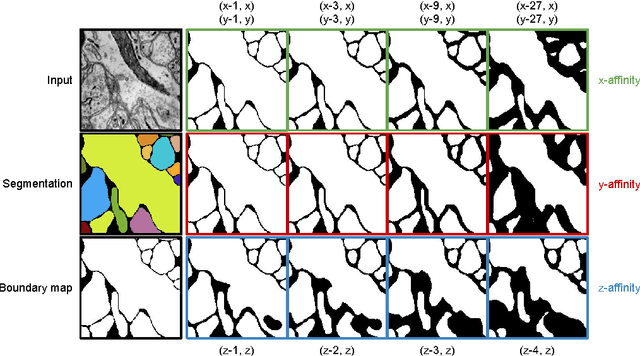
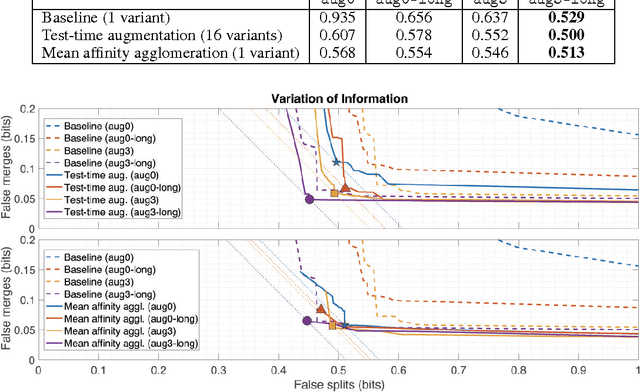
For the past decade, convolutional networks have been used for 3D reconstruction of neurons from electron microscopic (EM) brain images. Recent years have seen great improvements in accuracy, as evidenced by submissions to the SNEMI3D benchmark challenge. Here we report the first submission to surpass the estimate of human accuracy provided by the SNEMI3D leaderboard. A variant of 3D U-Net is trained on a primary task of predicting affinities between nearest neighbor voxels, and an auxiliary task of predicting long-range affinities. The training data is augmented by simulated image defects. The nearest neighbor affinities are used to create an oversegmentation, and then supervoxels are greedily agglomerated based on mean affinity. The resulting SNEMI3D score exceeds the estimate of human accuracy by a large margin. While one should be cautious about extrapolating from the SNEMI3D benchmark to real-world accuracy of large-scale neural circuit reconstruction, our result inspires optimism that the goal of full automation may be realizable in the future.
Flood-Filling Networks
Nov 01, 2016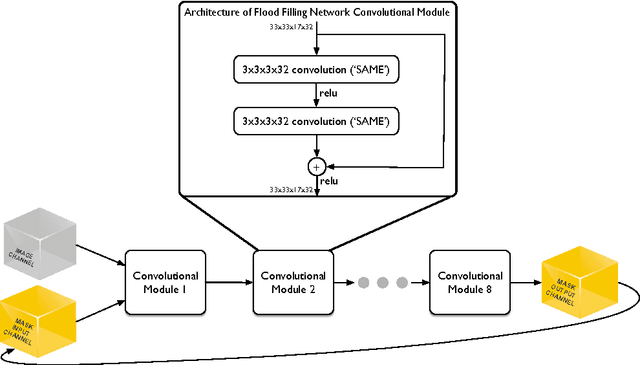
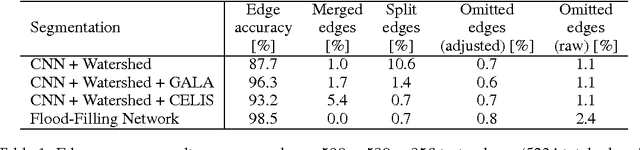
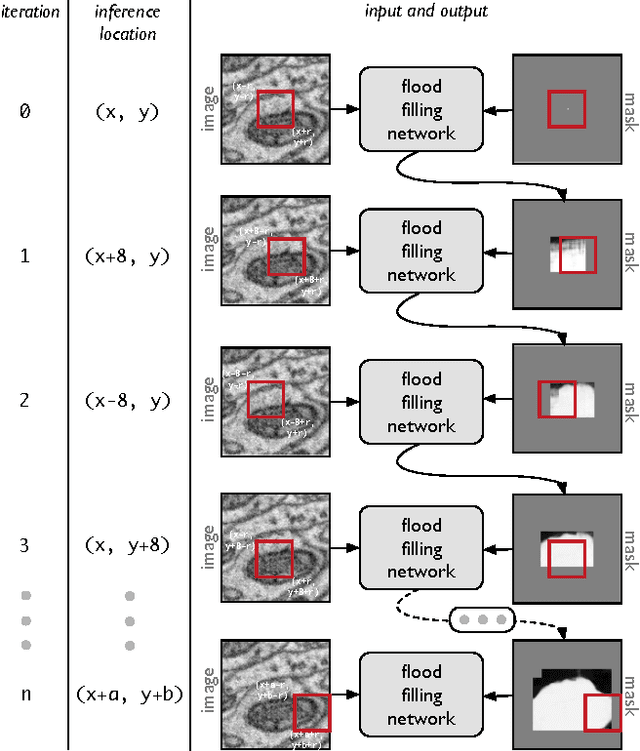
State-of-the-art image segmentation algorithms generally consist of at least two successive and distinct computations: a boundary detection process that uses local image information to classify image locations as boundaries between objects, followed by a pixel grouping step such as watershed or connected components that clusters pixels into segments. Prior work has varied the complexity and approach employed in these two steps, including the incorporation of multi-layer neural networks to perform boundary prediction, and the use of global optimizations during pixel clustering. We propose a unified and end-to-end trainable machine learning approach, flood-filling networks, in which a recurrent 3d convolutional network directly produces individual segments from a raw image. The proposed approach robustly segments images with an unknown and variable number of objects as well as highly variable object sizes. We demonstrate the approach on a challenging 3d image segmentation task, connectomic reconstruction from volume electron microscopy data, on which flood-filling neural networks substantially improve accuracy over other state-of-the-art methods. The proposed approach can replace complex multi-step segmentation pipelines with a single neural network that is learned end-to-end.
