 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPI: Efficient Protein Inference with Graph Neural Networks
May 06, 2026The integration of deep learning approaches in biomedical research has been transformative, enabling breakthroughs in various applications. Despite these strides, its application in protein inference is impeded by the scarcity of extensively labeled datasets, a challenge compounded by the high costs and complexities of accurate protein annotation. In this study, we introduce GraphPI, a novel framework that treats protein inference as a node classification problem. We treat proteins as interconnected nodes within a protein-peptide-PSM graph, utilizing a Graph Neural Network-based architecture to elucidate their interrelations. To address label scarcity, we train the model on a set of unlabeled public protein datasets with pseudo-labels derived from an existing protein inference algorithm, enhanced by self-training to iteratively refine labels based on confidence scores. Contrary to prevalent methodologies necessitating dataset-specific training, our research illustrates that GraphPI, due to the well normalized nature of Percolator features, exhibits universal applicability without dataset-specific fine-tuning, a feature that not only mitigates the risk of overfitting but also enhances computational efficiency. Our empirical experiments reveal notable performance on various test datasets and deliver significantly reduced computation times compared to common protein inference algorithms.
Token Reduction Should Go Beyond Efficiency in Generative Models -- From Vision, Language to Multimodality
May 23, 2025In Transformer architectures, tokens\textemdash discrete units derived from raw data\textemdash are formed by segmenting inputs into fixed-length chunks. Each token is then mapped to an embedding, enabling parallel attention computations while preserving the input's essential information. Due to the quadratic computational complexity of transformer self-attention mechanisms, token reduction has primarily been used as an efficiency strategy. This is especially true in single vision and language domains, where it helps balance computational costs, memory usage, and inference latency. Despite these advances, this paper argues that token reduction should transcend its traditional efficiency-oriented role in the era of large generative models. Instead, we position it as a fundamental principle in generative modeling, critically influencing both model architecture and broader applications. Specifically, we contend that across vision, language, and multimodal systems, token reduction can: (i) facilitate deeper multimodal integration and alignment, (ii) mitigate "overthinking" and hallucinations, (iii) maintain coherence over long inputs, and (iv) enhance training stability, etc. We reframe token reduction as more than an efficiency measure. By doing so, we outline promising future directions, including algorithm design, reinforcement learning-guided token reduction, token optimization for in-context learning, and broader ML and scientific domains. We highlight its potential to drive new model architectures and learning strategies that improve robustness, increase interpretability, and better align with the objectives of generative modeling.
Life-Code: Central Dogma Modeling with Multi-Omics Sequence Unification
Feb 11, 2025



The interactions between DNA, RNA, and proteins are fundamental to biological processes, as illustrated by the central dogma of molecular biology. While modern biological pre-trained models have achieved great success in analyzing these macromolecules individually, their interconnected nature remains under-explored. In this paper, we follow the guidance of the central dogma to redesign both the data and model pipeline and offer a comprehensive framework, Life-Code, that spans different biological functions. As for data flow, we propose a unified pipeline to integrate multi-omics data by reverse-transcribing RNA and reverse-translating amino acids into nucleotide-based sequences. As for the model, we design a codon tokenizer and a hybrid long-sequence architecture to encode the interactions of both coding and non-coding regions with masked modeling pre-training. To model the translation and folding process with coding sequences, Life-Code learns protein structures of the corresponding amino acids by knowledge distillation from off-the-shelf protein language models. Such designs enable Life-Code to capture complex interactions within genetic sequences, providing a more comprehensive understanding of multi-omics with the central dogma. Extensive Experiments show that Life-Code achieves state-of-the-art performance on various tasks across three omics, highlighting its potential for advancing multi-omics analysis and interpretation.
Disentangling the Complex Multiplexed DIA Spectra in De Novo Peptide Sequencing
Nov 24, 2024Data-Independent Acquisition (DIA) was introduced to improve sensitivity to cover all peptides in a range rather than only sampling high-intensity peaks as in Data-Dependent Acquisition (DDA) mass spectrometry. However, it is not very clear how useful DIA data is for de novo peptide sequencing as the DIA data are marred with coeluted peptides, high noises, and varying data quality. We present a new deep learning method DIANovo, and address each of these difficulties, and improves the previous established system DeepNovo-DIA by from 25% to 81%, averaging 48%, for amino acid recall, and by from 27% to 89%, averaging 57%, for peptide recall, by equipping the model with a deeper understanding of coeluted DIA spectra. This paper also provides criteria about when DIA data could be used for de novo peptide sequencing and when not to by providing a comparison between DDA and DIA, in both de novo and database search mode. We find that while DIA excels with narrow isolation windows on older-generation instruments, it loses its advantage with wider windows. However, with Orbitrap Astral, DIA consistently outperforms DDA due to narrow window mode enabled. We also provide a theoretical explanation of this phenomenon, emphasizing the critical role of the signal-to-noise profile in the successful application of de novo sequencing.
