 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Distribution-free Adaptive Computation of Matrix Functions for Accelerating Neural Network Training
Jan 29, 2026Matrix functions such as square root, inverse roots, and orthogonalization play a central role in preconditioned gradient methods for neural network training. This has motivated the development of iterative algorithms that avoid explicit eigendecompositions and rely primarily on matrix multiplications, making them well suited for modern GPU accelerators. We present PRISM (Polynomial-fitting and Randomized Iterative Sketching for Matrix functions computation), a general framework for accelerating iterative algorithms for computing matrix functions. PRISM combines adaptive polynomial approximation with randomized sketching: at each iteration, it fits a polynomial surrogate to the current spectrum via a sketched least-squares problem, adapting to the instance at hand with minimal overhead. We apply PRISM to accelerate Newton-Schulz-like iterations for matrix square roots and orthogonalization, which are core primitives in machine learning. Unlike prior methods, PRISM requires no explicit spectral bounds or singular value estimates; and it adapts automatically to the evolving spectrum. Empirically, PRISM accelerates training when integrated into Shampoo and Muon optimizers.
CATCH: A Controllable Theme Detection Framework with Contextualized Clustering and Hierarchical Generation
Dec 25, 2025Theme detection is a fundamental task in user-centric dialogue systems, aiming to identify the latent topic of each utterance without relying on predefined schemas. Unlike intent induction, which operates within fixed label spaces, theme detection requires cross-dialogue consistency and alignment with personalized user preferences, posing significant challenges. Existing methods often struggle with sparse, short utterances for accurate topic representation and fail to capture user-level thematic preferences across dialogues. To address these challenges, we propose CATCH (Controllable Theme Detection with Contextualized Clustering and Hierarchical Generation), a unified framework that integrates three core components: (1) context-aware topic representation, which enriches utterance-level semantics using surrounding topic segments; (2) preference-guided topic clustering, which jointly models semantic proximity and personalized feedback to align themes across dialogue; and (3) a hierarchical theme generation mechanism designed to suppress noise and produce robust, coherent topic labels. Experiments on a multi-domain customer dialogue benchmark (DSTC-12) demonstrate the effectiveness of CATCH with 8B LLM in both theme clustering and topic generation quality.
GarmentGS: Point-Cloud Guided Gaussian Splatting for High-Fidelity Non-Watertight 3D Garment Reconstruction
May 04, 2025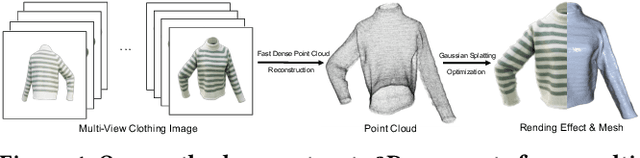
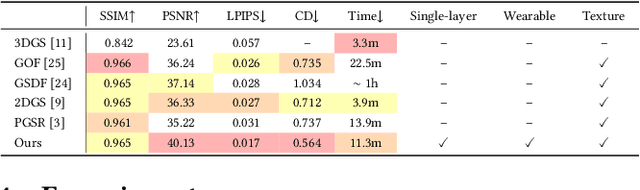
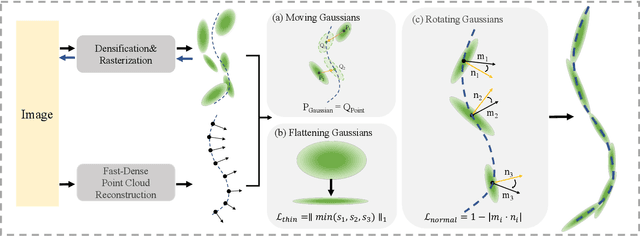
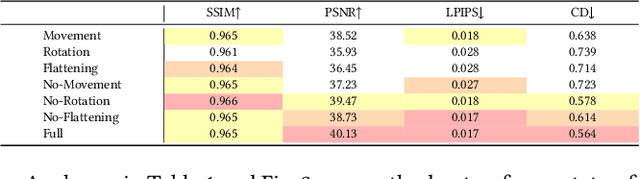
Traditional 3D garment creation requires extensive manual operations, resulting in time and labor costs. Recently, 3D Gaussian Splatting has achieved breakthrough progress in 3D scene reconstruction and rendering, attracting widespread attention and opening new pathways for 3D garment reconstruction. However, due to the unstructured and irregular nature of Gaussian primitives, it is difficult to reconstruct high-fidelity, non-watertight 3D garments. In this paper, we present GarmentGS, a dense point cloud-guided method that can reconstruct high-fidelity garment surfaces with high geometric accuracy and generate non-watertight, single-layer meshes. Our method introduces a fast dense point cloud reconstruction module that can complete garment point cloud reconstruction in 10 minutes, compared to traditional methods that require several hours. Furthermore, we use dense point clouds to guide the movement, flattening, and rotation of Gaussian primitives, enabling better distribution on the garment surface to achieve superior rendering effects and geometric accuracy. Through numerical and visual comparisons, our method achieves fast training and real-time rendering while maintaining competitive quality.
