 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sparsify Stochastic Linear Bandits
May 11, 2026This paper addresses the problem of learning to sparsify stochastic linear bandits, where a decision-maker sequentially selects actions from a high-dimensional space subject to a sparsity constraint on the number of nonzero elements in the action vector. The key challenge lies in minimizing cumulative regret while tackling the potential NP-hardness of finding optimal sparse actions due to the inherent combinatorial structure of the problem. We propose an adaptively phased exploration and exploitation algorithmic framework, utilizing ordinary least squares for parameter learning and specialized subroutines for sparse action selection. When the action set is a Euclidean ball, optimal sparse actions can be efficiently computed, enabling us to establish a $\tilde{\mathcal{O}}(d\sqrt{T})$ regret, where $d$ is the dimension of the action vector and $T$ is the time horizon length. For general convex and compact action sets where finding optimal sparse actions is intractable, we employ a greedy subroutine. For general strongly convex action sets, we derive a $\tilde{\mathcal{O}}(d \sqrt{T})$ $α$-regret; for general compact sets lacking strong convexity, we establish a $\tilde{\mathcal{O}}(d T^{2/3})$ $α$-regret, where $α$ pertains to the approximation ratio of the greedy algorithm. Finally, we validate the performance of our algorithms using extensive experiments including an application to recommendation system.
Online Learning of Kalman Filtering: From Output to State Estimation
Mar 28, 2026In this paper, we study the problem of learning Kalman filtering with unknown system model in partially observed linear dynamical systems. We propose a unified algorithmic framework based on online optimization that can be used to solve both the output estimation and state estimation scenarios. By exploring the properties of the estimation error cost functions, such as conditionally strong convexity, we show that our algorithm achieves a $\log T$-regret in the horizon length $T$ for the output estimation scenario. More importantly, we tackle the more challenging scenario of learning Kalman filtering for state estimation, which is an open problem in the literature. We first characterize a fundamental limitation of the problem, demonstrating the impossibility of any algorithm to achieve sublinear regret in $T$. By further introducing a random query scheme into our algorithm, we show that a $\sqrt{T}$-regret is achievable when rendering the algorithm limited query access to more informative measurements of the system state in practice. Our algorithm and regret readily capture the trade-off between the number of queries and the achieved regret, and shed light on online learning problems with limited observations. We validate the performance of our algorithms using numerical examples.
Model-Free Output Feedback Stabilization via Policy Gradient Methods
Jan 29, 2026Stabilizing a dynamical system is a fundamental problem that serves as a cornerstone for many complex tasks in the field of control systems. The problem becomes challenging when the system model is unknown. Among the Reinforcement Learning (RL) algorithms that have been successfully applied to solve problems pertaining to unknown linear dynamical systems, the policy gradient (PG) method stands out due to its ease of implementation and can solve the problem in a model-free manner. However, most of the existing works on PG methods for unknown linear dynamical systems assume full-state feedback. In this paper, we take a step towards model-free learning for partially observable linear dynamical systems with output feedback and focus on the fundamental stabilization problem of the system. We propose an algorithmic framework that stretches the boundary of PG methods to the problem without global convergence guarantees. We show that by leveraging zeroth-order PG update based on system trajectories and its convergence to stationary points, the proposed algorithms return a stabilizing output feedback policy for discrete-time linear dynamical systems. We also explicitly characterize the sample complexity of our algorithm and verify the effectiveness of the algorithm using numerical examples.
