 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Agent Steer: Closed-Loop Ranking Optimization via Influence Exchange
Mar 31, 2026Recommendation ranking is fundamentally an influence allocation problem: a sorting formula distributes ranking influence among competing factors, and the business outcome depends on finding the optimal "exchange rates" among them. However, offline proxy metrics systematically misjudge how influence reallocation translates to online impact, with asymmetric bias across metrics that a single calibration factor cannot correct. We present Sortify, the first fully autonomous LLM-driven ranking optimization agent deployed in a large-scale production recommendation system. The agent reframes ranking optimization as continuous influence exchange, closing the full loop from diagnosis to parameter deployment without human intervention. It addresses structural problems through three mechanisms: (1) a dual-channel framework grounded in Savage's Subjective Expected Utility (SEU) that decouples offline-online transfer correction (Belief channel) from constraint penalty adjustment (Preference channel); (2) an LLM meta-controller operating on framework-level parameters rather than low-level search variables; (3) a persistent Memory DB with 7 relational tables for cross-round learning. Its core metric, Influence Share, provides a decomposable measure where all factor contributions sum to exactly 100%. Sortify has been deployed across two markets. In Country A, the agent pushed GMV from -3.6% to +9.2% within 7 rounds with peak orders reaching +12.5%. In Country B, a cold-start deployment achieved +4.15% GMV/UU and +3.58% Ads Revenue in a 7-day A/B test, leading to full production rollout.
DTN: Deep Multiple Task-specific Feature Interactions Network for Multi-Task Recommendation
Aug 21, 2024



Neural-based multi-task learning (MTL) has been successfully applied to many recommendation applications. However, these MTL models (e.g., MMoE, PLE) did not consider feature interaction during the optimization, which is crucial for capturing complex high-order features and has been widely used in ranking models for real-world recommender systems. Moreover, through feature importance analysis across various tasks in MTL, we have observed an interesting divergence phenomenon that the same feature can have significantly different importance across different tasks in MTL. To address these issues, we propose Deep Multiple Task-specific Feature Interactions Network (DTN) with a novel model structure design. DTN introduces multiple diversified task-specific feature interaction methods and task-sensitive network in MTL networks, enabling the model to learn task-specific diversified feature interaction representations, which improves the efficiency of joint representation learning in a general setup. We applied DTN to our company's real-world E-commerce recommendation dataset, which consisted of over 6.3 billion samples, the results demonstrated that DTN significantly outperformed state-of-the-art MTL models. Moreover, during online evaluation of DTN in a large-scale E-commerce recommender system, we observed a 3.28% in clicks, a 3.10% increase in orders and a 2.70% increase in GMV (Gross Merchandise Value) compared to the state-of-the-art MTL models. Finally, extensive offline experiments conducted on public benchmark datasets demonstrate that DTN can be applied to various scenarios beyond recommendations, enhancing the performance of ranking models.
Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
Mar 27, 2024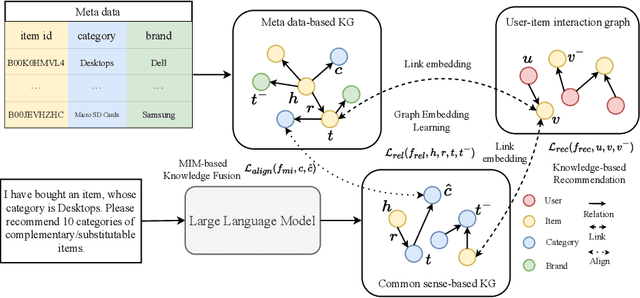


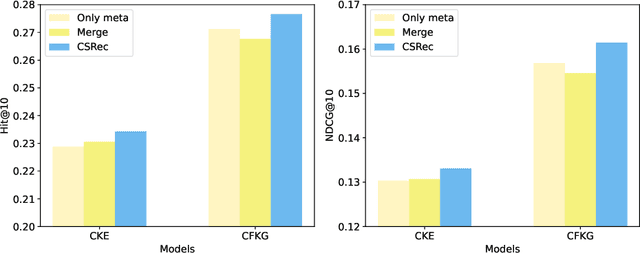
Knowledge-based recommendation models effectively alleviate the data sparsity issue leveraging the side information in the knowledge graph, and have achieved considerable performance. Nevertheless, the knowledge graphs used in previous work, namely metadata-based knowledge graphs, are usually constructed based on the attributes of items and co-occurring relations (e.g., also buy), in which the former provides limited information and the latter relies on sufficient interaction data and still suffers from cold start issue. Common sense, as a form of knowledge with generality and universality, can be used as a supplement to the metadata-based knowledge graph and provides a new perspective for modeling users' preferences. Recently, benefiting from the emergent world knowledge of the large language model, efficient acquisition of common sense has become possible. In this paper, we propose a novel knowledge-based recommendation framework incorporating common sense, CSRec, which can be flexibly coupled to existing knowledge-based methods. Considering the challenge of the knowledge gap between the common sense-based knowledge graph and metadata-based knowledge graph, we propose a knowledge fusion approach based on mutual information maximization theory. Experimental results on public datasets demonstrate that our approach significantly improves the performance of existing knowledge-based recommendation models.
Sequential Recommendation with Latent Relations based on Large Language Model
Mar 27, 2024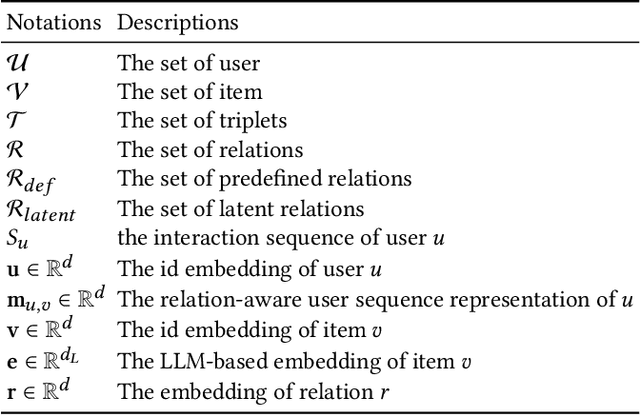
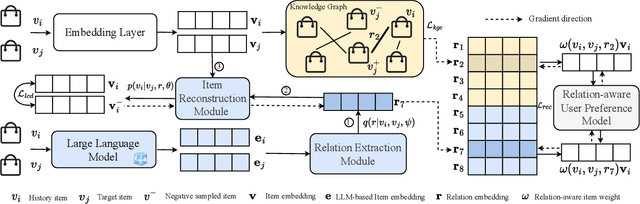

Sequential recommender systems predict items that may interest users by modeling their preferences based on historical interactions. Traditional sequential recommendation methods rely on capturing implicit collaborative filtering signals among items. Recent relation-aware sequential recommendation models have achieved promising performance by explicitly incorporating item relations into the modeling of user historical sequences, where most relations are extracted from knowledge graphs. However, existing methods rely on manually predefined relations and suffer the sparsity issue, limiting the generalization ability in diverse scenarios with varied item relations. In this paper, we propose a novel relation-aware sequential recommendation framework with Latent Relation Discovery (LRD). Different from previous relation-aware models that rely on predefined rules, we propose to leverage the Large Language Model (LLM) to provide new types of relations and connections between items. The motivation is that LLM contains abundant world knowledge, which can be adopted to mine latent relations of items for recommendation. Specifically, inspired by that humans can describe relations between items using natural language, LRD harnesses the LLM that has demonstrated human-like knowledge to obtain language knowledge representations of items. These representations are fed into a latent relation discovery module based on the discrete state variational autoencoder (DVAE). Then the self-supervised relation discovery tasks and recommendation tasks are jointly optimized. Experimental results on multiple public datasets demonstrate our proposed latent relations discovery method can be incorporated with existing relation-aware sequential recommendation models and significantly improve the performance. Further analysis experiments indicate the effectiveness and reliability of the discovered latent relations.