Know You First and Be You Better: Modeling Human-Like User Simulators via Implicit Profiles
Feb 26, 2025User simulators are crucial for replicating human interactions with dialogue systems, supporting both collaborative training and automatic evaluation, especially for large language models (LLMs). However, existing simulators often rely solely on text utterances, missing implicit user traits such as personality, speaking style, and goals. In contrast, persona-based methods lack generalizability, as they depend on predefined profiles of famous individuals or archetypes. To address these challenges, we propose User Simulator with implicit Profiles (USP), a framework that infers implicit user profiles from human-machine conversations and uses them to generate more personalized and realistic dialogues. We first develop an LLM-driven extractor with a comprehensive profile schema. Then, we refine the simulation through conditional supervised fine-tuning and reinforcement learning with cycle consistency, optimizing it at both the utterance and conversation levels. Finally, we adopt a diverse profile sampler to capture the distribution of real-world user profiles. Experimental results demonstrate that USP outperforms strong baselines in terms of authenticity and diversity while achieving comparable performance in consistency. Furthermore, dynamic multi-turn evaluations based on USP strongly align with mainstream benchmarks, demonstrating its effectiveness in real-world applications.
Using Pre-trained LLMs for Multivariate Time Series Forecasting
Jan 10, 2025



Pre-trained Large Language Models (LLMs) encapsulate large amounts of knowledge and take enormous amounts of compute to train. We make use of this resource, together with the observation that LLMs are able to transfer knowledge and performance from one domain or even modality to another seemingly-unrelated area, to help with multivariate demand time series forecasting. Attention in transformer-based methods requires something worth attending to -- more than just samples of a time-series. We explore different methods to map multivariate input time series into the LLM token embedding space. In particular, our novel multivariate patching strategy to embed time series features into decoder-only pre-trained Transformers produces results competitive with state-of-the-art time series forecasting models. We also use recently-developed weight-based diagnostics to validate our findings.
Positional Attention: Out-of-Distribution Generalization and Expressivity for Neural Algorithmic Reasoning
Oct 02, 2024There has been a growing interest in the ability of neural networks to solve algorithmic tasks, such as arithmetic, summary statistics, and sorting. While state-of-the-art models like Transformers have demonstrated good generalization performance on in-distribution tasks, their out-of-distribution (OOD) performance is poor when trained end-to-end. In this paper, we focus on value generalization, a common instance of OOD generalization where the test distribution has the same input sequence length as the training distribution, but the value ranges in the training and test distributions do not necessarily overlap. To address this issue, we propose that using fixed positional encodings to determine attention weights-referred to as positional attention-enhances empirical OOD performance while maintaining expressivity. We support our claim about expressivity by proving that Transformers with positional attention can effectively simulate parallel algorithms.
