 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA practical framework for multi-domain speech recognition and an instance sampling method to neural language modeling
Paper and Code
Mar 09, 2022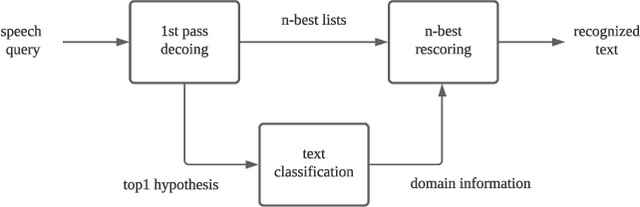


Automatic speech recognition (ASR) systems used on smart phones or vehicles are usually required to process speech queries from very different domains. In such situations, a vanilla ASR system usually fails to perform well on every domain. This paper proposes a multi-domain ASR framework for Tencent Map, a navigation app used on smart phones and in-vehicle infotainment systems. The proposed framework consists of three core parts: a basic ASR module to generate n-best lists of a speech query, a text classification module to determine which domain the speech query belongs to, and a reranking module to rescore n-best lists using domain-specific language models. In addition, an instance sampling based method to training neural network language models (NNLMs) is proposed to address the data imbalance problem in multi-domain ASR. In experiments, the proposed framework was evaluated on navigation domain and music domain, since navigating and playing music are two main features of Tencent Map. Compared to a general ASR system, the proposed framework achieves a relative 13% $\sim$ 22% character error rate reduction on several test sets collected from Tencent Map and our in-car voice assistant.