Sequence-level Semantic Representation Fusion for Recommender Systems
Feb 28, 2024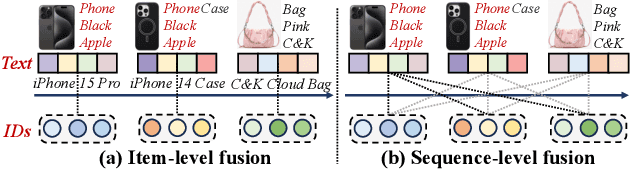
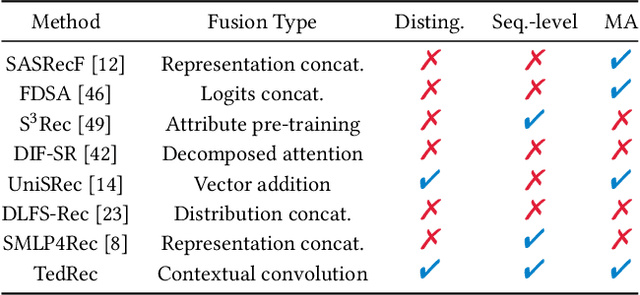
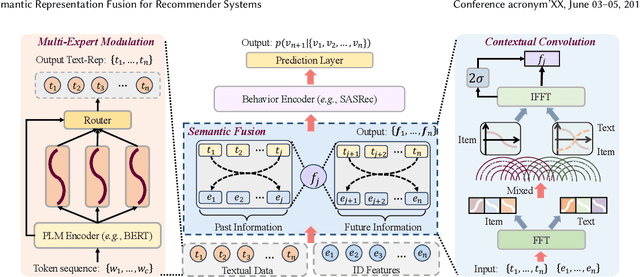
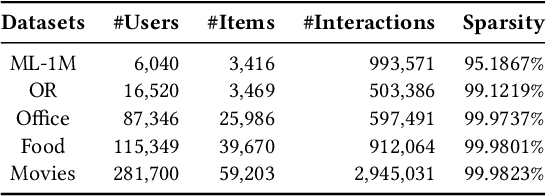
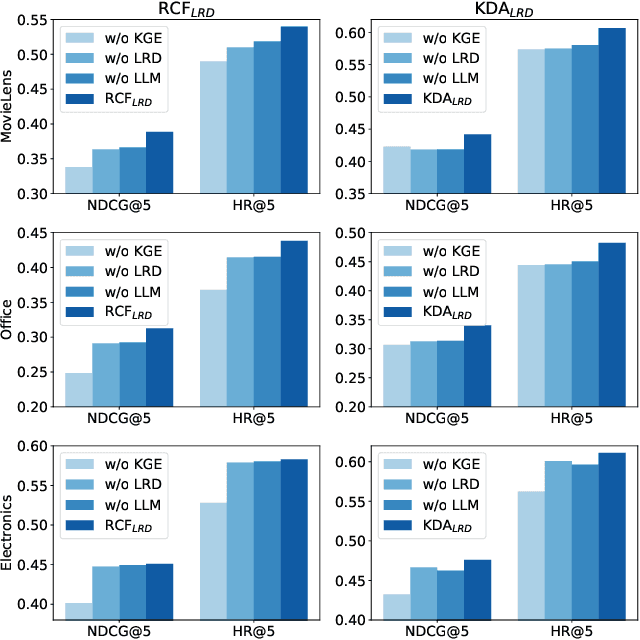
With the rapid development of recommender systems, there is increasing side information that can be employed to improve the recommendation performance. Specially, we focus on the utilization of the associated \emph{textual data} of items (eg product title) and study how text features can be effectively fused with ID features in sequential recommendation. However, there exists distinct data characteristics for the two kinds of item features, making a direct fusion method (eg adding text and ID embeddings as item representation) become less effective. To address this issue, we propose a novel {\ul \emph{Te}}xt-I{\ul \emph{D}} semantic fusion approach for sequential {\ul \emph{Rec}}ommendation, namely \textbf{\our}. The core idea of our approach is to conduct a sequence-level semantic fusion approach by better integrating global contexts. The key strategy lies in that we transform the text embeddings and ID embeddings by Fourier Transform from \emph{time domain} to \emph{frequency domain}. In the frequency domain, the global sequential characteristics of the original sequences are inherently aggregated into the transformed representations, so that we can employ simple multiplicative operations to effectively fuse the two kinds of item features. Our fusion approach can be proved to have the same effects of contextual convolution, so as to achieving sequence-level semantic fusion. In order to further improve the fusion performance, we propose to enhance the discriminability of the text embeddings from the text encoder, by adaptively injecting positional information via a mixture-of-experts~(MoE) modulation method. Our implementation is available at this repository: \textcolor{magenta}{\url{https://github.com/RUCAIBox/TedRec}}.
Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis
Jan 10, 2024



Recently, large language models such as ChatGPT have showcased remarkable abilities in solving general tasks, demonstrating the potential for applications in recommender systems. To assess how effectively LLMs can be used in recommendation tasks, our study primarily focuses on employing LLMs as recommender systems through prompting engineering. We propose a general framework for utilizing LLMs in recommendation tasks, focusing on the capabilities of LLMs as recommenders. To conduct our analysis, we formalize the input of LLMs for recommendation into natural language prompts with two key aspects, and explain how our framework can be generalized to various recommendation scenarios. As for the use of LLMs as recommenders, we analyze the impact of public availability, tuning strategies, model architecture, parameter scale, and context length on recommendation results based on the classification of LLMs. As for prompt engineering, we further analyze the impact of four important components of prompts, \ie task descriptions, user interest modeling, candidate items construction and prompting strategies. In each section, we first define and categorize concepts in line with the existing literature. Then, we propose inspiring research questions followed by experiments to systematically analyze the impact of different factors on two public datasets. Finally, we summarize promising directions to shed lights on future research.
What Makes for Good Visual Instructions? Synthesizing Complex Visual Reasoning Instructions for Visual Instruction Tuning
Nov 02, 2023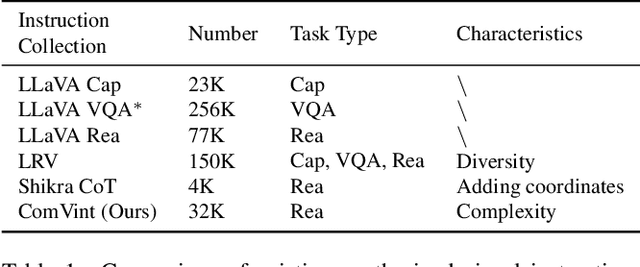
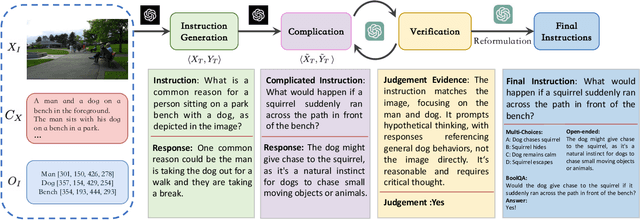
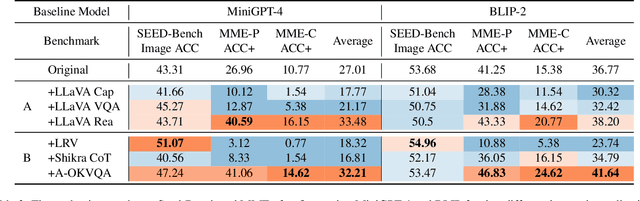

Visual instruction tuning is an essential approach to improving the zero-shot generalization capability of Multi-modal Large Language Models (MLLMs). A surge of visual instruction datasets with various focuses and characteristics have been proposed recently, enabling MLLMs to achieve surprising results on evaluation benchmarks. To develop more capable MLLMs, in this paper, we aim to investigate a more fundamental question: ``what makes for good visual instructions?''. By conducting a comprehensive empirical study, we find that instructions focused on complex visual reasoning tasks are particularly effective in improving the performance of MLLMs on evaluation benchmarks. Building upon this finding, we design a systematic approach to automatically creating high-quality complex visual reasoning instructions. Our approach employs a synthesis-complication-reformulation paradigm, leveraging multiple stages to gradually increase the complexity of the instructions while guaranteeing quality. Based on this approach, we create the synthetic visual reasoning instruction dataset consisting of 32K examples, namely ComVint, and fine-tune four MLLMs on it. Experimental results demonstrate that our dataset consistently enhances the performance of all the compared MLLMs, e.g., improving the performance of MiniGPT-4 and BLIP-2 on MME-Cognition by 32.6% and 28.8%, respectively. Our code and data are publicly available at the link: https://github.com/RUCAIBox/ComVint.