Sequential Recommendation with Latent Relations based on Large Language Model
Mar 27, 2024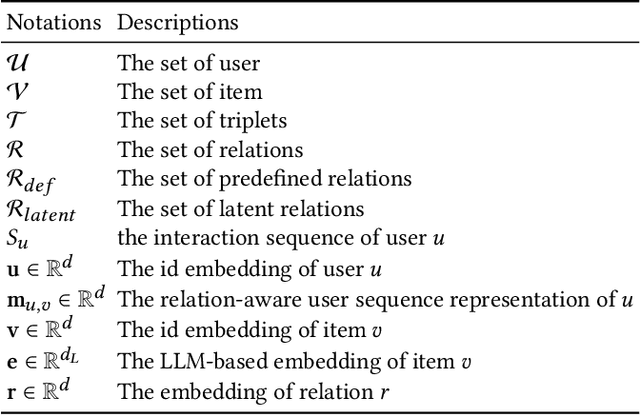
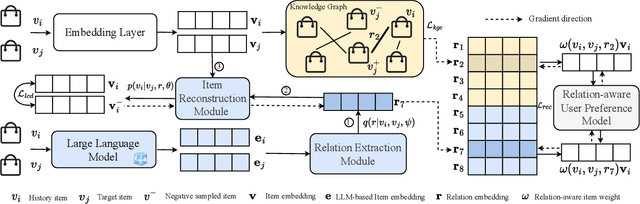

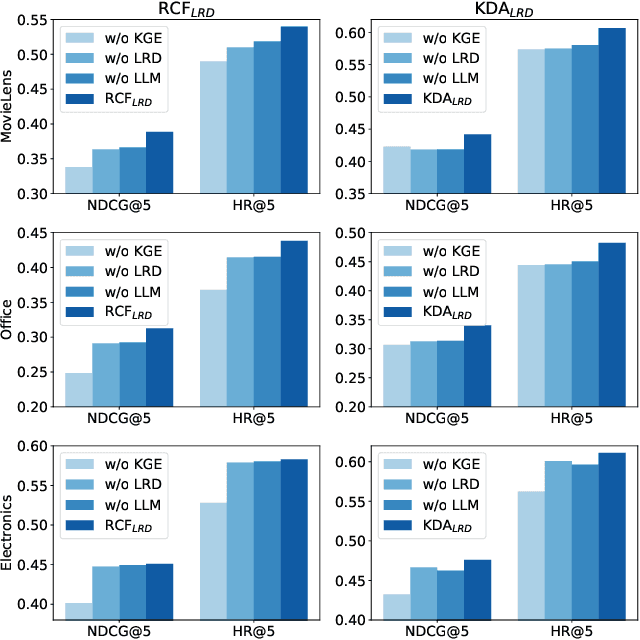
Sequential recommender systems predict items that may interest users by modeling their preferences based on historical interactions. Traditional sequential recommendation methods rely on capturing implicit collaborative filtering signals among items. Recent relation-aware sequential recommendation models have achieved promising performance by explicitly incorporating item relations into the modeling of user historical sequences, where most relations are extracted from knowledge graphs. However, existing methods rely on manually predefined relations and suffer the sparsity issue, limiting the generalization ability in diverse scenarios with varied item relations. In this paper, we propose a novel relation-aware sequential recommendation framework with Latent Relation Discovery (LRD). Different from previous relation-aware models that rely on predefined rules, we propose to leverage the Large Language Model (LLM) to provide new types of relations and connections between items. The motivation is that LLM contains abundant world knowledge, which can be adopted to mine latent relations of items for recommendation. Specifically, inspired by that humans can describe relations between items using natural language, LRD harnesses the LLM that has demonstrated human-like knowledge to obtain language knowledge representations of items. These representations are fed into a latent relation discovery module based on the discrete state variational autoencoder (DVAE). Then the self-supervised relation discovery tasks and recommendation tasks are jointly optimized. Experimental results on multiple public datasets demonstrate our proposed latent relations discovery method can be incorporated with existing relation-aware sequential recommendation models and significantly improve the performance. Further analysis experiments indicate the effectiveness and reliability of the discovered latent relations.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024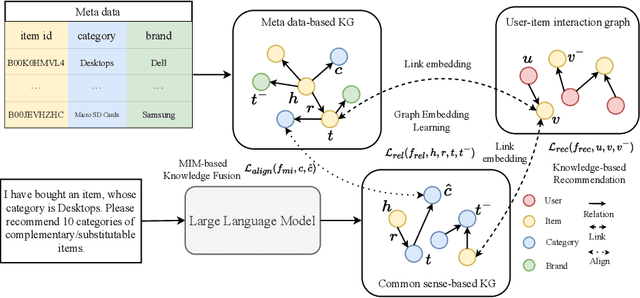


