 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIVE: Awakening LLM Reasoning via Adversarial Learning and Instructive Verbal Evaluation
Feb 05, 2026The quest for expert-level reasoning in Large Language Models (LLMs) has been hampered by a persistent \textit{reward bottleneck}: traditional reinforcement learning (RL) relies on scalar rewards that are \textbf{costly} to scale, \textbf{brittle} across domains, and \textbf{blind} to the underlying logic of a solution. This reliance on external, impoverished signals prevents models from developing a deep, self-contained understanding of reasoning principles. We introduce \textbf{ALIVE} (\emph{Adversarial Learning with Instructive Verbal Evaluation}), a hands-free alignment framework that moves beyond scalar reward optimization toward intrinsic reasoning acquisition. Grounded in the principle of \emph{Cognitive Synergy}, ALIVE unifies problem posing, solving, and judging within a single policy model to internalize the logic of correctness. By coupling adversarial learning with instructive verbal feedback, ALIVE enables models to internalize evaluative criteria directly from raw corpora, effectively transforming external critiques into an endogenous reasoning faculty. Empirical evaluations across mathematical reasoning, code generation, and general logical inference benchmarks demonstrate that ALIVE consistently mitigates reward signal limitations. With identical data and compute, it achieves accuracy gains, markedly improved cross-domain generalization, and higher self-correction rates. These results indicate that the reasoning trinity fosters a self-sustaining trajectory of capability growth, positioning ALIVE as a scalable foundation for general-purpose reasoning alignment without human-in-the-loop supervision.
MapGuide: A Simple yet Effective Method to Reconstruct Continuous Language from Brain Activities
Apr 02, 2024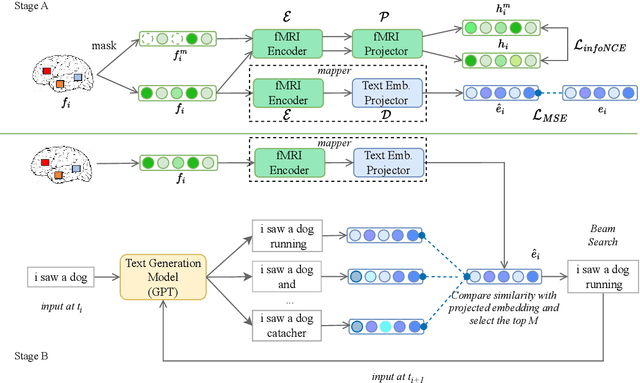
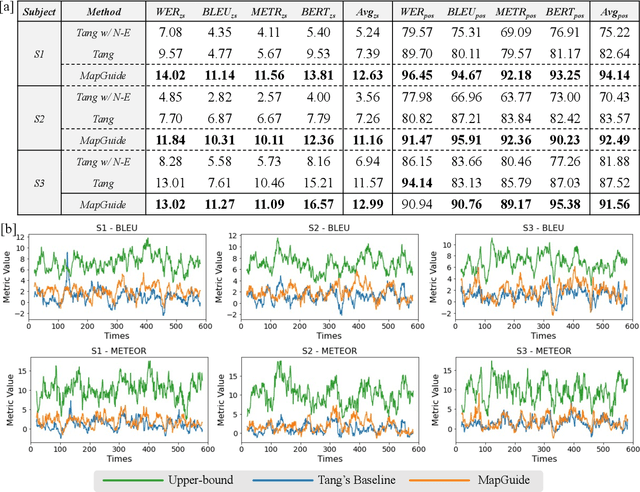
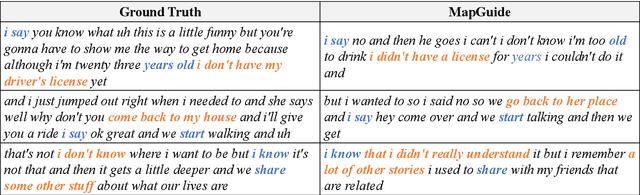
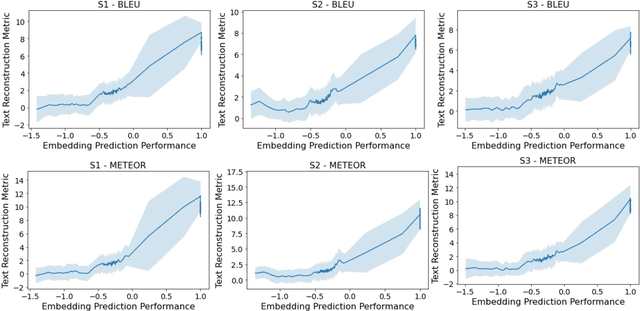
Decoding continuous language from brain activity is a formidable yet promising field of research. It is particularly significant for aiding people with speech disabilities to communicate through brain signals. This field addresses the complex task of mapping brain signals to text. The previous best attempt reverse-engineered this process in an indirect way: it began by learning to encode brain activity from text and then guided text generation by aligning with predicted brain responses. In contrast, we propose a simple yet effective method that guides text reconstruction by directly comparing them with the predicted text embeddings mapped from brain activities. Comprehensive experiments reveal that our method significantly outperforms the current state-of-the-art model, showing average improvements of 77% and 54% on BLEU and METEOR scores. We further validate the proposed modules through detailed ablation studies and case analyses and highlight a critical correlation: the more precisely we map brain activities to text embeddings, the better the text reconstruction results. Such insight can simplify the task of reconstructing language from brain activities for future work, emphasizing the importance of improving brain-to-text-embedding mapping techniques.