 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Backdoor Attack in Decentralized Reinforcement Learning with Theoretical Guarantee
Paper and Code
May 24, 2024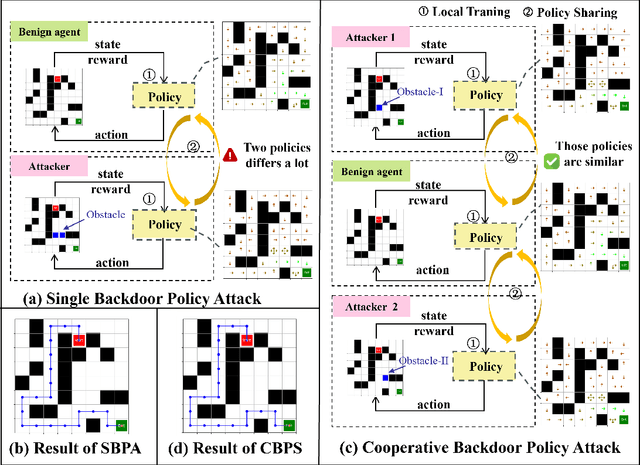
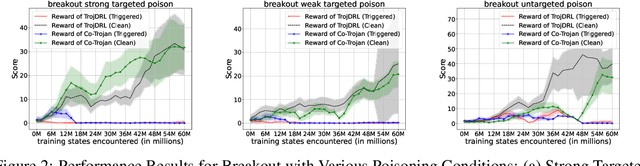
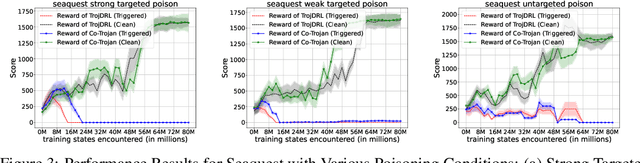
The safety of decentralized reinforcement learning (RL) is a challenging problem since malicious agents can share their poisoned policies with benign agents. The paper investigates a cooperative backdoor attack in a decentralized reinforcement learning scenario. Differing from the existing methods that hide a whole backdoor attack behind their shared policies, our method decomposes the backdoor behavior into multiple components according to the state space of RL. Each malicious agent hides one component in its policy and shares its policy with the benign agents. When a benign agent learns all the poisoned policies, the backdoor attack is assembled in its policy. The theoretical proof is given to show that our cooperative method can successfully inject the backdoor into the RL policies of benign agents. Compared with the existing backdoor attacks, our cooperative method is more covert since the policy from each attacker only contains a component of the backdoor attack and is harder to detect. Extensive simulations are conducted based on Atari environments to demonstrate the efficiency and covertness of our method. To the best of our knowledge, this is the first paper presenting a provable cooperative backdoor attack in decentralized reinforcement learning.