 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Reasoning for Robot Dialog and Navigation Tasks
May 20, 2020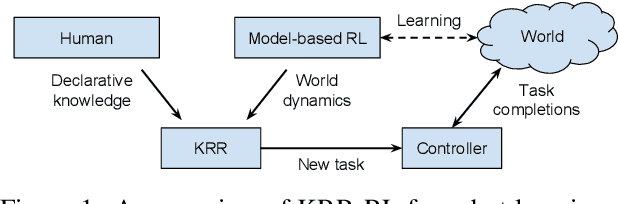

Reinforcement learning and probabilistic reasoning algorithms aim at learning from interaction experiences and reasoning with probabilistic contextual knowledge respectively. In this research, we develop algorithms for robot task completions, while looking into the complementary strengths of reinforcement learning and probabilistic reasoning techniques. The robots learn from trial-and-error experiences to augment their declarative knowledge base, and the augmented knowledge can be used for speeding up the learning process in potentially different tasks. We have implemented and evaluated the developed algorithms using mobile robots conducting dialog and navigation tasks. From the results, we see that our robot's performance can be improved by both reasoning with human knowledge and learning from task-completion experience. More interestingly, the robot was able to learn from navigation tasks to improve its dialog strategies.
Adaptive Dialog Policy Learning with Hindsight and User Modeling
May 07, 2020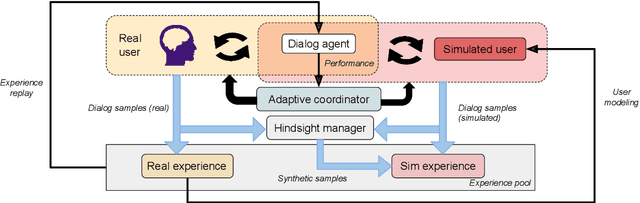

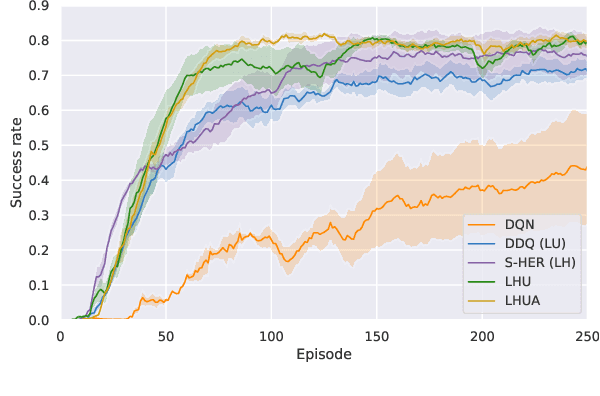
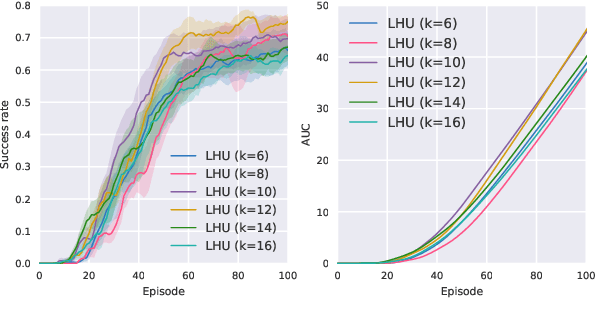
Reinforcement learning methods have been used to compute dialog policies from language-based interaction experiences. Efficiency is of particular importance in dialog policy learning, because of the considerable cost of interacting with people, and the very poor user experience from low-quality conversations. Aiming at improving the efficiency of dialog policy learning, we develop algorithm LHUA (Learning with Hindsight, User modeling, and Adaptation) that, for the first time, enables dialog agents to adaptively learn with hindsight from both simulated and real users. Simulation and hindsight provide the dialog agent with more experience and more (positive) reinforcements respectively. Experimental results suggest that, in success rate and policy quality, LHUA outperforms competitive baselines from the literature, including its no-simulation, no-adaptation, and no-hindsight counterparts.
AutoEG: Automated Experience Grafting for Off-Policy Deep Reinforcement Learning
Apr 23, 2020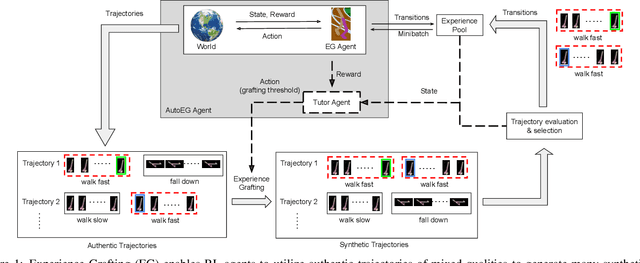


