 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Multitask Adaptive Control
Nov 07, 2025We study adversarially robust multitask adaptive linear quadratic control; a setting where multiple systems collaboratively learn control policies under model uncertainty and adversarial corruption. We propose a clustered multitask approach that integrates clustering and system identification with resilient aggregation to mitigate corrupted model updates. Our analysis characterizes how clustering accuracy, intra-cluster heterogeneity, and adversarial behavior affect the expected regret of certainty-equivalent (CE) control across LQR tasks. We establish non-asymptotic bounds demonstrating that the regret decreases inversely with the number of honest systems per cluster and that this reduction is preserved under a bounded fraction of adversarial systems within each cluster.
Learning Stabilizing Policies via an Unstable Subspace Representation
May 02, 2025
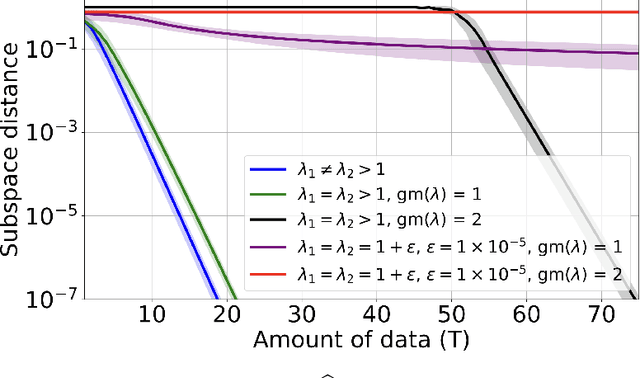
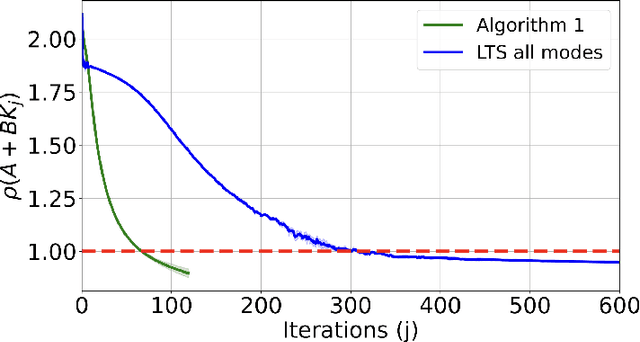
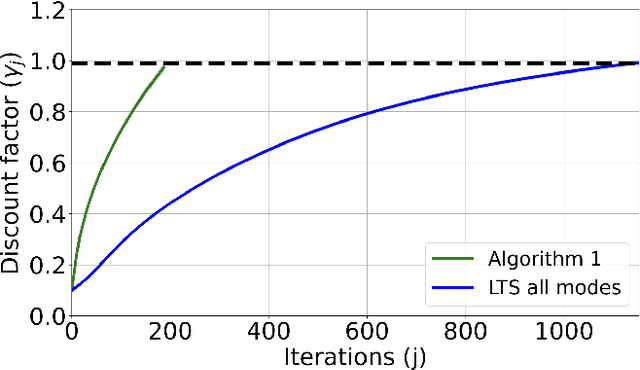
We study the problem of learning to stabilize (LTS) a linear time-invariant (LTI) system. Policy gradient (PG) methods for control assume access to an initial stabilizing policy. However, designing such a policy for an unknown system is one of the most fundamental problems in control, and it may be as hard as learning the optimal policy itself. Existing work on the LTS problem requires large data as it scales quadratically with the ambient dimension. We propose a two-phase approach that first learns the left unstable subspace of the system and then solves a series of discounted linear quadratic regulator (LQR) problems on the learned unstable subspace, targeting to stabilize only the system's unstable dynamics and reduce the effective dimension of the control space. We provide non-asymptotic guarantees for both phases and demonstrate that operating on the unstable subspace reduces sample complexity. In particular, when the number of unstable modes is much smaller than the state dimension, our analysis reveals that LTS on the unstable subspace substantially speeds up the stabilization process. Numerical experiments are provided to support this sample complexity reduction achieved by our approach.
