 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Convex Optimization with Memory and Limited Predictions
Paper and Code
Oct 31, 2024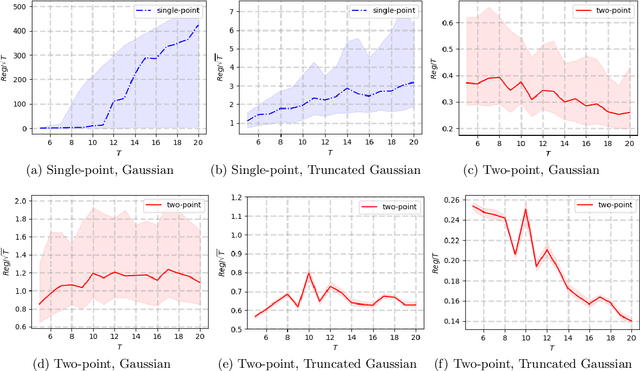
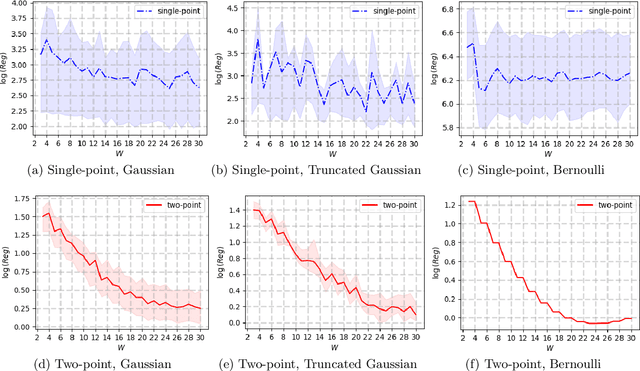
We study the problem of online convex optimization with memory and predictions over a horizon $T$. At each time step, a decision maker is given some limited predictions of the cost functions from a finite window of future time steps, i.e., values of the cost function at certain decision points in the future. The decision maker then chooses an action and incurs a cost given by a convex function that depends on the actions chosen in the past. We propose an algorithm to solve this problem and show that the dynamic regret of the algorithm decays exponentially with the prediction window length. Our algorithm contains two general subroutines that work for wider classes of problems. The first subroutine can solve general online convex optimization with memory and bandit feedback with $\sqrt{T}$-dynamic regret with respect to $T$. The second subroutine is a zeroth-order method that can be used to solve general convex optimization problems with a linear convergence rate that matches the best achievable rate of first-order methods for convex optimization. The key to our algorithm design and analysis is the use of truncated Gaussian smoothing when querying the decision points for obtaining the predictions. We complement our theoretical results using numerical experiments.