PREFER: Prompt Ensemble Learning via Feedback-Reflect-Refine
Aug 23, 2023



As an effective tool for eliciting the power of Large Language Models (LLMs), prompting has recently demonstrated unprecedented abilities across a variety of complex tasks. To further improve the performance, prompt ensemble has attracted substantial interest for tackling the hallucination and instability of LLMs. However, existing methods usually adopt a two-stage paradigm, which requires a pre-prepared set of prompts with substantial manual effort, and is unable to perform directed optimization for different weak learners. In this paper, we propose a simple, universal, and automatic method named PREFER (Pompt Ensemble learning via Feedback-Reflect-Refine) to address the stated limitations. Specifically, given the fact that weak learners are supposed to focus on hard examples during boosting, PREFER builds a feedback mechanism for reflecting on the inadequacies of existing weak learners. Based on this, the LLM is required to automatically synthesize new prompts for iterative refinement. Moreover, to enhance stability of the prompt effect evaluation, we propose a novel prompt bagging method involving forward and backward thinking, which is superior to majority voting and is beneficial for both feedback and weight calculation in boosting. Extensive experiments demonstrate that our PREFER achieves state-of-the-art performance in multiple types of tasks by a significant margin. We have made our code publicly available.
Enhancing Personalized Ranking With Differentiable Group AUC Optimization
Apr 17, 2023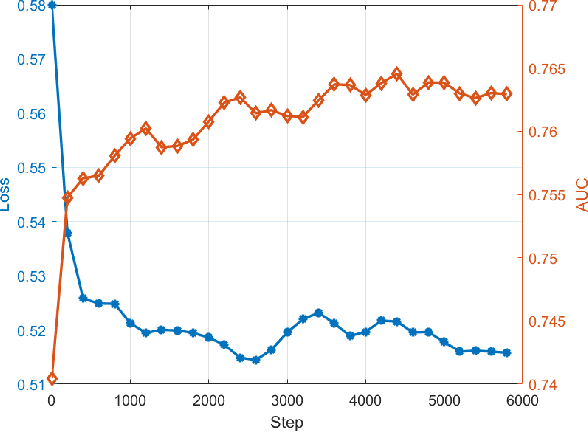



AUC is a common metric for evaluating the performance of a classifier. However, most classifiers are trained with cross entropy, and it does not optimize the AUC metric directly, which leaves a gap between the training and evaluation stage. In this paper, we propose the PDAOM loss, a Personalized and Differentiable AUC Optimization method with Maximum violation, which can be directly applied when training a binary classifier and optimized with gradient-based methods. Specifically, we construct the pairwise exponential loss with difficult pair of positive and negative samples within sub-batches grouped by user ID, aiming to guide the classifier to pay attention to the relation between hard-distinguished pairs of opposite samples from the perspective of independent users. Compared to the origin form of pairwise exponential loss, the proposed PDAOM loss not only improves the AUC and GAUC metrics in the offline evaluation, but also reduces the computation complexity of the training objective. Furthermore, online evaluation of the PDAOM loss on the 'Guess What You Like' feed recommendation application in Meituan manifests 1.40% increase in click count and 0.65% increase in order count compared to the baseline model, which is a significant improvement in this well-developed online life service recommendation system.