 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTAD: Tools and Benchmarks for Multivariate Time Series Anomaly Detection
Jan 10, 2024Key Performance Indicators (KPIs) are essential time-series metrics for ensuring the reliability and stability of many software systems. They faithfully record runtime states to facilitate the understanding of anomalous system behaviors and provide informative clues for engineers to pinpoint the root causes. The unprecedented scale and complexity of modern software systems, however, make the volume of KPIs explode. Consequently, many traditional methods of KPI anomaly detection become impractical, which serves as a catalyst for the fast development of machine learning-based solutions in both academia and industry. However, there is currently a lack of rigorous comparison among these KPI anomaly detection methods, and re-implementation demands a non-trivial effort. Moreover, we observe that different works adopt independent evaluation processes with different metrics. Some of them may not fully reveal the capability of a model and some are creating an illusion of progress. To better understand the characteristics of different KPI anomaly detectors and address the evaluation issue, in this paper, we provide a comprehensive review and evaluation of twelve state-of-the-art methods, and propose a novel metric called salience. Particularly, the selected methods include five traditional machine learning-based methods and seven deep learning-based methods. These methods are evaluated with five multivariate KPI datasets that are publicly available. A unified toolkit with easy-to-use interfaces is also released. We report the benchmark results in terms of accuracy, salience, efficiency, and delay, which are of practical importance for industrial deployment. We believe our work can contribute as a basis for future academic research and industrial application.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.
Experience Report: Deep Learning-based System Log Analysis for Anomaly Detection
Jul 13, 2021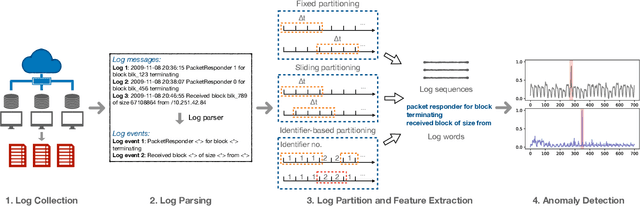

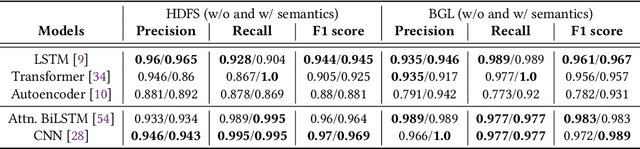
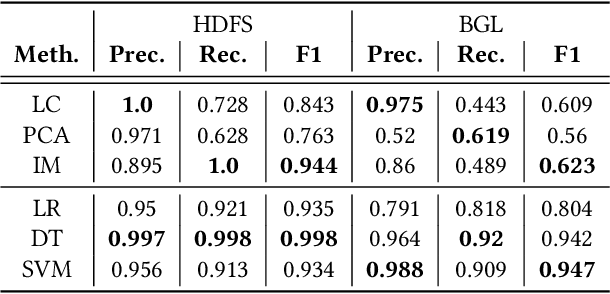
Logs have been an imperative resource to ensure the reliability and continuity of many software systems, especially large-scale distributed systems. They faithfully record runtime information to facilitate system troubleshooting and behavior understanding. Due to the large scale and complexity of modern software systems, the volume of logs has reached an unprecedented level. Consequently, for log-based anomaly detection, conventional methods of manual inspection or even traditional machine learning-based methods become impractical, which serve as a catalyst for the rapid development of deep learning-based solutions. However, there is currently a lack of rigorous comparison among the representative log-based anomaly detectors which resort to neural network models. Moreover, the re-implementation process demands non-trivial efforts and bias can be easily introduced. To better understand the characteristics of different anomaly detectors, in this paper, we provide a comprehensive review and evaluation on five popular models used by six state-of-the-art methods. Particularly, four of the selected methods are unsupervised and the remaining two are supervised. These methods are evaluated with two publicly-available log datasets, which contain nearly 16 millions log messages and 0.4 million anomaly instances in total. We believe our work can serve as a basis in this field and contribute to the future academic researches and industrial applications.