C3D: Cascade Control with Change Point Detection and Deep Koopman Learning for Autonomous Surface Vehicles
Mar 14, 2024In this paper, we discuss the development and deployment of a robust autonomous system capable of performing various tasks in the maritime domain under unknown dynamic conditions. We investigate a data-driven approach based on modular design for ease of transfer of autonomy across different maritime surface vessel platforms. The data-driven approach alleviates issues related to a priori identification of system models that may become deficient under evolving system behaviors or shifting, unanticipated, environmental influences. Our proposed learning-based platform comprises a deep Koopman system model and a change point detector that provides guidance on domain shifts prompting relearning under severe exogenous and endogenous perturbations. Motion control of the autonomous system is achieved via an optimal controller design. The Koopman linearized model naturally lends itself to a linear-quadratic regulator (LQR) control design. We propose the C3D control architecture Cascade Control with Change Point Detection and Deep Koopman Learning. The framework is verified in station keeping task on an ASV in both simulation and real experiments. The approach achieved at least 13.9 percent improvement in mean distance error in all test cases compared to the methods that do not consider system changes.
Modeling and Predicting Epidemic Spread: A Gaussian Process Regression Approach
Dec 14, 2023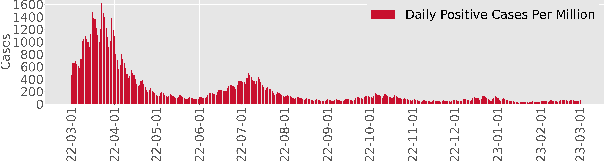
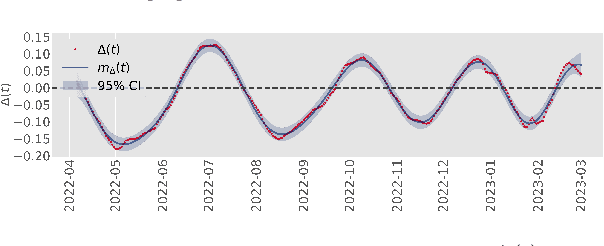
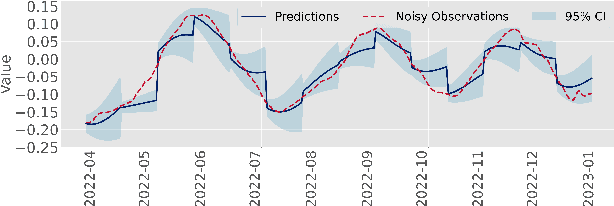
Modeling and prediction of epidemic spread are critical to assist in policy-making for mitigation. Therefore, we present a new method based on Gaussian Process Regression to model and predict epidemics, and it quantifies prediction confidence through variance and high probability error bounds. Gaussian Process Regression excels in using small datasets and providing uncertainty bounds, and both of these properties are critical in modeling and predicting epidemic spreading processes with limited data. However, the derivation of formal uncertainty bounds remains lacking when using Gaussian Process Regression in the setting of epidemics, which limits its usefulness in guiding mitigation efforts. Therefore, in this work, we develop a novel bound on the variance of the prediction that quantifies the impact of the epidemic data on the predictions we make. Further, we develop a high probability error bound on the prediction, and we quantify how the epidemic spread, the infection data, and the length of the prediction horizon all affect this error bound. We also show that the error stays below a certain threshold based on the length of the prediction horizon. To illustrate this framework, we leverage Gaussian Process Regression to model and predict COVID-19 using real-world infection data from the United Kingdom.
Online Change Points Detection for Linear Dynamical Systems with Finite Sample Guarantees
Nov 30, 2023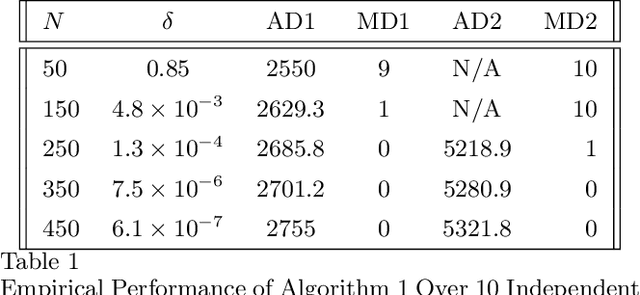
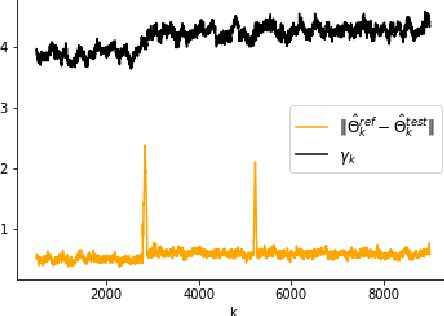
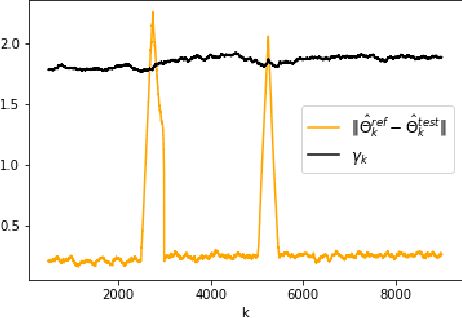
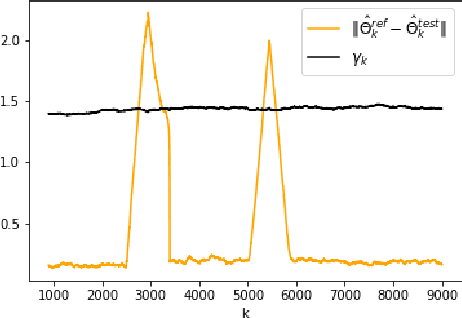
The problem of online change point detection is to detect abrupt changes in properties of time series, ideally as soon as possible after those changes occur. Existing work on online change point detection either assumes i.i.d data, focuses on asymptotic analysis, does not present theoretical guarantees on the trade-off between detection accuracy and detection delay, or is only suitable for detecting single change points. In this work, we study the online change point detection problem for linear dynamical systems with unknown dynamics, where the data exhibits temporal correlations and the system could have multiple change points. We develop a data-dependent threshold that can be used in our test that allows one to achieve a pre-specified upper bound on the probability of making a false alarm. We further provide a finite-sample-based bound for the probability of detecting a change point. Our bound demonstrates how parameters used in our algorithm affect the detection probability and delay, and provides guidance on the minimum required time between changes to guarantee detection.
