 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Representing and Reasoning with Knowledge from Reinforcement Learning
Paper and Code
Oct 09, 2018

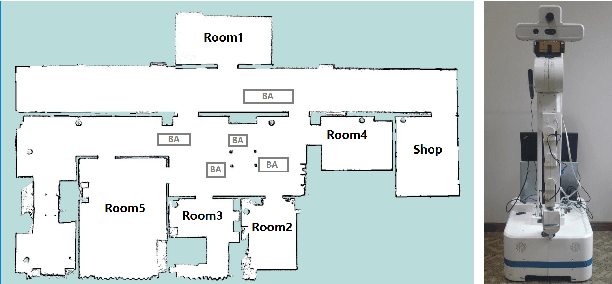
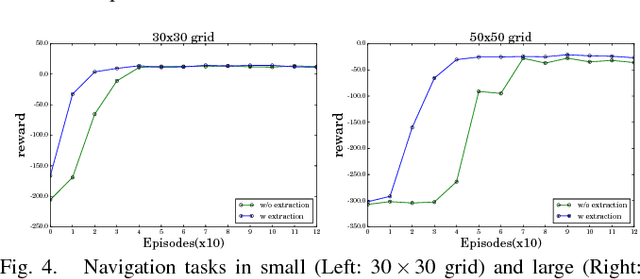
Reinforcement learning (RL) agents aim at learning by interacting with an environment, and are not designed for representing or reasoning with declarative knowledge. Knowledge representation and reasoning (KRR) paradigms are strong in declarative KRR tasks, but are ill-equipped to learn from such experiences. In this work, we integrate logical-probabilistic KRR with model-based RL, enabling agents to simultaneously reason with declarative knowledge and learn from interaction experiences. The knowledge from humans and RL is unified and used for dynamically computing task-specific planning models under potentially new environments. Experiments were conducted using a mobile robot working on dialog, navigation, and delivery tasks. Results show significant improvements, in comparison to existing model-based RL methods.