 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Representational Position Encoding
Dec 08, 2025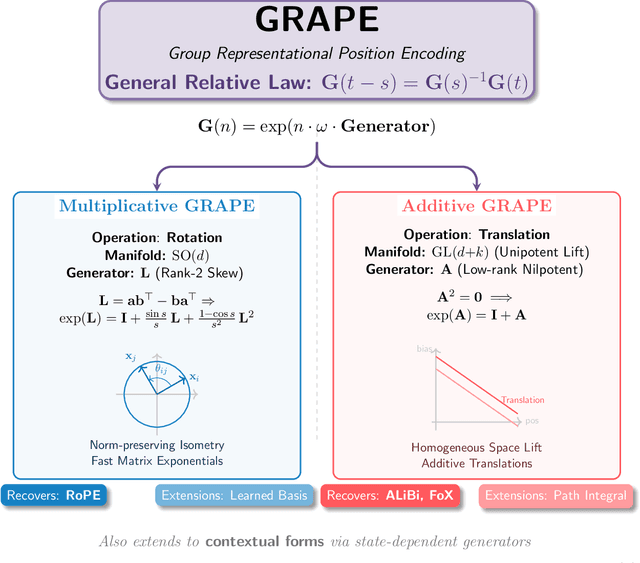
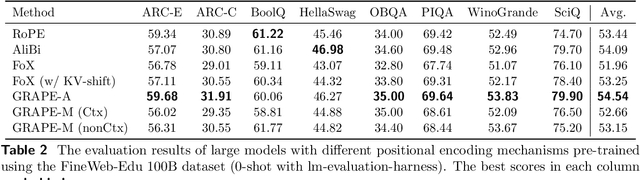
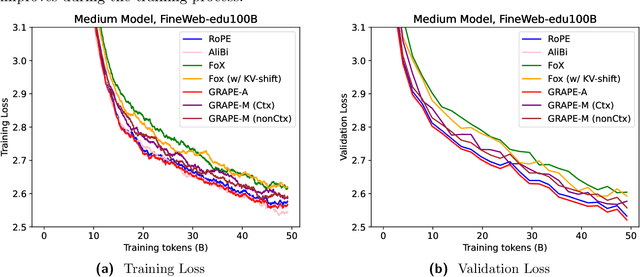

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
General Preference Modeling with Preference Representations for Aligning Language Models
Oct 03, 2024

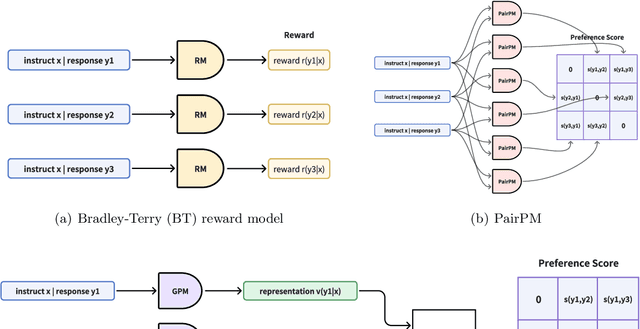

Modeling human preferences is crucial for aligning foundation models with human values. Traditional reward modeling methods, such as the Bradley-Terry (BT) reward model, fall short in expressiveness, particularly in addressing intransitive preferences. Although supervised pair preference models (PairPM) can express general preferences, their implementation is highly ad-hoc and cannot guarantee a consistent preference probability of compared pairs. Additionally, they impose high computational costs due to their quadratic query complexity when comparing multiple responses. In this paper, we introduce preference representation learning, an approach that embeds responses into a latent space to capture intricate preference structures efficiently, achieving linear query complexity. Additionally, we propose preference score-based General Preference Optimization (GPO), which generalizes reward-based reinforcement learning from human feedback. Experimental results show that our General Preference representation model (GPM) outperforms the BT reward model on the RewardBench benchmark with a margin of up to 5.6% and effectively models cyclic preferences where any BT reward model behaves like a random guess. Furthermore, evaluations on downstream tasks such as AlpacaEval2.0 and MT-Bench, following the language model post-training with GPO and our general preference model, reveal substantial performance improvements with margins up to 9.3%. These findings indicate that our method may enhance the alignment of foundation models with nuanced human values. The code is available at https://github.com/general-preference/general-preference-model.
Collaborative Word-based Pre-trained Item Representation for Transferable Recommendation
Nov 17, 2023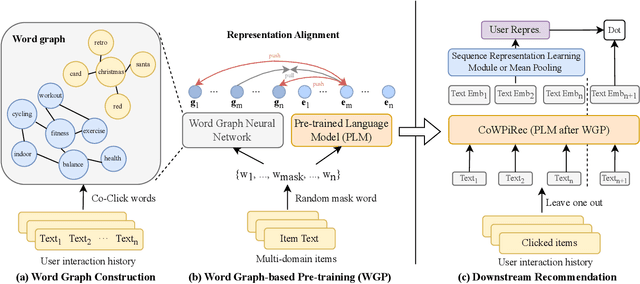
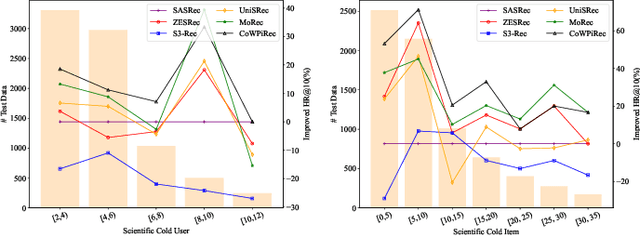
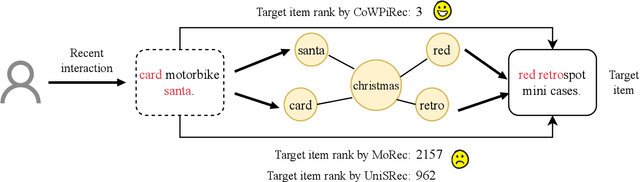
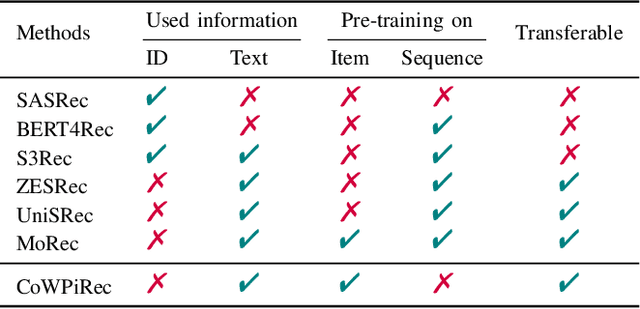
Item representation learning (IRL) plays an essential role in recommender systems, especially for sequential recommendation. Traditional sequential recommendation models usually utilize ID embeddings to represent items, which are not shared across different domains and lack the transferable ability. Recent studies use pre-trained language models (PLM) for item text embeddings (text-based IRL) that are universally applicable across domains. However, the existing text-based IRL is unaware of the important collaborative filtering (CF) information. In this paper, we propose CoWPiRec, an approach of Collaborative Word-based Pre-trained item representation for Recommendation. To effectively incorporate CF information into text-based IRL, we convert the item-level interaction data to a word graph containing word-level collaborations. Subsequently, we design a novel pre-training task to align the word-level semantic- and CF-related item representation. Extensive experimental results on multiple public datasets demonstrate that compared to state-of-the-art transferable sequential recommenders, CoWPiRec achieves significantly better performances in both fine-tuning and zero-shot settings for cross-scenario recommendation and effectively alleviates the cold-start issue. The code is available at: https://github.com/ysh-1998/CoWPiRec.