Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Reinforcement Learning for Quadrotor UAV
Paper and Code
Jun 02, 2022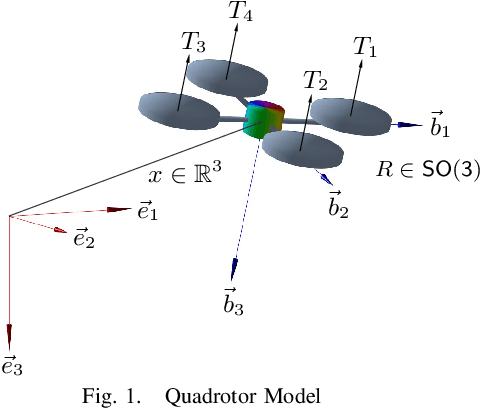
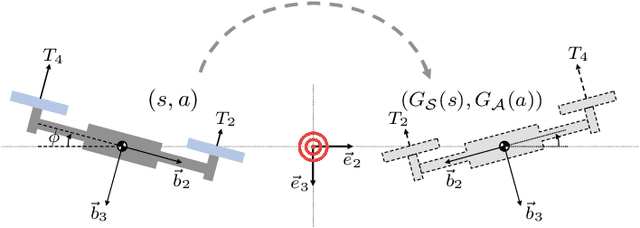
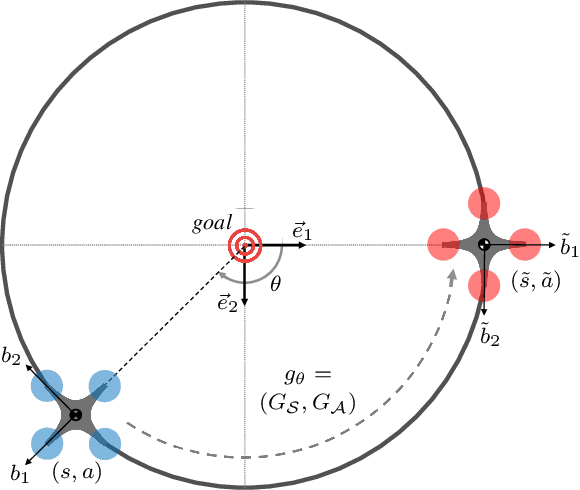
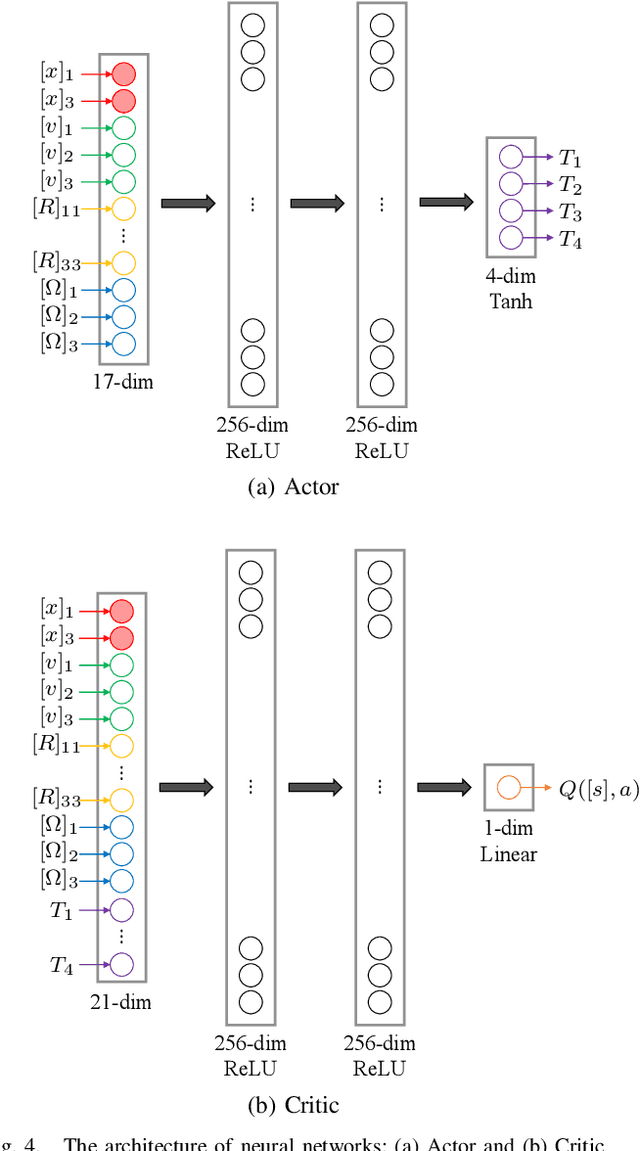
This paper presents an equivariant reinforcement learning framework for quadrotor unmanned aerial vehicles. Successful training of reinforcement learning often requires numerous interactions with the environments, which hinders its applicability especially when the available computational resources are limited, or when there is no reliable simulation model. We identified an equivariance property of the quadrotor dynamics such that the dimension of the state required in the training is reduced by one, thereby improving the sampling efficiency of reinforcement learning substantially. This is illustrated by numerical examples with popular reinforcement learning techniques of TD3 and SAC.
* 7 pages, 7 figures
View paper on