 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022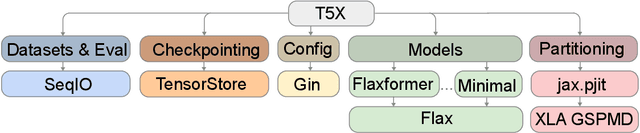
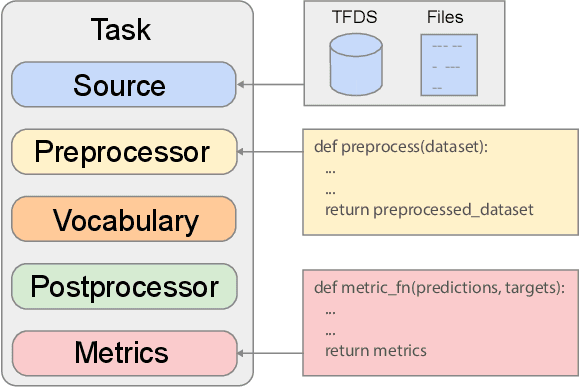
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Flood-Filling Networks
Nov 01, 2016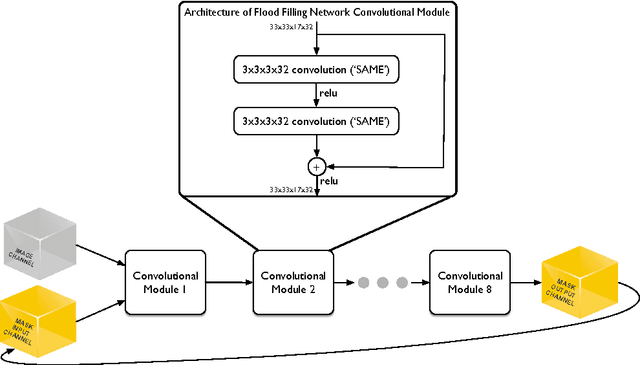
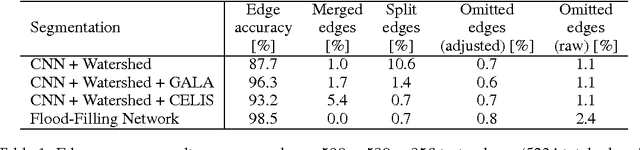
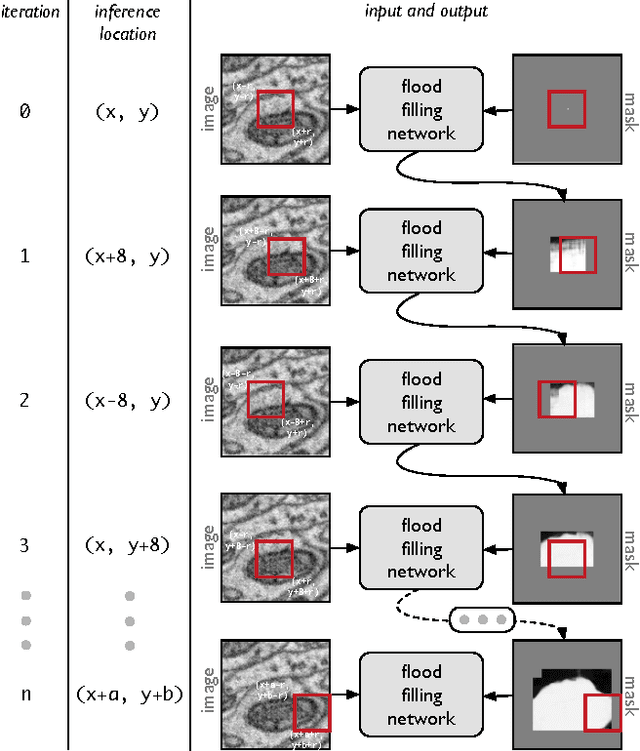
State-of-the-art image segmentation algorithms generally consist of at least two successive and distinct computations: a boundary detection process that uses local image information to classify image locations as boundaries between objects, followed by a pixel grouping step such as watershed or connected components that clusters pixels into segments. Prior work has varied the complexity and approach employed in these two steps, including the incorporation of multi-layer neural networks to perform boundary prediction, and the use of global optimizations during pixel clustering. We propose a unified and end-to-end trainable machine learning approach, flood-filling networks, in which a recurrent 3d convolutional network directly produces individual segments from a raw image. The proposed approach robustly segments images with an unknown and variable number of objects as well as highly variable object sizes. We demonstrate the approach on a challenging 3d image segmentation task, connectomic reconstruction from volume electron microscopy data, on which flood-filling neural networks substantially improve accuracy over other state-of-the-art methods. The proposed approach can replace complex multi-step segmentation pipelines with a single neural network that is learned end-to-end.
Combinatorial Energy Learning for Image Segmentation
Sep 23, 2016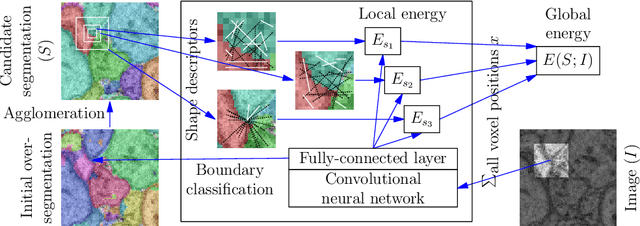
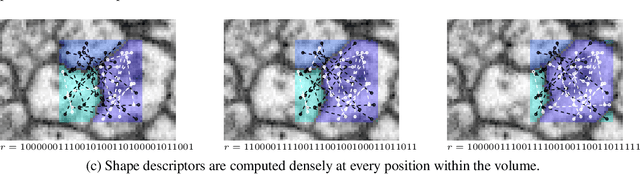
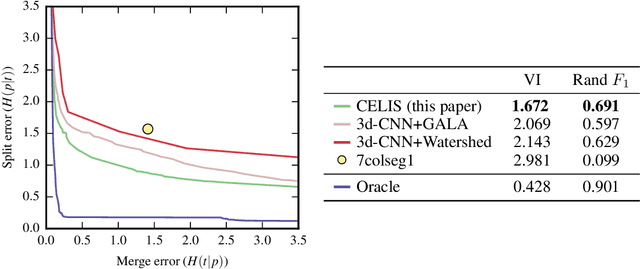
We introduce a new machine learning approach for image segmentation that uses a neural network to model the conditional energy of a segmentation given an image. Our approach, combinatorial energy learning for image segmentation (CELIS) places a particular emphasis on modeling the inherent combinatorial nature of dense image segmentation problems. We propose efficient algorithms for learning deep neural networks to model the energy function, and for local optimization of this energy in the space of supervoxel agglomerations. We extensively evaluate our method on a publicly available 3-D microscopy dataset with 25 billion voxels of ground truth data. On an 11 billion voxel test set, we find that our method improves volumetric reconstruction accuracy by more than 20% as compared to two state-of-the-art baseline methods: graph-based segmentation of the output of a 3-D convolutional neural network trained to predict boundaries, as well as a random forest classifier trained to agglomerate supervoxels that were generated by a 3-D convolutional neural network.