 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images
Jan 25, 2024


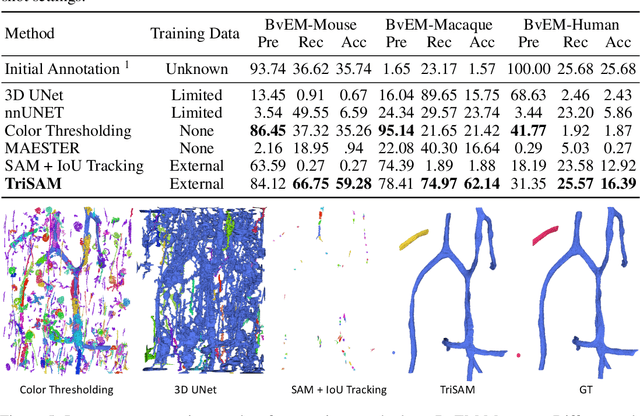
In this paper, we address a significant gap in the field of neuroimaging by introducing the largest-to-date public benchmark, BvEM, designed specifically for cortical blood vessel segmentation in Volume Electron Microscopy (VEM) images. The intricate relationship between cerebral blood vessels and neural function underscores the vital role of vascular analysis in understanding brain health. While imaging techniques at macro and mesoscales have garnered substantial attention and resources, the microscale VEM imaging, capable of revealing intricate vascular details, has lacked the necessary benchmarking infrastructure. As researchers delve deeper into the microscale intricacies of cerebral vasculature, our BvEM benchmark represents a critical step toward unraveling the mysteries of neurovascular coupling and its impact on brain function and pathology. The BvEM dataset is based on VEM image volumes from three mammal species: adult mouse, macaque, and human. We standardized the resolution, addressed imaging variations, and meticulously annotated blood vessels through semi-automatic, manual, and quality control processes, ensuring high-quality 3D segmentation. Furthermore, we developed a zero-shot cortical blood vessel segmentation method named TriSAM, which leverages the powerful segmentation model SAM for 3D segmentation. To lift SAM from 2D segmentation to 3D volume segmentation, TriSAM employs a multi-seed tracking framework, leveraging the reliability of certain image planes for tracking while using others to identify potential turning points. This approach, consisting of Tri-Plane selection, SAM-based tracking, and recursive redirection, effectively achieves long-term 3D blood vessel segmentation without model training or fine-tuning. Experimental results show that TriSAM achieved superior performances on the BvEM benchmark across three species.
An Out-of-Domain Synapse Detection Challenge for Microwasp Brain Connectomes
Feb 01, 2023

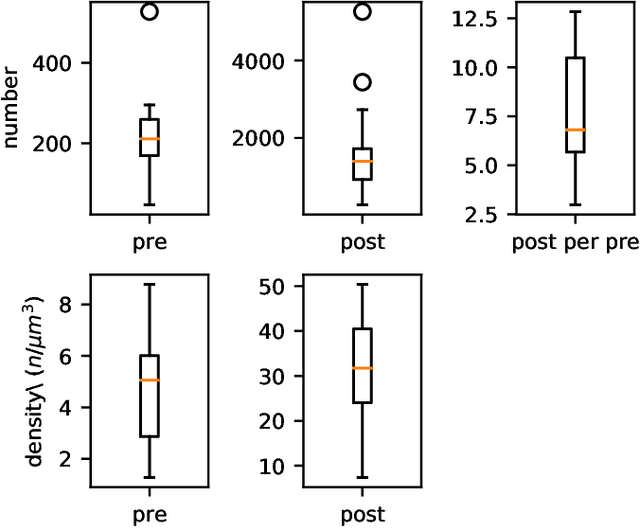

The size of image stacks in connectomics studies now reaches the terabyte and often petabyte scales with a great diversity of appearance across brain regions and samples. However, manual annotation of neural structures, e.g., synapses, is time-consuming, which leads to limited training data often smaller than 0.001\% of the test data in size. Domain adaptation and generalization approaches were proposed to address similar issues for natural images, which were less evaluated on connectomics data due to a lack of out-of-domain benchmarks.
