 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRITHopper: Decomposition-Free Multi-Hop Dense Retrieval
Mar 10, 2025



Decomposition-based multi-hop retrieval methods rely on many autoregressive steps to break down complex queries, which breaks end-to-end differentiability and is computationally expensive. Decomposition-free methods tackle this, but current decomposition-free approaches struggle with longer multi-hop problems and generalization to out-of-distribution data. To address these challenges, we introduce GRITHopper-7B, a novel multi-hop dense retrieval model that achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks. GRITHopper combines generative and representational instruction tuning by integrating causal language modeling with dense retrieval training. Through controlled studies, we find that incorporating additional context after the retrieval process, referred to as post-retrieval language modeling, enhances dense retrieval performance. By including elements such as final answers during training, the model learns to better contextualize and retrieve relevant information. GRITHopper-7B offers a robust, scalable, and generalizable solution for multi-hop dense retrieval, and we release it to the community for future research and applications requiring multi-hop reasoning and retrieval capabilities.
Triple-Encoders: Representations That Fire Together, Wire Together
Feb 19, 2024



Search-based dialog models typically re-encode the dialog history at every turn, incurring high cost. Curved Contrastive Learning, a representation learning method that encodes relative distances between utterances into the embedding space via a bi-encoder, has recently shown promising results for dialog modeling at far superior efficiency. While high efficiency is achieved through independently encoding utterances, this ignores the importance of contextualization. To overcome this issue, this study introduces triple-encoders, which efficiently compute distributed utterance mixtures from these independently encoded utterances through a novel hebbian inspired co-occurrence learning objective without using any weights. Empirically, we find that triple-encoders lead to a substantial improvement over bi-encoders, and even to better zero-shot generalization than single-vector representation models without requiring re-encoding. Our code/model is publicly available.
Imagination is All You Need! Curved Contrastive Learning for Abstract Sequence Modeling Utilized on Long Short-Term Dialogue Planning
Nov 14, 2022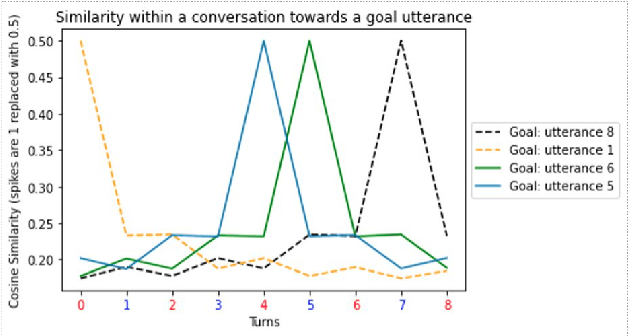



Motivated by the entailment property of multi-turn dialogues through contrastive learning sentence embeddings, we introduce a novel technique, Curved Contrastive Learning (CCL), for generating semantically meaningful and conversational graph curved utterance embeddings that can be compared using cosine similarity. The resulting bi-encoder models can guide transformers as a response ranking model towards a goal in a zero-shot fashion by projecting the goal utterance and the corresponding reply candidates into a latent space. Here the cosine similarity indicates the distance/reachability of a candidate utterance towards the corresponding goal which we define as curved space. Furthermore, we explore how these forward-entailing language representations can be utilized for assessing the likelihood of sequences by the entailment strength i.e. through the cosine similarity of its individual members (encoded separately) as an emergent property in the curved space. This allows us to imagine the likelihood of future patterns in dialogues, specifically by ordering/identifying future goal utterances that are multiple turns away, given a dialogue context. As part of our analysis, we investigate characteristics that make conversations (un)plannable and find strong evidence of planning capability over multiple turns (in 61.56\% over 3 turns) in conversations from the DailyDialog dataset. Finally, we will show how we can exploit the curved property to rank one million utterance & context pairs, in terms of GPU computation time over 7 million times faster than DialogRPT, while being in average 2.8\% qualitatively superior for sequences longer than 2 turns.