Output Feedback Stabilization of Linear Systems via Policy Gradient Methods
Jan 27, 2026Stabilizing a dynamical system is a fundamental problem that serves as a cornerstone for many complex tasks in the field of control systems. The problem becomes challenging when the system model is unknown. Among the Reinforcement Learning (RL) algorithms that have been successfully applied to solve problems pertaining to unknown linear dynamical systems, the policy gradient (PG) method stands out due to its ease of implementation and can solve the problem in a model-free manner. However, most of the existing works on PG methods for unknown linear dynamical systems assume full-state feedback. In this paper, we take a step towards model-free learning for partially observable linear dynamical systems with output feedback and focus on the fundamental stabilization problem of the system. We propose an algorithmic framework that stretches the boundary of PG methods to the problem without global convergence guarantees. We show that by leveraging zeroth-order PG update based on system trajectories and its convergence to stationary points, the proposed algorithms return a stabilizing output feedback policy for discrete-time linear dynamical systems. We also explicitly characterize the sample complexity of our algorithm and verify the effectiveness of the algorithm using numerical examples.
Learning Stabilizing Policies via an Unstable Subspace Representation
May 02, 2025
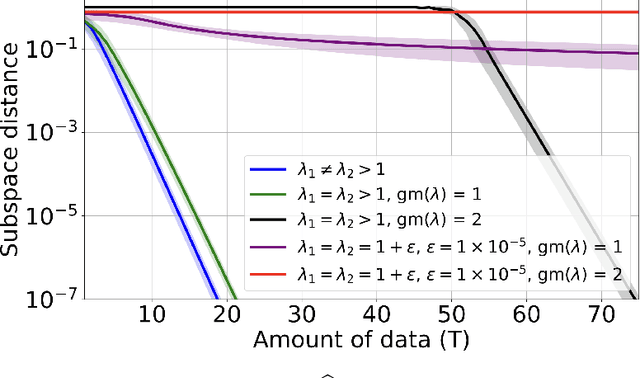
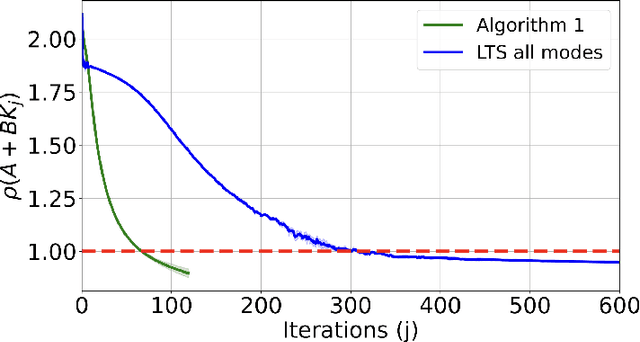
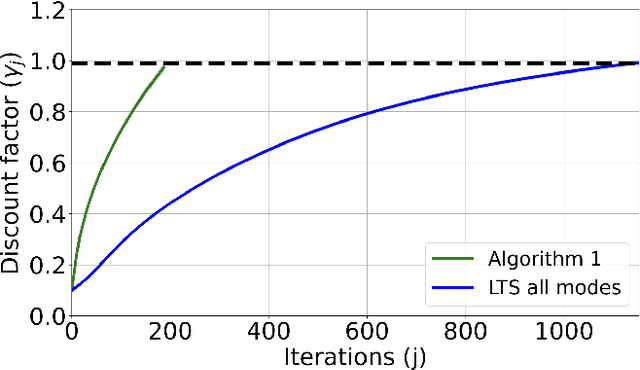
We study the problem of learning to stabilize (LTS) a linear time-invariant (LTI) system. Policy gradient (PG) methods for control assume access to an initial stabilizing policy. However, designing such a policy for an unknown system is one of the most fundamental problems in control, and it may be as hard as learning the optimal policy itself. Existing work on the LTS problem requires large data as it scales quadratically with the ambient dimension. We propose a two-phase approach that first learns the left unstable subspace of the system and then solves a series of discounted linear quadratic regulator (LQR) problems on the learned unstable subspace, targeting to stabilize only the system's unstable dynamics and reduce the effective dimension of the control space. We provide non-asymptotic guarantees for both phases and demonstrate that operating on the unstable subspace reduces sample complexity. In particular, when the number of unstable modes is much smaller than the state dimension, our analysis reveals that LTS on the unstable subspace substantially speeds up the stabilization process. Numerical experiments are provided to support this sample complexity reduction achieved by our approach.
