 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Word-based Pre-trained Item Representation for Transferable Recommendation
Nov 17, 2023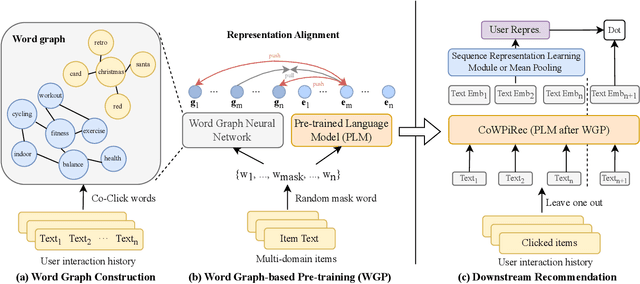
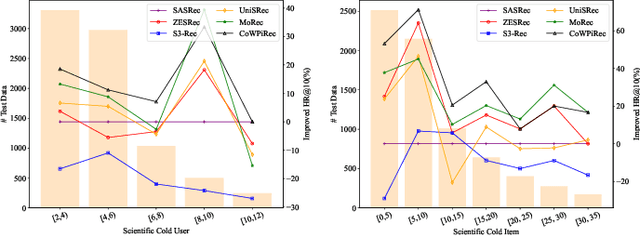
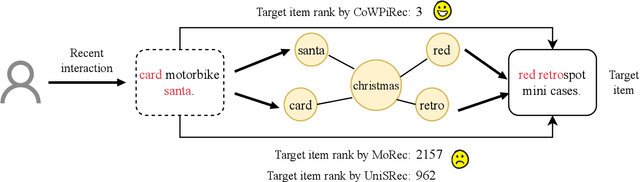
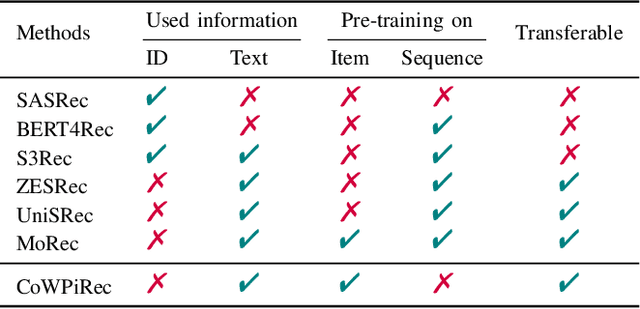
Item representation learning (IRL) plays an essential role in recommender systems, especially for sequential recommendation. Traditional sequential recommendation models usually utilize ID embeddings to represent items, which are not shared across different domains and lack the transferable ability. Recent studies use pre-trained language models (PLM) for item text embeddings (text-based IRL) that are universally applicable across domains. However, the existing text-based IRL is unaware of the important collaborative filtering (CF) information. In this paper, we propose CoWPiRec, an approach of Collaborative Word-based Pre-trained item representation for Recommendation. To effectively incorporate CF information into text-based IRL, we convert the item-level interaction data to a word graph containing word-level collaborations. Subsequently, we design a novel pre-training task to align the word-level semantic- and CF-related item representation. Extensive experimental results on multiple public datasets demonstrate that compared to state-of-the-art transferable sequential recommenders, CoWPiRec achieves significantly better performances in both fine-tuning and zero-shot settings for cross-scenario recommendation and effectively alleviates the cold-start issue. The code is available at: https://github.com/ysh-1998/CoWPiRec.
Scene Recognition with Prototype-agnostic Scene Layout
Sep 07, 2019
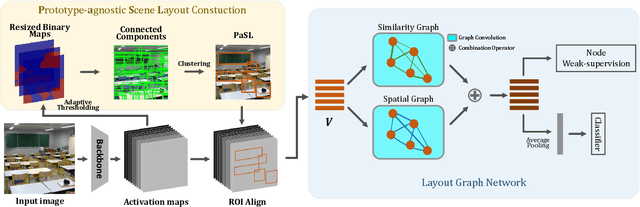

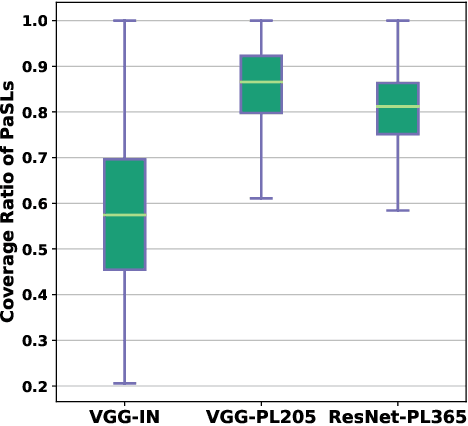
Abstract--- Exploiting the spatial structure in scene images is a key research direction for scene recognition. Due to the large intra-class structural diversity, building and modeling flexible structural layout to adapt various image characteristics is a challenge. Existing structural modeling methods in scene recognition either focus on predefined grids or rely on learned prototypes, which all have limited representative ability. In this paper, we propose Prototype-agnostic Scene Layout (PaSL) construction method to build the spatial structure for each image without conforming to any prototype. Our PaSL can flexibly capture the diverse spatial characteristic of scene images and have considerable generalization capability. Given a PaSL, we build Layout Graph Network (LGN) where regions in PaSL are defined as nodes and two kinds of independent relations between regions are encoded as edges. The LGN aims to incorporate two topological structures (formed in spatial and semantic similarity dimensions) into image representations through graph convolution. Extensive experiments show that our approach achieves state-of-the-art results on widely recognized MIT67 and SUN397 datasets without multi-model or multi-scale fusion. Moreover, we also conduct the experiments on one of the largest scale datasets, Places365. The results demonstrate the proposed method can be well generalized and obtains competitive performance.