Coreset-Based Task Selection for Sample-Efficient Meta-Reinforcement Learning
Feb 04, 2025


We study task selection to enhance sample efficiency in model-agnostic meta-reinforcement learning (MAML-RL). Traditional meta-RL typically assumes that all available tasks are equally important, which can lead to task redundancy when they share significant similarities. To address this, we propose a coreset-based task selection approach that selects a weighted subset of tasks based on how diverse they are in gradient space, prioritizing the most informative and diverse tasks. Such task selection reduces the number of samples needed to find an $\epsilon$-close stationary solution by a factor of O(1/$\epsilon$). Consequently, it guarantees a faster adaptation to unseen tasks while focusing training on the most relevant tasks. As a case study, we incorporate task selection to MAML-LQR (Toso et al., 2024b), and prove a sample complexity reduction proportional to O(log(1/$\epsilon$)) when the task specific cost also satisfy gradient dominance. Our theoretical guarantees underscore task selection as a key component for scalable and sample-efficient meta-RL. We numerically validate this trend across multiple RL benchmark problems, illustrating the benefits of task selection beyond the LQR baseline.
Regret Analysis of Multi-task Representation Learning for Linear-Quadratic Adaptive Control
Jul 08, 2024Representation learning is a powerful tool that enables learning over large multitudes of agents or domains by enforcing that all agents operate on a shared set of learned features. However, many robotics or controls applications that would benefit from collaboration operate in settings with changing environments and goals, whereas most guarantees for representation learning are stated for static settings. Toward rigorously establishing the benefit of representation learning in dynamic settings, we analyze the regret of multi-task representation learning for linear-quadratic control. This setting introduces unique challenges. Firstly, we must account for and balance the $\textit{misspecification}$ introduced by an approximate representation. Secondly, we cannot rely on the parameter update schemes of single-task online LQR, for which least-squares often suffices, and must devise a novel scheme to ensure sufficient improvement. We demonstrate that for settings where exploration is "benign", the regret of any agent after $T$ timesteps scales as $\tilde O(\sqrt{T/H})$, where $H$ is the number of agents. In settings with "difficult" exploration, the regret scales as $\tilde{\mathcal O}(\sqrt{d_u d_\theta} \sqrt{T} + T^{3/4}/H^{1/5})$, where $d_x$ is the state-space dimension, $d_u$ is the input dimension, and $d_\theta$ is the task-specific parameter count. In both cases, by comparing to the minimax single-task regret $\tilde{\mathcal O}(\sqrt{d_x d_u^2}\sqrt{T})$, we see a benefit of a large number of agents. Notably, in the difficult exploration case, by sharing a representation across tasks, the effective task-specific parameter count can often be small $d_\theta < d_x d_u$. Lastly, we provide numerical validation of the trends we predict.
