 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
CREStE: Scalable Mapless Navigation with Internet Scale Priors and Counterfactual Guidance
Mar 05, 2025We address the long-horizon mapless navigation problem: enabling robots to traverse novel environments without relying on high-definition maps or precise waypoints that specify exactly where to navigate. Achieving this requires overcoming two major challenges -- learning robust, generalizable perceptual representations of the environment without pre-enumerating all possible navigation factors and forms of perceptual aliasing and utilizing these learned representations to plan human-aligned navigation paths. Existing solutions struggle to generalize due to their reliance on hand-curated object lists that overlook unforeseen factors, end-to-end learning of navigation features from scarce large-scale robot datasets, and handcrafted reward functions that scale poorly to diverse scenarios. To overcome these limitations, we propose CREStE, the first method that learns representations and rewards for addressing the full mapless navigation problem without relying on large-scale robot datasets or manually curated features. CREStE leverages visual foundation models trained on internet-scale data to learn continuous bird's-eye-view representations capturing elevation, semantics, and instance-level features. To utilize learned representations for planning, we propose a counterfactual-based loss and active learning procedure that focuses on the most salient perceptual cues by querying humans for counterfactual trajectory annotations in challenging scenes. We evaluate CREStE in kilometer-scale navigation tasks across six distinct urban environments. CREStE significantly outperforms all state-of-the-art approaches with 70% fewer human interventions per mission, including a 2-kilometer mission in an unseen environment with just 1 intervention; showcasing its robustness and effectiveness for long-horizon mapless navigation. For videos and additional materials, see https://amrl.cs.utexas.edu/creste .
Lift, Splat, Map: Lifting Foundation Masks for Label-Free Semantic Scene Completion
Jul 03, 2024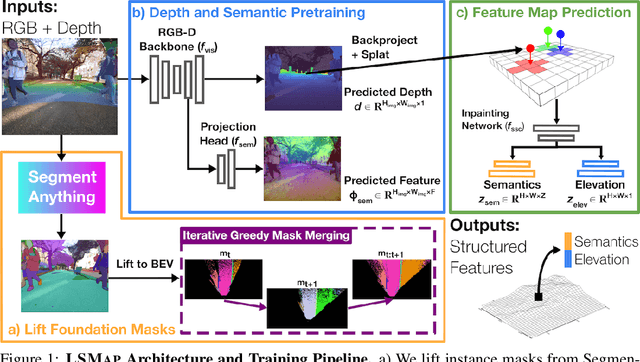
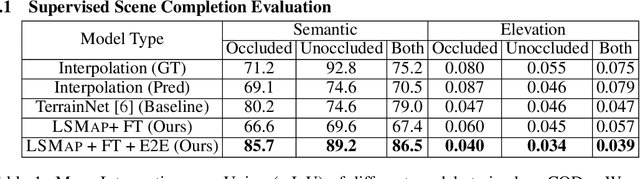
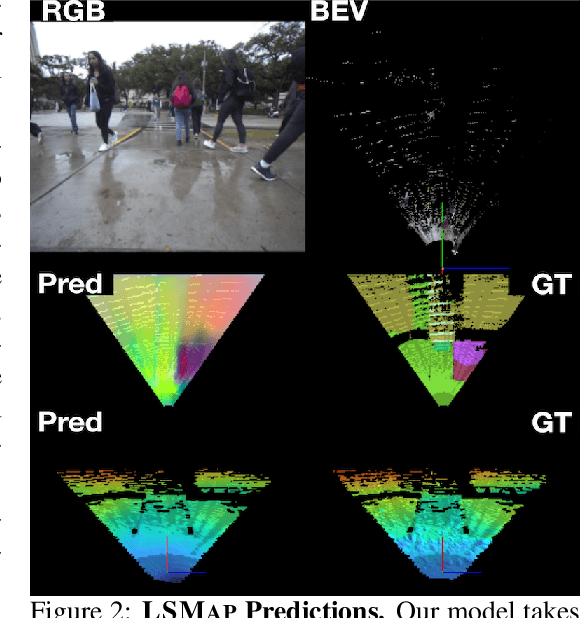

Autonomous mobile robots deployed in urban environments must be context-aware, i.e., able to distinguish between different semantic entities, and robust to occlusions. Current approaches like semantic scene completion (SSC) require pre-enumerating the set of classes and costly human annotations, while representation learning methods relax these assumptions but are not robust to occlusions and learn representations tailored towards auxiliary tasks. To address these limitations, we propose LSMap, a method that lifts masks from visual foundation models to predict a continuous, open-set semantic and elevation-aware representation in bird's eye view (BEV) for the entire scene, including regions underneath dynamic entities and in occluded areas. Our model only requires a single RGBD image, does not require human labels, and operates in real time. We quantitatively demonstrate our approach outperforms existing models trained from scratch on semantic and elevation scene completion tasks with finetuning. Furthermore, we show that our pre-trained representation outperforms existing visual foundation models at unsupervised semantic scene completion. We evaluate our approach using CODa, a large-scale, real-world urban robot dataset. Supplementary visualizations, code, data, and pre-trained models, will be publicly available soon.