Bridging the Gap: Point Clouds for Merging Neurons in Connectomics
Dec 10, 2021
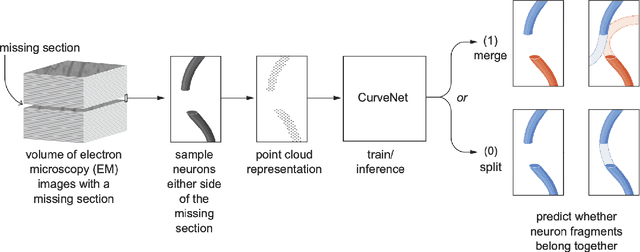

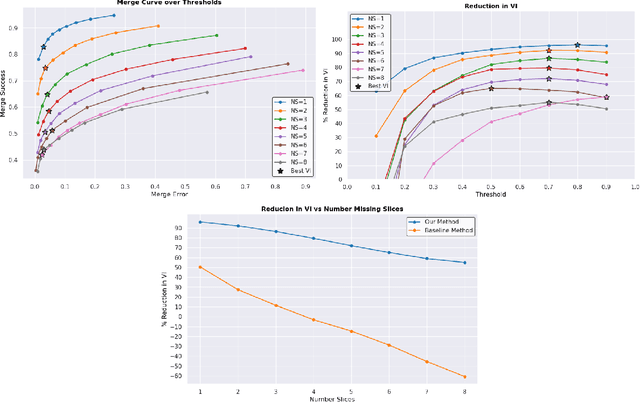
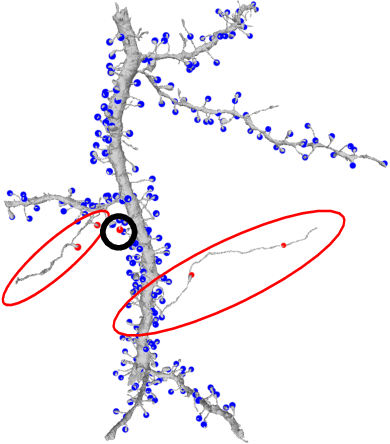
In the field of Connectomics, a primary problem is that of 3D neuron segmentation. Although deep learning-based methods have achieved remarkable accuracy, errors still exist, especially in regions with image defects. One common type of defect is that of consecutive missing image sections. Here, data is lost along some axis, and the resulting neuron segmentations are split across the gap. To address this problem, we propose a novel method based on point cloud representations of neurons. We formulate the problem as a classification problem and train CurveNet, a state-of-the-art point cloud classification model, to identify which neurons should be merged. We show that our method not only performs strongly but also scales reasonably to gaps well beyond what other methods have attempted to address. Additionally, our point cloud representations are highly efficient in terms of data, maintaining high performance with an amount of data that would be unfeasible for other methods. We believe that this is an indicator of the viability of using point cloud representations for other proofreading tasks.
