 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Structured Text Recognition with Regular Expression Biasing
Paper and Code
Nov 10, 2021
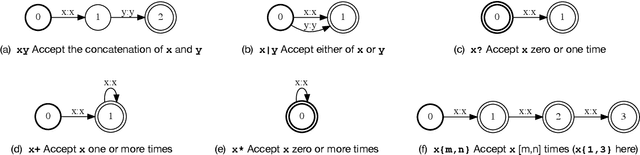
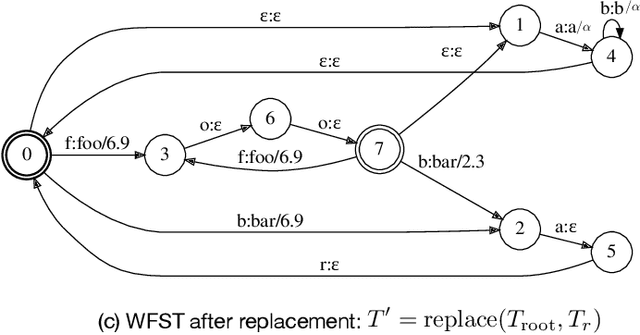

We study the problem of recognizing structured text, i.e. text that follows certain formats, and propose to improve the recognition accuracy of structured text by specifying regular expressions (regexes) for biasing. A biased recognizer recognizes text that matches the specified regexes with significantly improved accuracy, at the cost of a generally small degradation on other text. The biasing is realized by modeling regexes as a Weighted Finite-State Transducer (WFST) and injecting it into the decoder via dynamic replacement. A single hyperparameter controls the biasing strength. The method is useful for recognizing text lines with known formats or containing words from a domain vocabulary. Examples include driver license numbers, drug names in prescriptions, etc. We demonstrate the efficacy of regex biasing on datasets of printed and handwritten structured text and measures its side effects.