 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching Neuromorphic Events and Color Images via Adversarial Learning
Mar 02, 2020
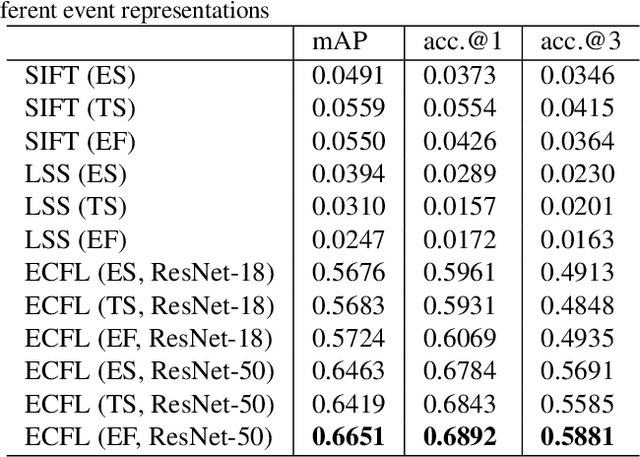
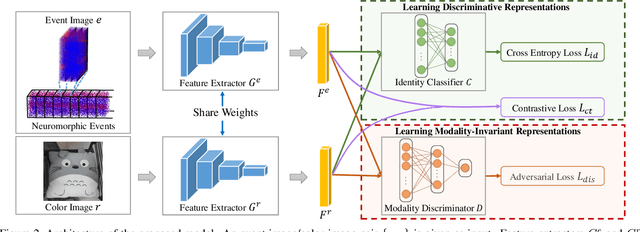

The event camera has appealing properties: high dynamic range, low latency, low power consumption and low memory usage, and thus provides complementariness to conventional frame-based cameras. It only captures the dynamics of a scene and is able to capture almost "continuous" motion. However, different from frame-based camera that reflects the whole appearance as scenes are, the event camera casts away the detailed characteristics of objects, such as texture and color. To take advantages of both modalities, the event camera and frame-based camera are combined together for various machine vision tasks. Then the cross-modal matching between neuromorphic events and color images plays a vital and essential role. In this paper, we propose the Event-Based Image Retrieval (EBIR) problem to exploit the cross-modal matching task. Given an event stream depicting a particular object as query, the aim is to retrieve color images containing the same object. This problem is challenging because there exists a large modality gap between neuromorphic events and color images. We address the EBIR problem by proposing neuromorphic Events-Color image Feature Learning (ECFL). Particularly, the adversarial learning is employed to jointly model neuromorphic events and color images into a common embedding space. We also contribute to the community N-UKbench and EC180 dataset to promote the development of EBIR problem. Extensive experiments on our datasets show that the proposed method is superior in learning effective modality-invariant representation to link two different modalities.
Rotation-Sensitive Regression for Oriented Scene Text Detection
Mar 14, 2018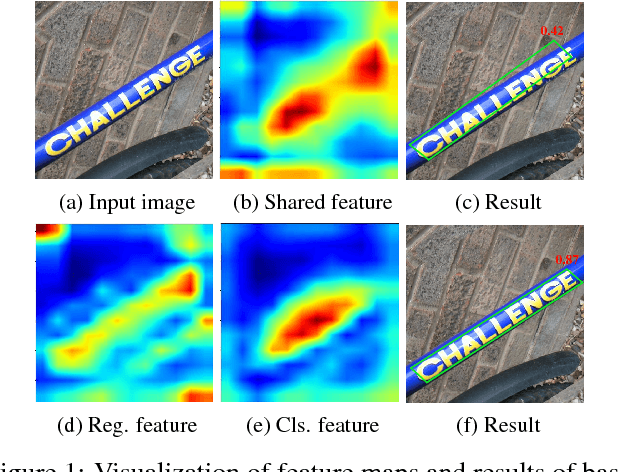
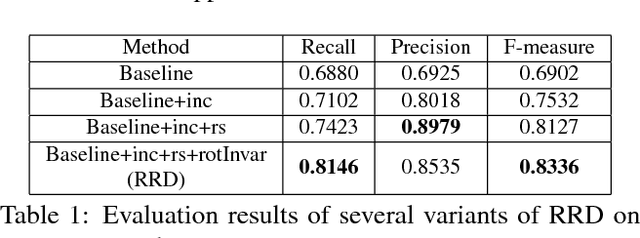

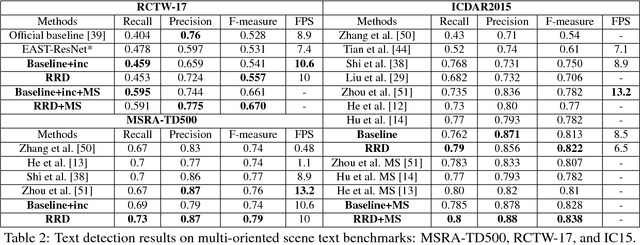
Text in natural images is of arbitrary orientations, requiring detection in terms of oriented bounding boxes. Normally, a multi-oriented text detector often involves two key tasks: 1) text presence detection, which is a classification problem disregarding text orientation; 2) oriented bounding box regression, which concerns about text orientation. Previous methods rely on shared features for both tasks, resulting in degraded performance due to the incompatibility of the two tasks. To address this issue, we propose to perform classification and regression on features of different characteristics, extracted by two network branches of different designs. Concretely, the regression branch extracts rotation-sensitive features by actively rotating the convolutional filters, while the classification branch extracts rotation-invariant features by pooling the rotation-sensitive features. The proposed method named Rotation-sensitive Regression Detector (RRD) achieves state-of-the-art performance on three oriented scene text benchmark datasets, including ICDAR 2015, MSRA-TD500, RCTW-17 and COCO-Text. Furthermore, RRD achieves a significant improvement on a ship collection dataset, demonstrating its generality on oriented object detection.