 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-tuning Neural Network Quantization Framework for Collaborative Inference Between the Cloud and Edge
Paper and Code
Dec 16, 2018
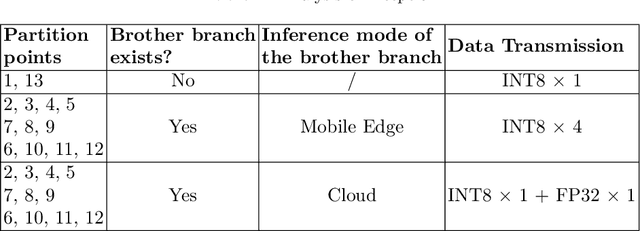
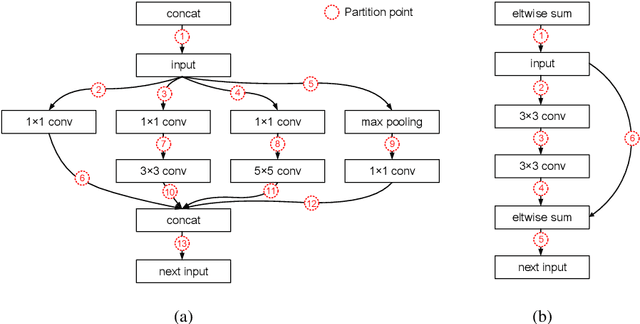

Recently, deep neural networks (DNNs) have been widely applied in mobile intelligent applications. The inference for the DNNs is usually performed in the cloud. However, it leads to a large overhead of transmitting data via wireless network. In this paper, we demonstrate the advantages of the cloud-edge collaborative inference with quantization. By analyzing the characteristics of layers in DNNs, an auto-tuning neural network quantization framework for collaborative inference is proposed. We study the effectiveness of mixed-precision collaborative inference of state-of-the-art DNNs by using ImageNet dataset. The experimental results show that our framework can generate reasonable network partitions and reduce the storage on mobile devices with trivial loss of accuracy.