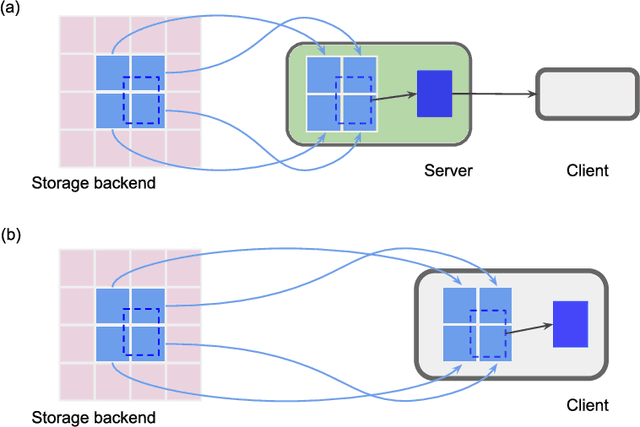
Chunkflow: Distributed Hybrid Cloud Processing of Large 3D Images by Convolutional Nets
May 02, 2019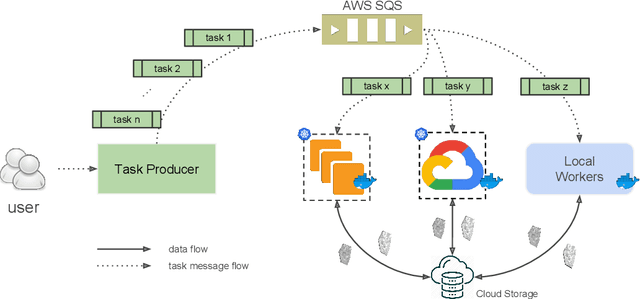
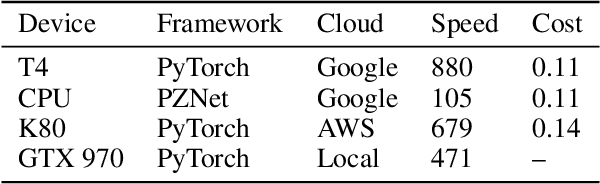
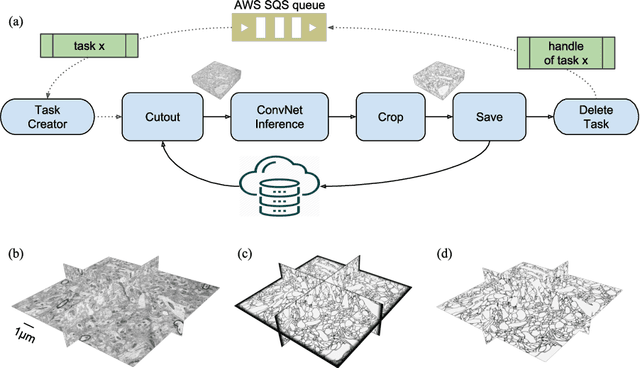
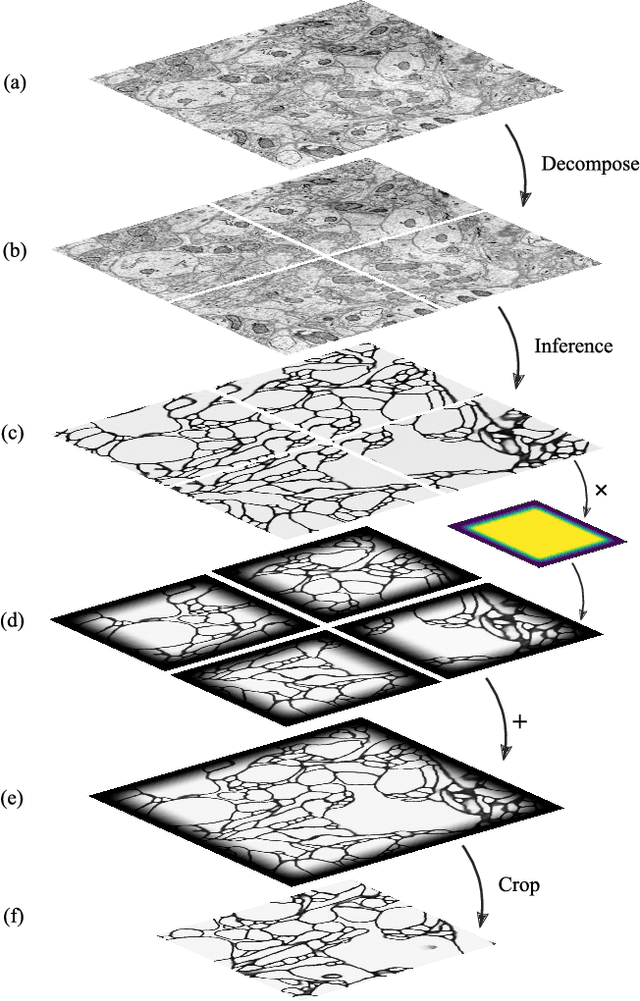
It is now common to process volumetric biomedical images using 3D Convolutional Networks (ConvNets). This can be challenging for the teravoxel and even petavoxel images that are being acquired today by light or electron microscopy. Here we introduce chunkflow, a software framework for distributing ConvNet processing over local and cloud GPUs and CPUs. The image volume is divided into overlapping chunks, each chunk is processed by a ConvNet, and the results are blended together to yield the output image. The frontend submits ConvNet tasks to a cloud queue. The tasks are executed by local and cloud GPUs and CPUs. Thanks to the fault-tolerant architecture of Chunkflow, cost can be greatly reduced by utilizing cheap unstable cloud instances. Chunkflow currently supports PyTorch for GPUs and PZnet for CPUs. To illustrate its usage, a large 3D brain image from serial section electron microscopy was processed by a 3D ConvNet with a U-Net style architecture. Chunkflow provides some chunk operations for general use, and the operations can be composed flexibly in a command line interface.