Whole-body Humanoid Robot Locomotion with Human Reference
Mar 01, 2024
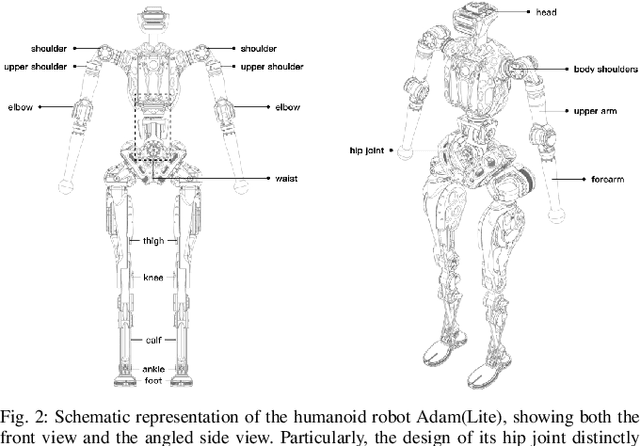
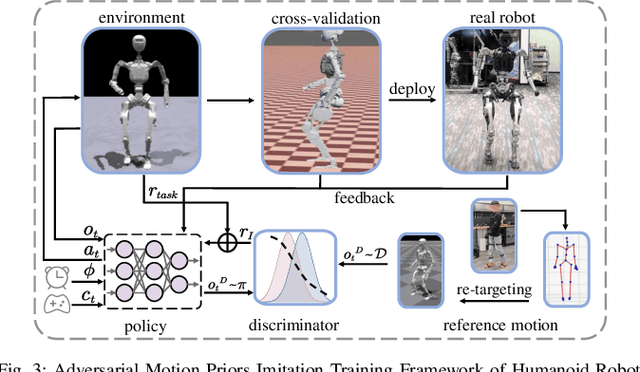
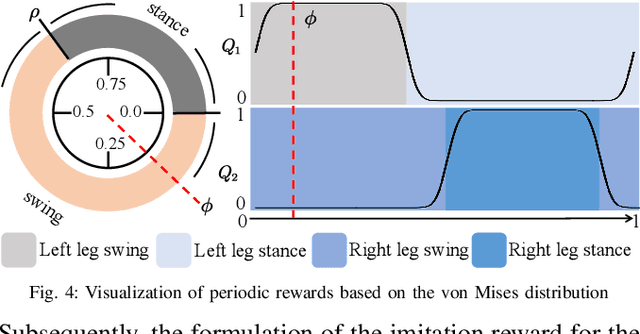
Recently, humanoid robots have made significant advances in their ability to perform challenging tasks due to the deployment of Reinforcement Learning (RL), however, the inherent complexity of humanoid robots, including the difficulty of designing complicated reward functions and training entire sophisticated systems, still poses a notable challenge. To conquer these challenges, after many iterations and in-depth investigations, we have meticulously developed a full-size humanoid robot, "Adam", whose innovative structural design greatly improves the efficiency and effectiveness of the imitation learning process. In addition, we have developed a novel imitation learning framework based on an adversarial motion prior, which applies not only to Adam but also to humanoid robots in general. Using the framework, Adam can exhibit unprecedented human-like characteristics in locomotion tasks. Our experimental results demonstrate that the proposed framework enables Adam to achieve human-comparable performance in complex locomotion tasks, marking the first time that human locomotion data has been used for imitation learning in a full-size humanoid robot.
