Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextBoxes: A Fast Text Detector with a Single Deep Neural Network
Paper and Code
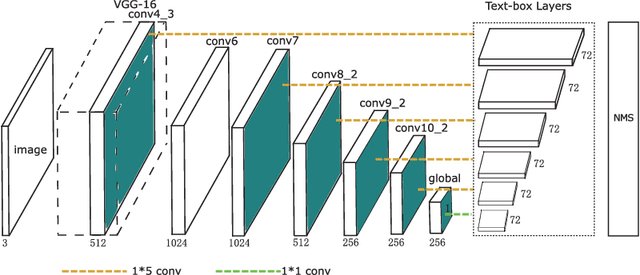
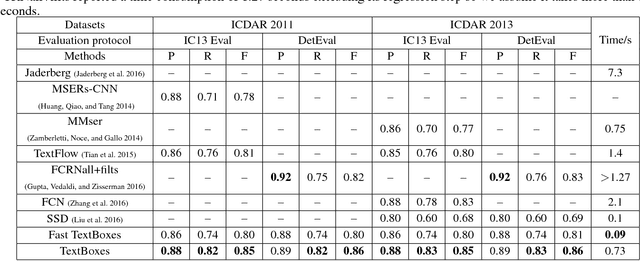
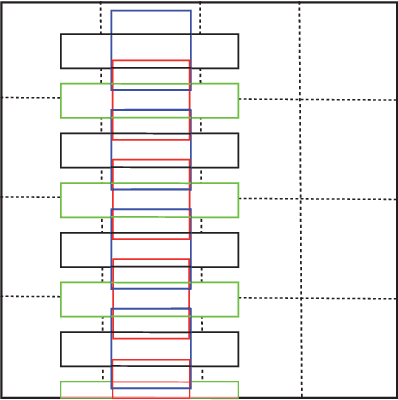
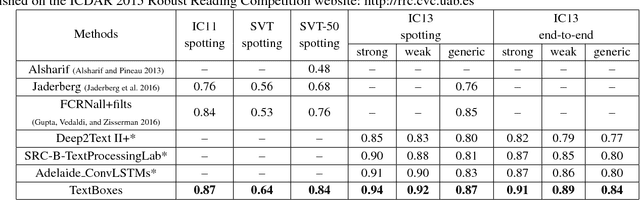
This paper presents an end-to-end trainable fast scene text detector, named TextBoxes, which detects scene text with both high accuracy and efficiency in a single network forward pass, involving no post-process except for a standard non-maximum suppression. TextBoxes outperforms competing methods in terms of text localization accuracy and is much faster, taking only 0.09s per image in a fast implementation. Furthermore, combined with a text recognizer, TextBoxes significantly outperforms state-of-the-art approaches on word spotting and end-to-end text recognition tasks.
* Accepted by AAAI2017
View paper on