Combinatorial Energy Learning for Image Segmentation
Sep 23, 2016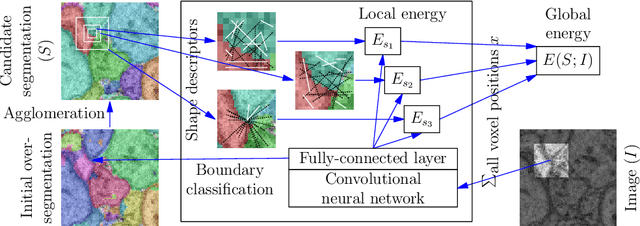
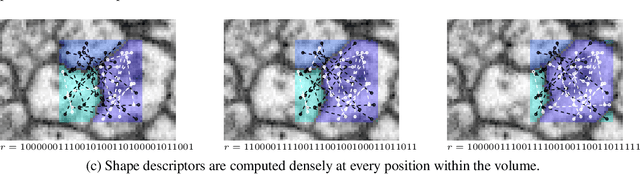
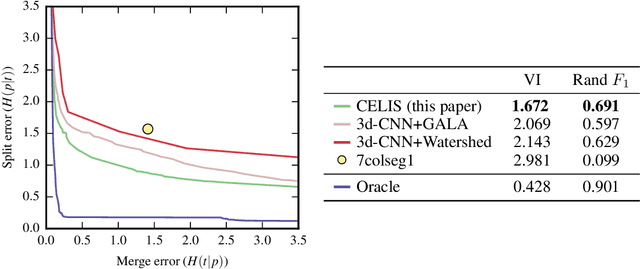
We introduce a new machine learning approach for image segmentation that uses a neural network to model the conditional energy of a segmentation given an image. Our approach, combinatorial energy learning for image segmentation (CELIS) places a particular emphasis on modeling the inherent combinatorial nature of dense image segmentation problems. We propose efficient algorithms for learning deep neural networks to model the energy function, and for local optimization of this energy in the space of supervoxel agglomerations. We extensively evaluate our method on a publicly available 3-D microscopy dataset with 25 billion voxels of ground truth data. On an 11 billion voxel test set, we find that our method improves volumetric reconstruction accuracy by more than 20% as compared to two state-of-the-art baseline methods: graph-based segmentation of the output of a 3-D convolutional neural network trained to predict boundaries, as well as a random forest classifier trained to agglomerate supervoxels that were generated by a 3-D convolutional neural network.
Automatic Instrument Recognition in Polyphonic Music Using Convolutional Neural Networks
Nov 17, 2015
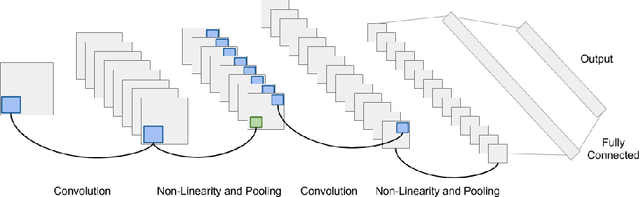

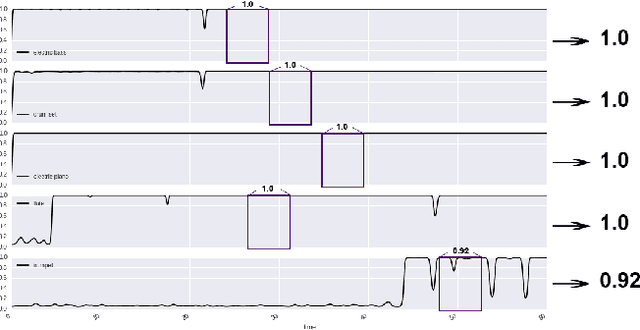
Traditional methods to tackle many music information retrieval tasks typically follow a two-step architecture: feature engineering followed by a simple learning algorithm. In these "shallow" architectures, feature engineering and learning are typically disjoint and unrelated. Additionally, feature engineering is difficult, and typically depends on extensive domain expertise. In this paper, we present an application of convolutional neural networks for the task of automatic musical instrument identification. In this model, feature extraction and learning algorithms are trained together in an end-to-end fashion. We show that a convolutional neural network trained on raw audio can achieve performance surpassing traditional methods that rely on hand-crafted features.