Looking Inside Out: Anticipating Driver Intent From Videos
Dec 03, 2023



Anticipating driver intention is an important task when vehicles of mixed and varying levels of human/machine autonomy share roadways. Driver intention can be leveraged to improve road safety, such as warning surrounding vehicles in the event the driver is attempting a dangerous maneuver. In this work, we propose a novel method of utilizing in-cabin and external camera data to improve state-of-the-art (SOTA) performance in predicting future driver actions. Compared to existing methods, our approach explicitly extracts object and road-level features from external camera data, which we demonstrate are important features for predicting driver intention. Using our handcrafted features as inputs for both a transformer and an LSTM-based architecture, we empirically show that jointly utilizing in-cabin and external features improves performance compared to using in-cabin features alone. Furthermore, our models predict driver maneuvers more accurately and earlier than existing approaches, with an accuracy of 87.5% and an average prediction time of 4.35 seconds before the maneuver takes place. We release our model configurations and training scripts on https://github.com/ykung83/Driver-Intent-Prediction
Towards Robust Robot 3D Perception in Urban Environments: The UT Campus Object Dataset
Oct 01, 2023



We introduce the UT Campus Object Dataset (CODa), a mobile robot egocentric perception dataset collected on the University of Texas Austin Campus. Our dataset contains 8.5 hours of multimodal sensor data: synchronized 3D point clouds and stereo RGB video from a 128-channel 3D LiDAR and two 1.25MP RGB cameras at 10 fps; RGB-D videos from an additional 0.5MP sensor at 7 fps, and a 9-DOF IMU sensor at 40 Hz. We provide 58 minutes of ground-truth annotations containing 1.3 million 3D bounding boxes with instance IDs for 53 semantic classes, 5000 frames of 3D semantic annotations for urban terrain, and pseudo-ground truth localization. We repeatedly traverse identical geographic locations for a wide range of indoor and outdoor areas, weather conditions, and times of the day. Using CODa, we empirically demonstrate that: 1) 3D object detection performance in urban settings is significantly higher when trained using CODa compared to existing datasets even when employing state-of-the-art domain adaptation approaches, 2) sensor-specific fine-tuning improves 3D object detection accuracy and 3) pretraining on CODa improves cross-dataset 3D object detection performance in urban settings compared to pretraining on AV datasets. Using