Online Convex Optimization with Memory and Limited Predictions
Oct 31, 2024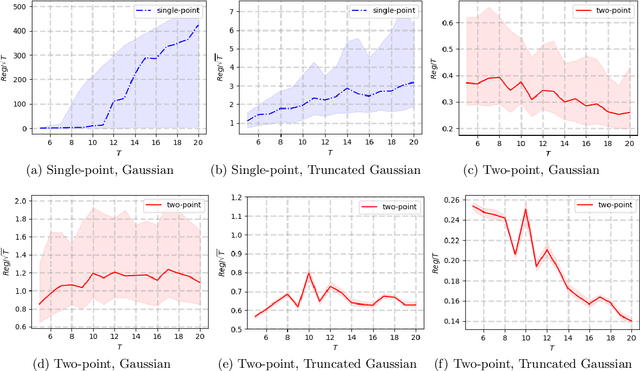
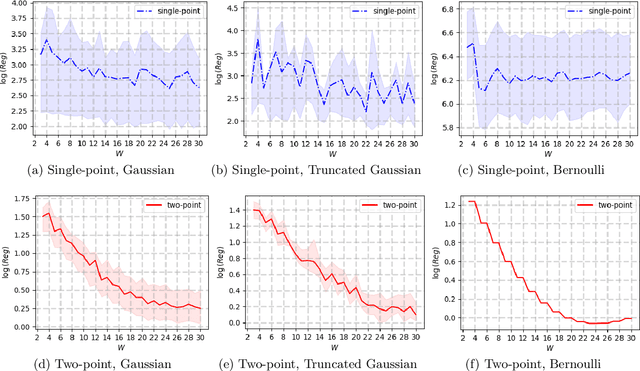
We study the problem of online convex optimization with memory and predictions over a horizon $T$. At each time step, a decision maker is given some limited predictions of the cost functions from a finite window of future time steps, i.e., values of the cost function at certain decision points in the future. The decision maker then chooses an action and incurs a cost given by a convex function that depends on the actions chosen in the past. We propose an algorithm to solve this problem and show that the dynamic regret of the algorithm decays exponentially with the prediction window length. Our algorithm contains two general subroutines that work for wider classes of problems. The first subroutine can solve general online convex optimization with memory and bandit feedback with $\sqrt{T}$-dynamic regret with respect to $T$. The second subroutine is a zeroth-order method that can be used to solve general convex optimization problems with a linear convergence rate that matches the best achievable rate of first-order methods for convex optimization. The key to our algorithm design and analysis is the use of truncated Gaussian smoothing when querying the decision points for obtaining the predictions. We complement our theoretical results using numerical experiments.
Submodular Maximization Approaches for Equitable Client Selection in Federated Learning
Aug 24, 2024


In a conventional Federated Learning framework, client selection for training typically involves the random sampling of a subset of clients in each iteration. However, this random selection often leads to disparate performance among clients, raising concerns regarding fairness, particularly in applications where equitable outcomes are crucial, such as in medical or financial machine learning tasks. This disparity typically becomes more pronounced with the advent of performance-centric client sampling techniques. This paper introduces two novel methods, namely SUBTRUNC and UNIONFL, designed to address the limitations of random client selection. Both approaches utilize submodular function maximization to achieve more balanced models. By modifying the facility location problem, they aim to mitigate the fairness concerns associated with random selection. SUBTRUNC leverages client loss information to diversify solutions, while UNIONFL relies on historical client selection data to ensure a more equitable performance of the final model. Moreover, these algorithms are accompanied by robust theoretical guarantees regarding convergence under reasonable assumptions. The efficacy of these methods is demonstrated through extensive evaluations across heterogeneous scenarios, revealing significant improvements in fairness as measured by a client dissimilarity metric.