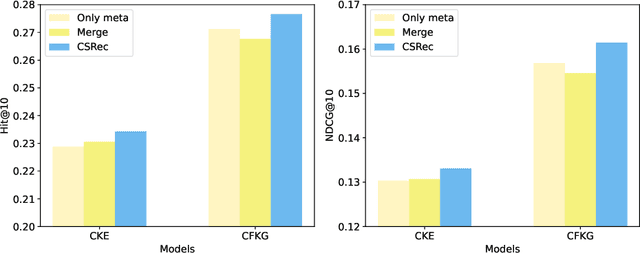
Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.
Collaborative Word-based Pre-trained Item Representation for Transferable Recommendation
Nov 17, 2023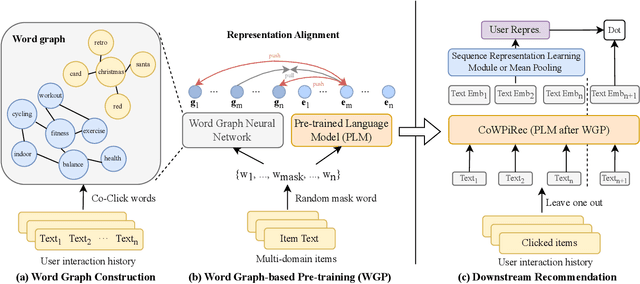
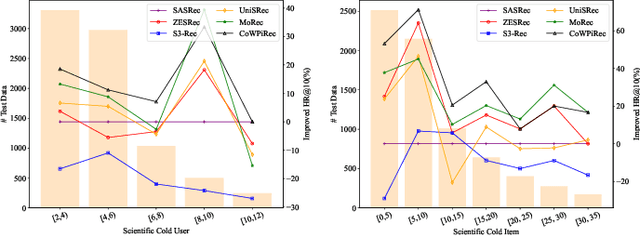
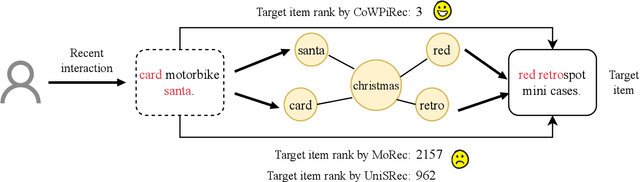
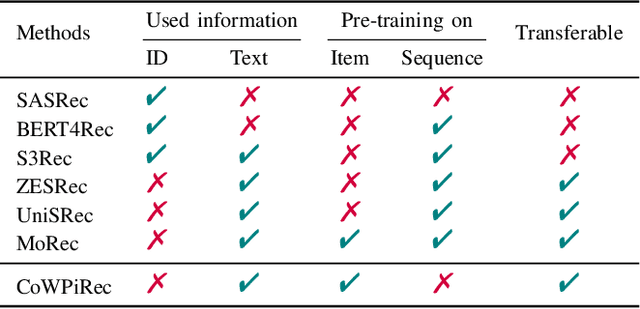
Item representation learning (IRL) plays an essential role in recommender systems, especially for sequential recommendation. Traditional sequential recommendation models usually utilize ID embeddings to represent items, which are not shared across different domains and lack the transferable ability. Recent studies use pre-trained language models (PLM) for item text embeddings (text-based IRL) that are universally applicable across domains. However, the existing text-based IRL is unaware of the important collaborative filtering (CF) information. In this paper, we propose CoWPiRec, an approach of Collaborative Word-based Pre-trained item representation for Recommendation. To effectively incorporate CF information into text-based IRL, we convert the item-level interaction data to a word graph containing word-level collaborations. Subsequently, we design a novel pre-training task to align the word-level semantic- and CF-related item representation. Extensive experimental results on multiple public datasets demonstrate that compared to state-of-the-art transferable sequential recommenders, CoWPiRec achieves significantly better performances in both fine-tuning and zero-shot settings for cross-scenario recommendation and effectively alleviates the cold-start issue. The code is available at: https://github.com/ysh-1998/CoWPiRec.
