 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Inner Properties of Multimodal Representation and Semantic Compositionality with Brain-based Componential Semantics
Paper and Code
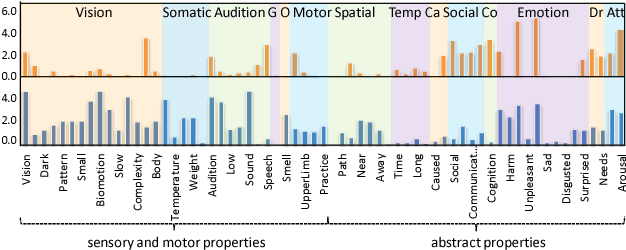


Multimodal models have been proven to outperform text-based approaches on learning semantic representations. However, it still remains unclear what properties are encoded in multimodal representations, in what aspects do they outperform the single-modality representations, and what happened in the process of semantic compositionality in different input modalities. Considering that multimodal models are originally motivated by human concept representations, we assume that correlating multimodal representations with brain-based semantics would interpret their inner properties to answer the above questions. To that end, we propose simple interpretation methods based on brain-based componential semantics. First we investigate the inner properties of multimodal representations by correlating them with corresponding brain-based property vectors. Then we map the distributed vector space to the interpretable brain-based componential space to explore the inner properties of semantic compositionality. Ultimately, the present paper sheds light on the fundamental questions of natural language understanding, such as how to represent the meaning of words and how to combine word meanings into larger units.