our dataset and annotations, we release benchmarks for 3D object detection and 3D semantic segmentation using established metrics. In the future, the CODa benchmark will include additional tasks like unsupervised object discovery and re-identification. We publicly release CODa on the Texas Data Repository, pre-trained models, dataset development package, and interactive dataset viewer on our website at https://amrl.cs.utexas.edu/coda. We expect CODa to be a valuable dataset for research in egocentric 3D perception and planning for autonomous navigation in urban environments.
Convolutional Bayesian Kernel Inference for 3D Semantic Mapping
Sep 21, 2022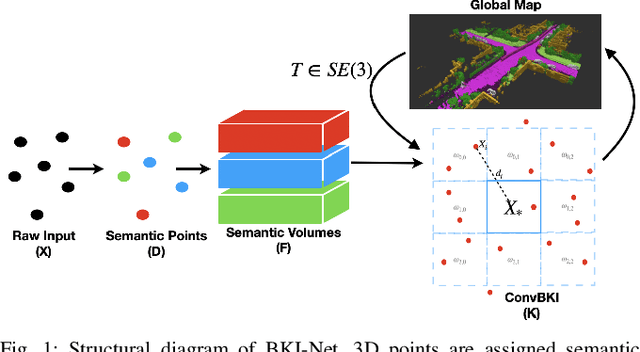
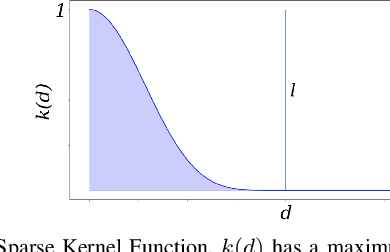
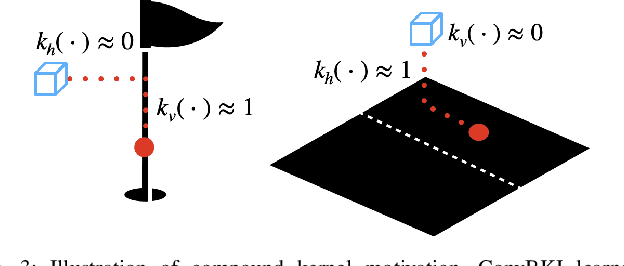
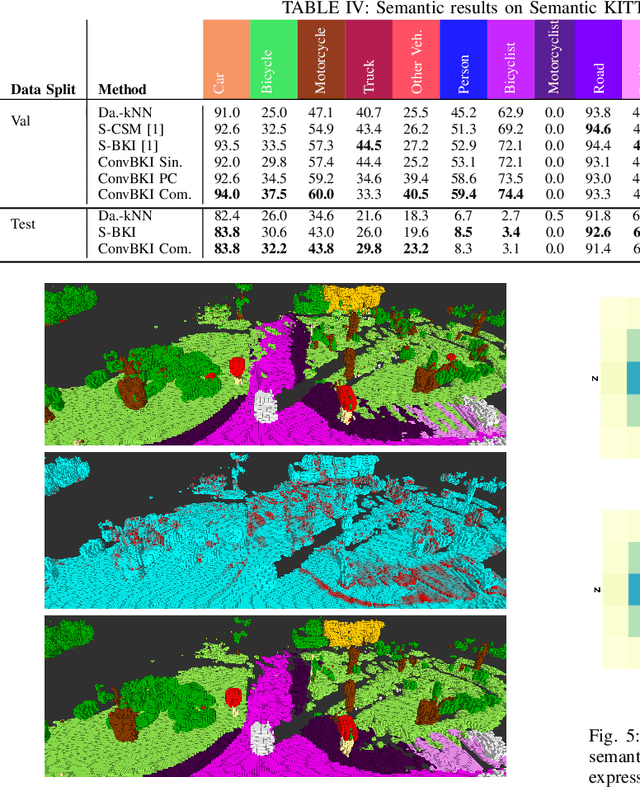
Robotic perception is currently at a cross-roads between modern methods which operate in an efficient latent space, and classical methods which are mathematically founded and provide interpretable, trustworthy results. In this paper, we introduce a Convolutional Bayesian Kernel Inference (ConvBKI) layer which explicitly performs Bayesian inference within a depthwise separable convolution layer to simultaneously maximize efficiency while maintaining reliability. We apply our layer to the task of 3D semantic mapping, where we learn semantic-geometric probability distributions for LiDAR sensor information in real time. We evaluate our network against state-of-the-art semantic mapping algorithms on the KITTI data set, and demonstrate improved latency with comparable semantic results.
MotionSC: Data Set and Network for Real-Time Semantic Mapping in Dynamic Environments
Mar 14, 2022
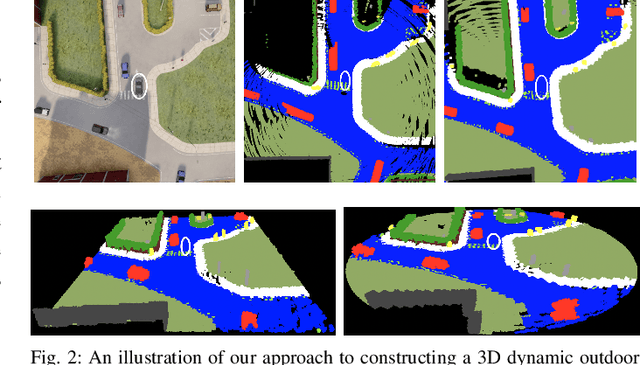

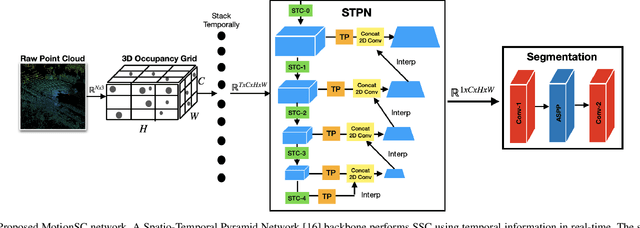
This work addresses a gap in semantic scene completion (SSC) data by creating a novel outdoor data set with accurate and complete dynamic scenes. Our data set is formed from randomly sampled views of the world at each time step, which supervises generalizability to complete scenes without occlusions or traces. We create SSC baselines from state-of-the-art open source networks and construct a benchmark real-time dense local semantic mapping algorithm, MotionSC, by leveraging recent 3D deep learning architectures to enhance SSC with temporal information. Our network shows that the proposed data set can quantify and supervise accurate scene completion in the presence of dynamic objects, which can lead to the development of improved dynamic mapping algorithms. All software is available at https://github.com/UMich-CURLY/3DMapping.