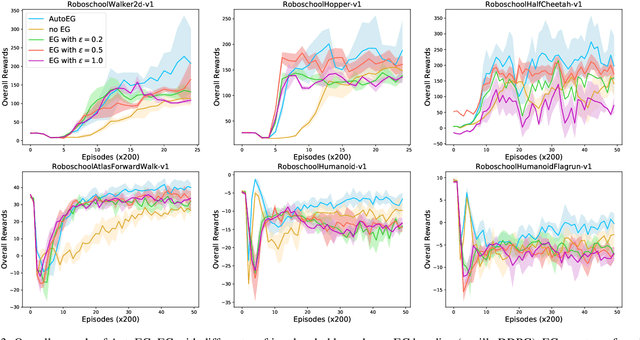
Deep reinforcement learning (RL) algorithms frequently require prohibitive interaction experience to ensure the quality of learned policies. The limitation is partly because the agent cannot learn much from the many low-quality trials in early learning phase, which results in low learning rate. Focusing on addressing this limitation, this paper makes a twofold contribution. First, we develop an algorithm, called Experience Grafting (EG), to enable RL agents to reorganize segments of the few high-quality trajectories from the experience pool to generate many synthetic trajectories while retaining the quality. Second, building on EG, we further develop an AutoEG agent that automatically learns to adjust the grafting-based learning strategy. Results collected from a set of six robotic control environments show that, in comparison to a standard deep RL algorithm (DDPG), AutoEG increases the speed of learning process by at least 30%.
Robot Representing and Reasoning with Knowledge from Reinforcement Learning
Oct 09, 2018