Learning Linearized Models from Nonlinear Systems with Finite Data
Sep 15, 2023


Identifying a linear system model from data has wide applications in control theory. The existing work on finite sample analysis for linear system identification typically uses data from a single system trajectory under i.i.d random inputs, and assumes that the underlying dynamics is truly linear. In contrast, we consider the problem of identifying a linearized model when the true underlying dynamics is nonlinear. We provide a multiple trajectories-based deterministic data acquisition algorithm followed by a regularized least squares algorithm, and provide a finite sample error bound on the learned linearized dynamics. Our error bound demonstrates a trade-off between the error due to nonlinearity and the error due to noise, and shows that one can learn the linearized dynamics with arbitrarily small error given sufficiently many samples. We validate our results through experiments, where we also show the potential insufficiency of linear system identification using a single trajectory with i.i.d random inputs, when nonlinearity does exist.
Learning Dynamical Systems by Leveraging Data from Similar Systems
Feb 08, 2023



We consider the problem of learning the dynamics of a linear system when one has access to data generated by an auxiliary system that shares similar (but not identical) dynamics, in addition to data from the true system. We use a weighted least squares approach, and provide a finite sample error bound of the learned model as a function of the number of samples and various system parameters from the two systems as well as the weight assigned to the auxiliary data. We show that the auxiliary data can help to reduce the intrinsic system identification error due to noise, at the price of adding a portion of error that is due to the differences between the two system models. We further provide a data-dependent bound that is computable when some prior knowledge about the systems is available. This bound can also be used to determine the weight that should be assigned to the auxiliary data during the model training stage.
Finite Sample Guarantees for Distributed Online Parameter Estimation with Communication Costs
Sep 12, 2022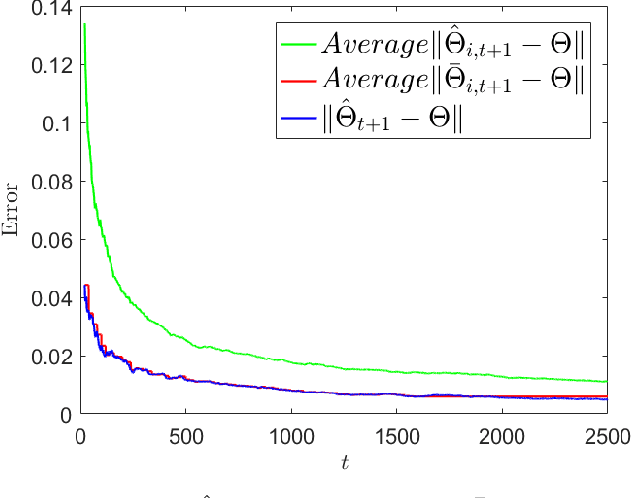
We study the problem of estimating an unknown parameter in a distributed and online manner. Existing work on distributed online learning typically either focuses on asymptotic analysis, or provides bounds on regret. However, these results may not directly translate into bounds on the error of the learned model after a finite number of time-steps. In this paper, we propose a distributed online estimation algorithm which enables each agent in a network to improve its estimation accuracy by communicating with neighbors. We provide non-asymptotic bounds on the estimation error, leveraging the statistical properties of the underlying model. Our analysis demonstrates a trade-off between estimation error and communication costs. Further, our analysis allows us to determine a time at which the communication can be stopped (due to the costs associated with communications), while meeting a desired estimation accuracy. We also provide a numerical example to validate our results.