 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Collective Reasoning in Multi-Agent LLMs via Hidden Profile Tasks
May 15, 2025Multi-agent systems built on large language models (LLMs) promise enhanced problem-solving through distributed information integration, but also risk replicating collective reasoning failures observed in human groups. Yet, no theory-grounded benchmark exists to systematically evaluate such failures. In this paper, we introduce the Hidden Profile paradigm from social psychology as a diagnostic testbed for multi-agent LLM systems. By distributing critical information asymmetrically across agents, the paradigm reveals how inter-agent dynamics support or hinder collective reasoning. We first formalize the paradigm for multi-agent decision-making under distributed knowledge and instantiate it as a benchmark with nine tasks spanning diverse scenarios, including adaptations from prior human studies. We then conduct experiments with GPT-4.1 and five other leading LLMs, including reasoning-enhanced variants, showing that multi-agent systems across all models fail to match the accuracy of single agents given complete information. While agents' collective performance is broadly comparable to that of human groups, nuanced behavioral differences emerge, such as increased sensitivity to social desirability. Finally, we demonstrate the paradigm's diagnostic utility by exploring a cooperation-contradiction trade-off in multi-agent LLM systems. We find that while cooperative agents are prone to over-coordination in collective settings, increased contradiction impairs group convergence. This work contributes a reproducible framework for evaluating multi-agent LLM systems and motivates future research on artificial collective intelligence and human-AI interaction.
Spontaneous Giving and Calculated Greed in Language Models
Feb 24, 2025



Large language models, when trained with reinforcement learning, demonstrate advanced problem-solving capabilities through reasoning techniques like chain of thoughts and reflection. However, it is unclear how these reasoning capabilities extend to social intelligence. In this study, we investigate how reasoning influences model outcomes in social dilemmas. First, we examine the effects of chain-of-thought and reflection techniques in a public goods game. We then extend our analysis to six economic games on cooperation and punishment, comparing off-the-shelf non-reasoning and reasoning models. We find that reasoning models reduce cooperation and norm enforcement, prioritizing individual rationality. Consequently, groups with more reasoning models exhibit less cooperation and lower gains through repeated interactions. These behaviors parallel human tendencies of "spontaneous giving and calculated greed." Our results suggest the need for AI architectures that incorporate social intelligence alongside reasoning capabilities to ensure that AI supports, rather than disrupts, human cooperative intuition.
Actions Speak Louder than Words: Agent Decisions Reveal Implicit Biases in Language Models
Jan 29, 2025While advances in fairness and alignment have helped mitigate overt biases exhibited by large language models (LLMs) when explicitly prompted, we hypothesize that these models may still exhibit implicit biases when simulating human behavior. To test this hypothesis, we propose a technique to systematically uncover such biases across a broad range of sociodemographic categories by assessing decision-making disparities among agents with LLM-generated, sociodemographically-informed personas. Using our technique, we tested six LLMs across three sociodemographic groups and four decision-making scenarios. Our results show that state-of-the-art LLMs exhibit significant sociodemographic disparities in nearly all simulations, with more advanced models exhibiting greater implicit biases despite reducing explicit biases. Furthermore, when comparing our findings to real-world disparities reported in empirical studies, we find that the biases we uncovered are directionally aligned but markedly amplified. This directional alignment highlights the utility of our technique in uncovering systematic biases in LLMs rather than random variations; moreover, the presence and amplification of implicit biases emphasizes the need for novel strategies to address these biases.
Deconstructing Cooperation and Ostracism via Multi-Agent Reinforcement Learning
Oct 06, 2023

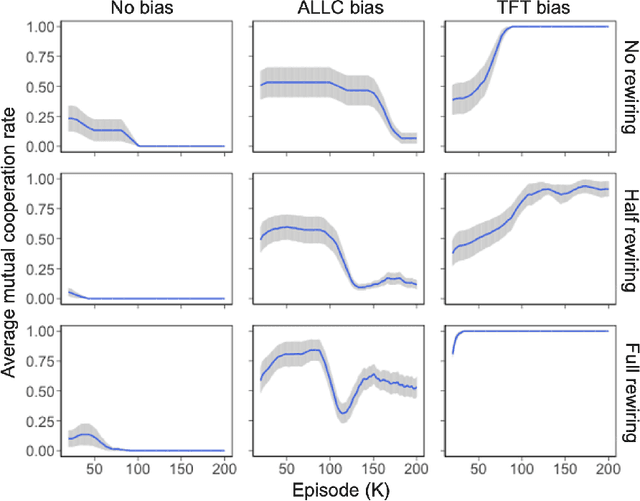

Cooperation is challenging in biological systems, human societies, and multi-agent systems in general. While a group can benefit when everyone cooperates, it is tempting for each agent to act selfishly instead. Prior human studies show that people can overcome such social dilemmas while choosing interaction partners, i.e., strategic network rewiring. However, little is known about how agents, including humans, can learn about cooperation from strategic rewiring and vice versa. Here, we perform multi-agent reinforcement learning simulations in which two agents play the Prisoner's Dilemma game iteratively. Each agent has two policies: one controls whether to cooperate or defect; the other controls whether to rewire connections with another agent. This setting enables us to disentangle complex causal dynamics between cooperation and network rewiring. We find that network rewiring facilitates mutual cooperation even when one agent always offers cooperation, which is vulnerable to free-riding. We then confirm that the network-rewiring effect is exerted through agents' learning of ostracism, that is, connecting to cooperators and disconnecting from defectors. However, we also find that ostracism alone is not sufficient to make cooperation emerge. Instead, ostracism emerges from the learning of cooperation, and existing cooperation is subsequently reinforced due to the presence of ostracism. Our findings provide insights into the conditions and mechanisms necessary for the emergence of cooperation with network rewiring.