 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogZoo: Large-Scale Dialog-Oriented Task Learning
May 25, 2022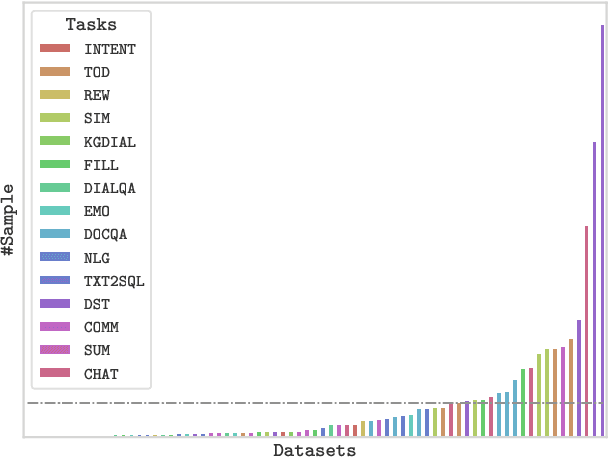
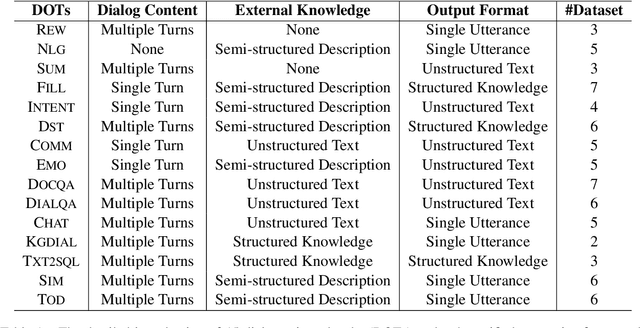
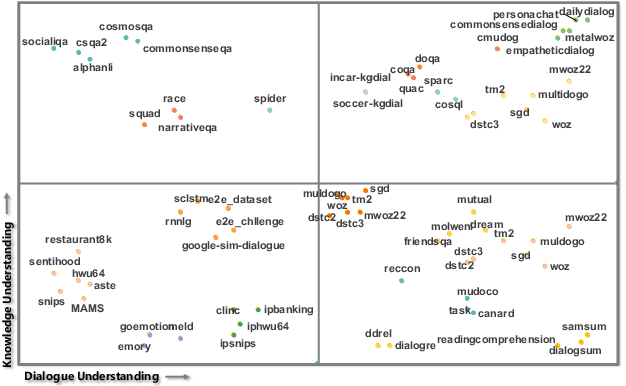
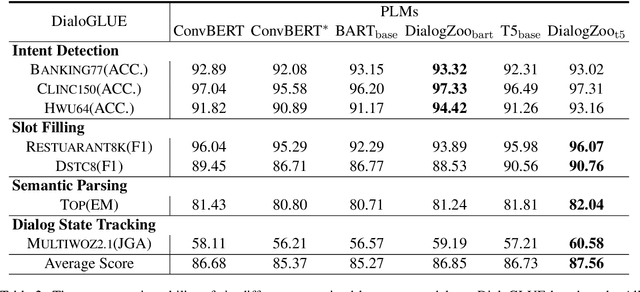
Building unified conversational agents has been a long-standing goal of the dialogue research community. Most previous works only focus on a subset of various dialogue tasks. In this work, we aim to build a unified foundation model which can solve massive diverse dialogue tasks. To achieve this goal, we first collect a large-scale well-labeled dialogue dataset from 73 publicly available datasets. In addition to this dataset, we further propose two dialogue-oriented self-supervised tasks, and finally use the mixture of supervised and self-supervised datasets to train our foundation model. The supervised examples make the model learn task-specific skills, while the self-supervised examples make the model learn more general skills. We evaluate our model on various downstream dialogue tasks. The experimental results show that our method not only improves the ability of dialogue generation and knowledge distillation, but also the representation ability of models.