Convolutional nets for reconstructing neural circuits from brain images acquired by serial section electron microscopy
Apr 29, 2019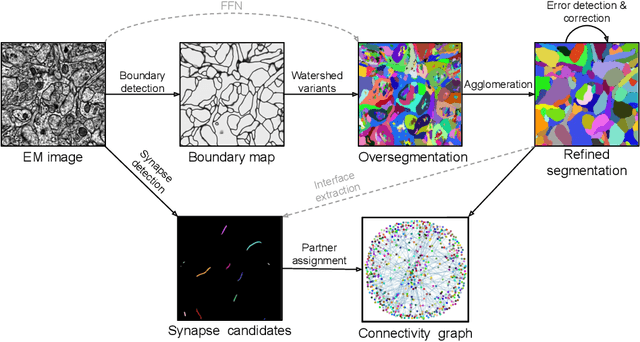

Neural circuits can be reconstructed from brain images acquired by serial section electron microscopy. Image analysis has been performed by manual labor for half a century, and efforts at automation date back almost as far. Convolutional nets were first applied to neuronal boundary detection a dozen years ago, and have now achieved impressive accuracy on clean images. Robust handling of image defects is a major outstanding challenge. Convolutional nets are also being employed for other tasks in neural circuit reconstruction: finding synapses and identifying synaptic partners, extending or pruning neuronal reconstructions, and aligning serial section images to create a 3D image stack. Computational systems are being engineered to handle petavoxel images of cubic millimeter brain volumes.
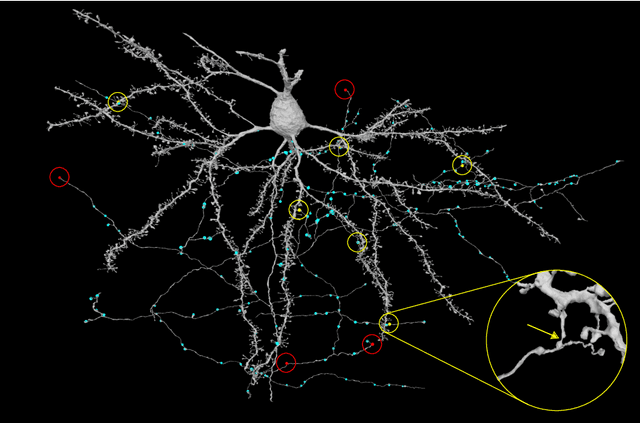
Synaptic Partner Assignment Using Attentional Voxel Association Networks
Apr 22, 2019

Connectomics aims to recover a complete set of synaptic connections within a dataset imaged by electron microscopy. Most systems for locating synapses use voxelwise classifier models, and train these classifiers to reproduce binary masks of synaptic clefts. However, only recent work has included a way to identify the synaptic partners that communicate at synaptic cleft segments. Here, we present a novel method for associating synaptic cleft segments with their synaptic partners using a convolutional network trained to associate the mask of a cleft with the voxels of its synaptic partners. The network takes the local image context and a mask of a single cleft segment as input. It is trained to produce two volumes of output: one which labels the voxels of the presynaptic partner within the input image, and another similar volume for the postsynaptic partner. The cleft mask acts as an attentional gating signal for the network, in that two clefts with the same local image context often have different partners. We find that an implementation of this approach performs well on a dataset of mouse somatosensory cortex, and evaluate it as part of a combined system to predict both clefts and connections.