 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Safe: Enhancing Mathematical Reasoning in Large Language Models via Retrospective Step-aware Formal Verification
Jun 05, 2025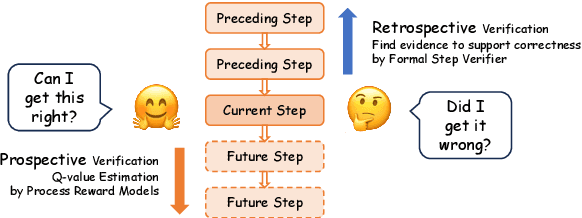



Chain-of-Thought (CoT) prompting has become the de facto method to elicit reasoning capabilities from large language models (LLMs). However, to mitigate hallucinations in CoT that are notoriously difficult to detect, current methods such as process reward models (PRMs) or self-consistency operate as opaque boxes and do not provide checkable evidence for their judgments, possibly limiting their effectiveness. To address this issue, we draw inspiration from the idea that "the gold standard for supporting a mathematical claim is to provide a proof". We propose a retrospective, step-aware formal verification framework $Safe$. Rather than assigning arbitrary scores, we strive to articulate mathematical claims in formal mathematical language Lean 4 at each reasoning step and provide formal proofs to identify hallucinations. We evaluate our framework $Safe$ across multiple language models and various mathematical datasets, demonstrating a significant performance improvement while offering interpretable and verifiable evidence. We also propose $FormalStep$ as a benchmark for step correctness theorem proving with $30,809$ formal statements. To the best of our knowledge, our work represents the first endeavor to utilize formal mathematical language Lean 4 for verifying natural language content generated by LLMs, aligning with the reason why formal mathematical languages were created in the first place: to provide a robust foundation for hallucination-prone human-written proofs.
SolBench: A Dataset and Benchmark for Evaluating Functional Correctness in Solidity Code Completion and Repair
Mar 03, 2025Smart contracts are crucial programs on blockchains, and their immutability post-deployment makes functional correctness vital. Despite progress in code completion models, benchmarks for Solidity, the primary smart contract language, are lacking. Existing metrics like BLEU do not adequately assess the functional correctness of generated smart contracts. To fill this gap, we introduce SolBench, a benchmark for evaluating the functional correctness of Solidity smart contracts generated by code completion models. SolBench includes 4,178 functions from 1,155 Ethereum-deployed contracts. Testing advanced models revealed challenges in generating correct code without context, as Solidity functions rely on context-defined variables and interfaces. To address this, we propose a Retrieval-Augmented Code Repair framework. In this framework, an executor verifies functional correctness, and if necessary, an LLM repairs the code using retrieved snippets informed by executor traces. We conduct a comprehensive evaluation of both closed-source and open-source LLMs across various model sizes and series to assess their performance in smart contract completion. The results show that code repair and retrieval techniques effectively enhance the correctness of smart contract completion while reducing computational costs.
Teaching LLMs According to Their Aptitude: Adaptive Reasoning for Mathematical Problem Solving
Feb 17, 2025



Existing approaches to mathematical reasoning with large language models (LLMs) rely on Chain-of-Thought (CoT) for generalizability or Tool-Integrated Reasoning (TIR) for precise computation. While efforts have been made to combine these methods, they primarily rely on post-selection or predefined strategies, leaving an open question: whether LLMs can autonomously adapt their reasoning strategy based on their inherent capabilities. In this work, we propose TATA (Teaching LLMs According to Their Aptitude), an adaptive framework that enables LLMs to personalize their reasoning strategy spontaneously, aligning it with their intrinsic aptitude. TATA incorporates base-LLM-aware data selection during supervised fine-tuning (SFT) to tailor training data to the model's unique abilities. This approach equips LLMs to autonomously determine and apply the appropriate reasoning strategy at test time. We evaluate TATA through extensive experiments on six mathematical reasoning benchmarks, using both general-purpose and math-specialized LLMs. Empirical results demonstrate that TATA effectively combines the complementary strengths of CoT and TIR, achieving superior or comparable performance with improved inference efficiency compared to TIR alone. Further analysis underscores the critical role of aptitude-aware data selection in enabling LLMs to make effective and adaptive reasoning decisions and align reasoning strategies with model capabilities.