Towards Model-Free LQR Control over Rate-Limited Channels
Jan 02, 2024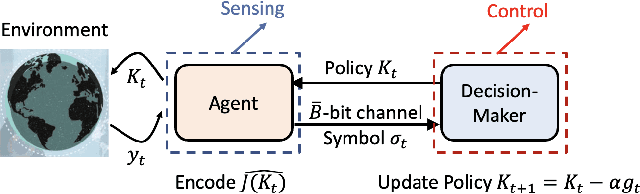
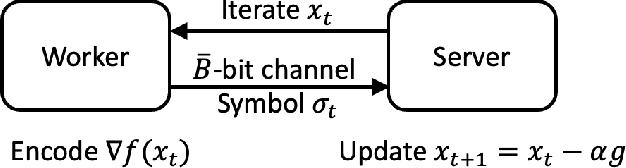
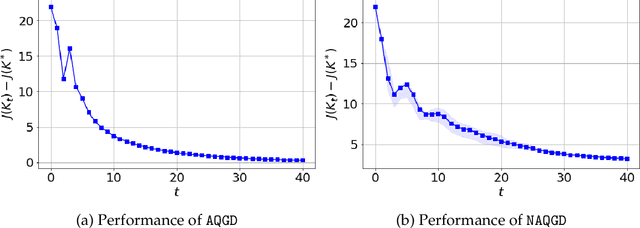
Given the success of model-free methods for control design in many problem settings, it is natural to ask how things will change if realistic communication channels are utilized for the transmission of gradients or policies. While the resulting problem has analogies with the formulations studied under the rubric of networked control systems, the rich literature in that area has typically assumed that the model of the system is known. As a step towards bridging the fields of model-free control design and networked control systems, we ask: \textit{Is it possible to solve basic control problems - such as the linear quadratic regulator (LQR) problem - in a model-free manner over a rate-limited channel?} Toward answering this question, we study a setting where a worker agent transmits quantized policy gradients (of the LQR cost) to a server over a noiseless channel with a finite bit-rate. We propose a new algorithm titled Adaptively Quantized Gradient Descent (\texttt{AQGD}), and prove that above a certain finite threshold bit-rate, \texttt{AQGD} guarantees exponentially fast convergence to the globally optimal policy, with \textit{no deterioration of the exponent relative to the unquantized setting}. More generally, our approach reveals the benefits of adaptive quantization in preserving fast linear convergence rates, and, as such, may be of independent interest to the literature on compressed optimization.
Learning Dynamical Systems by Leveraging Data from Similar Systems
Feb 08, 2023



We consider the problem of learning the dynamics of a linear system when one has access to data generated by an auxiliary system that shares similar (but not identical) dynamics, in addition to data from the true system. We use a weighted least squares approach, and provide a finite sample error bound of the learned model as a function of the number of samples and various system parameters from the two systems as well as the weight assigned to the auxiliary data. We show that the auxiliary data can help to reduce the intrinsic system identification error due to noise, at the price of adding a portion of error that is due to the differences between the two system models. We further provide a data-dependent bound that is computable when some prior knowledge about the systems is available. This bound can also be used to determine the weight that should be assigned to the auxiliary data during the model training stage.
Regret Bounds for Learning Decentralized Linear Quadratic Regulator with Partially Nested Information Structure
Oct 17, 2022
We study the problem of learning decentralized linear quadratic regulator under a partially nested information constraint, when the system model is unknown a priori. We propose an online learning algorithm that adaptively designs a control policy as new data samples from a single system trajectory become available. Our algorithm design uses a disturbance-feedback representation of state-feedback controllers coupled with online convex optimization with memory and delayed feedback. We show that our online algorithm yields a controller that satisfies the desired information constraint and enjoys an expected regret that scales as $\sqrt{T}$ with the time horizon $T$.