Local Graph Clustering with Noisy Labels
Oct 12, 2023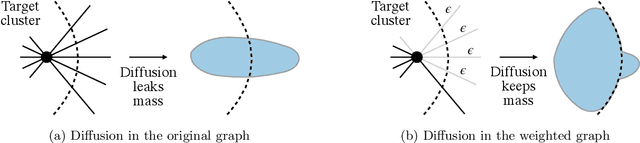
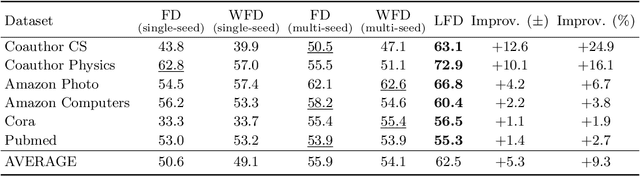
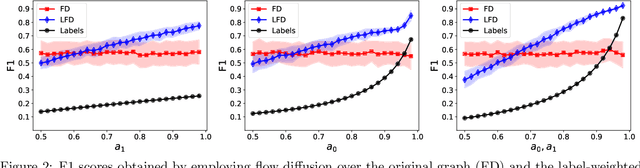
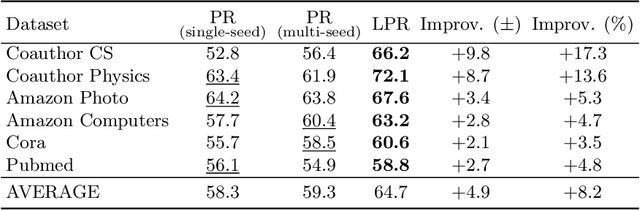
The growing interest in machine learning problems over graphs with additional node information such as texts, images, or labels has popularized methods that require the costly operation of processing the entire graph. Yet, little effort has been made to the development of fast local methods (i.e. without accessing the entire graph) that extract useful information from such data. To that end, we propose a study of local graph clustering using noisy node labels as a proxy for additional node information. In this setting, nodes receive initial binary labels based on cluster affiliation: 1 if they belong to the target cluster and 0 otherwise. Subsequently, a fraction of these labels is flipped. We investigate the benefits of incorporating noisy labels for local graph clustering. By constructing a weighted graph with such labels, we study the performance of graph diffusion-based local clustering method on both the original and the weighted graphs. From a theoretical perspective, we consider recovering an unknown target cluster with a single seed node in a random graph with independent noisy node labels. We provide sufficient conditions on the label noise under which, with high probability, using diffusion in the weighted graph yields a more accurate recovery of the target cluster. This approach proves more effective than using the given labels alone or using diffusion in the label-free original graph. Empirically, we show that reliable node labels can be obtained with just a few samples from an attributed graph. Moreover, utilizing these labels via diffusion in the weighted graph leads to significantly better local clustering performance across several real-world datasets, improving F1 scores by up to 13%.