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for the Model-free LQR
Jan 25, 2024
We investigate the problem of learning Linear Quadratic Regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a Policy Gradient-based (PG) Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that the MAML-LQR approach produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias for both model-based and model-free settings. Moreover, in the model-based setting, we show that this controller is achieved with a linear convergence rate, which improves upon sub-linear rates presented in existing MAML-LQR work. In contrast to existing MAML-LQR results, our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
Oracle Complexity Reduction for Model-free LQR: A Stochastic Variance-Reduced Policy Gradient Approach
Sep 19, 2023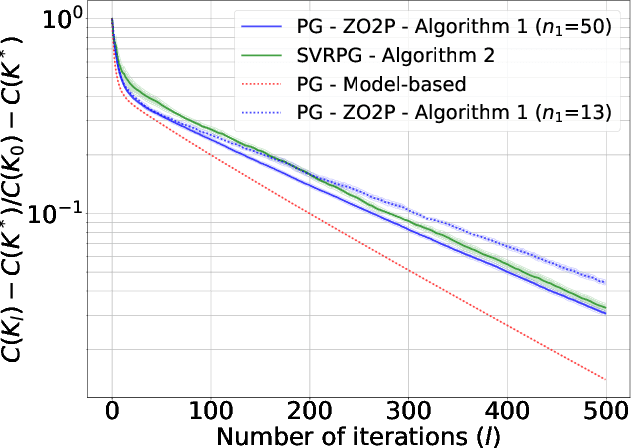

We investigate the problem of learning an $\epsilon$-approximate solution for the discrete-time Linear Quadratic Regulator (LQR) problem via a Stochastic Variance-Reduced Policy Gradient (SVRPG) approach. Whilst policy gradient methods have proven to converge linearly to the optimal solution of the model-free LQR problem, the substantial requirement for two-point cost queries in gradient estimations may be intractable, particularly in applications where obtaining cost function evaluations at two distinct control input configurations is exceptionally costly. To this end, we propose an oracle-efficient approach. Our method combines both one-point and two-point estimations in a dual-loop variance-reduced algorithm. It achieves an approximate optimal solution with only $O\left(\log\left(1/\epsilon\right)^{\beta}\right)$ two-point cost information for $\beta \in (0,1)$.
Meta-Learning Operators to Optimality from Multi-Task Non-IID Data
Aug 08, 2023



A powerful concept behind much of the recent progress in machine learning is the extraction of common features across data from heterogeneous sources or tasks. Intuitively, using all of one's data to learn a common representation function benefits both computational effort and statistical generalization by leaving a smaller number of parameters to fine-tune on a given task. Toward theoretically grounding these merits, we propose a general setting of recovering linear operators $M$ from noisy vector measurements $y = Mx + w$, where the covariates $x$ may be both non-i.i.d. and non-isotropic. We demonstrate that existing isotropy-agnostic meta-learning approaches incur biases on the representation update, which causes the scaling of the noise terms to lose favorable dependence on the number of source tasks. This in turn can cause the sample complexity of representation learning to be bottlenecked by the single-task data size. We introduce an adaptation, $\texttt{De-bias & Feature-Whiten}$ ($\texttt{DFW}$), of the popular alternating minimization-descent (AMD) scheme proposed in Collins et al., (2021), and establish linear convergence to the optimal representation with noise level scaling down with the $\textit{total}$ source data size. This leads to generalization bounds on the same order as an oracle empirical risk minimizer. We verify the vital importance of $\texttt{DFW}$ on various numerical simulations. In particular, we show that vanilla alternating-minimization descent fails catastrophically even for iid, but mildly non-isotropic data. Our analysis unifies and generalizes prior work, and provides a flexible framework for a wider range of applications, such as in controls and dynamical systems.
Learning Personalized Models with Clustered System Identification
Apr 03, 2023We address the problem of learning linear system models from observing multiple trajectories from different system dynamics. This framework encompasses a collaborative scenario where several systems seeking to estimate their dynamics are partitioned into clusters according to their system similarity. Thus, the systems within the same cluster can benefit from the observations made by the others. Considering this framework, we present an algorithm where each system alternately estimates its cluster identity and performs an estimation of its dynamics. This is then aggregated to update the model of each cluster. We show that under mild assumptions, our algorithm correctly estimates the cluster identities and achieves an approximate sample complexity that scales inversely with the number of systems in the cluster, thus facilitating a more efficient and personalized system identification process.
FedSysID: A Federated Approach to Sample-Efficient System Identification
Nov 25, 2022


We study the problem of learning a linear system model from the observations of $M$ clients. The catch: Each client is observing data from a different dynamical system. This work addresses the question of how multiple clients collaboratively learn dynamical models in the presence of heterogeneity. We pose this problem as a federated learning problem and characterize the tension between achievable performance and system heterogeneity. Furthermore, our federated sample complexity result provides a constant factor improvement over the single agent setting. Finally, we describe a meta federated learning algorithm, FedSysID, that leverages existing federated algorithms at the client level.