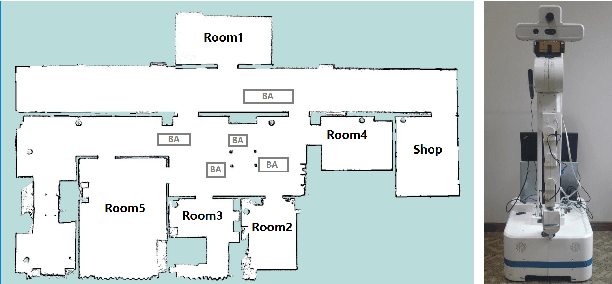
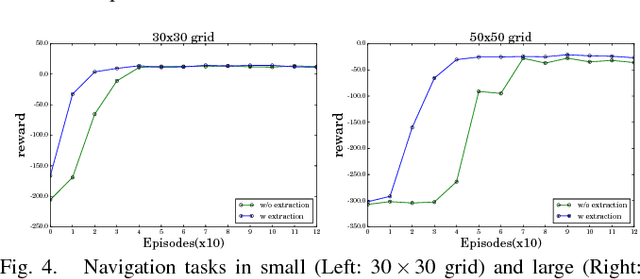
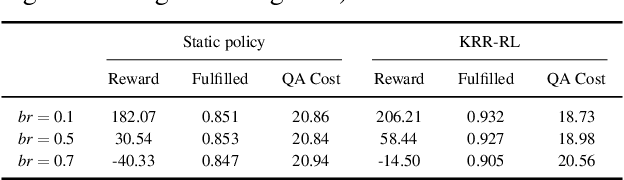
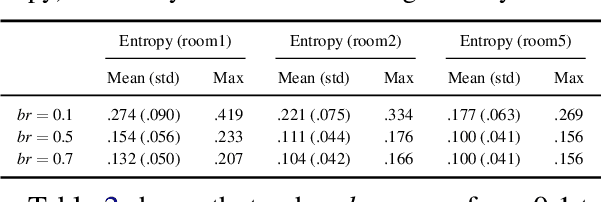
Reinforcement learning (RL) agents aim at learning by interacting with an environment, and are not designed for representing or reasoning with declarative knowledge. Knowledge representation and reasoning (KRR) paradigms are strong in declarative KRR tasks, but are ill-equipped to learn from such experiences. In this work, we integrate logical-probabilistic KRR with model-based RL, enabling agents to simultaneously reason with declarative knowledge and learn from interaction experiences. The knowledge from humans and RL is unified and used for dynamically computing task-specific planning models under potentially new environments. Experiments were conducted using a mobile robot working on dialog, navigation, and delivery tasks. Results show significant improvements, in comparison to existing model-based RL methods.
Learning to Dialogue via Complex Hindsight Experience Replay
Aug 20, 2018
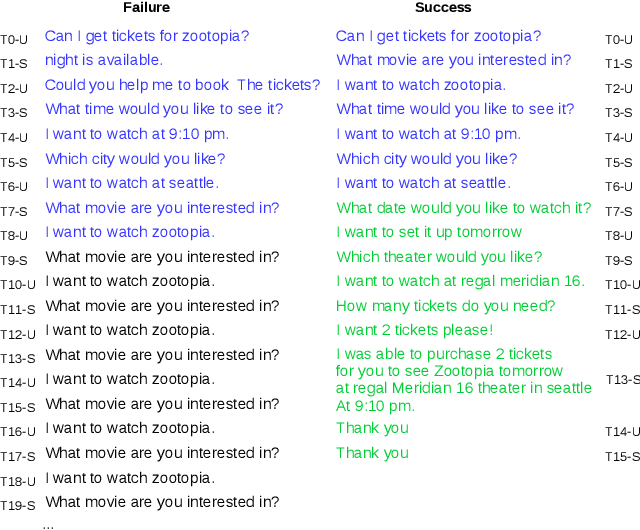
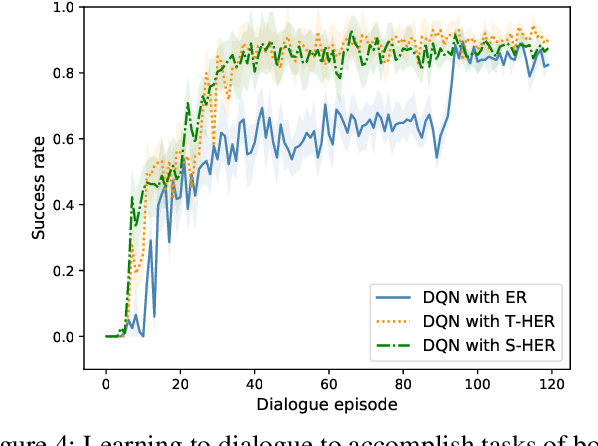

Reinforcement learning methods have been used for learning dialogue policies from the experience of conversations. However, learning an effective dialogue policy frequently requires prohibitively many conversations. This is partly because of the sparse rewards in dialogues, and the relatively small number of successful dialogues in early learning phase. Hindsight experience replay (HER) enables an agent to learn from failure, but the vanilla HER is inapplicable to dialogue domains due to dialogue goals being implicit (c.f., explicit goals in manipulation tasks). In this work, we develop two complex HER methods providing different trade-offs between complexity and performance. Experiments were conducted using a realistic user simulator. Results suggest that our HER methods perform better than standard and prioritized experience replay methods (as applied to deep Q-networks) in learning rate, and that our two complex HER methods can be combined to produce the best performance.