 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Good Visual Instructions? Synthesizing Complex Visual Reasoning Instructions for Visual Instruction Tuning
Paper and Code
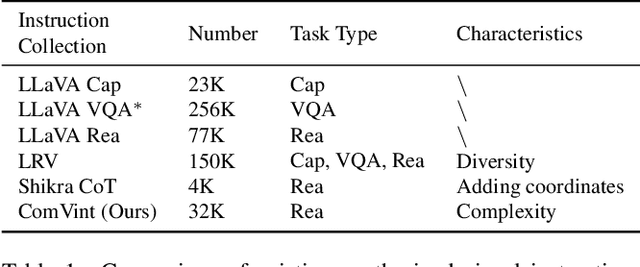
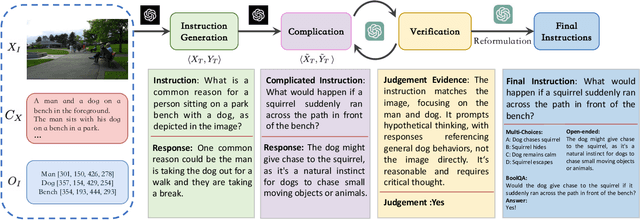
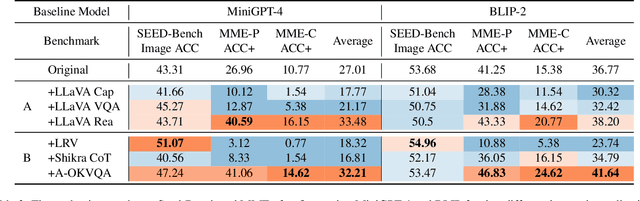

Visual instruction tuning is an essential approach to improving the zero-shot generalization capability of Multi-modal Large Language Models (MLLMs). A surge of visual instruction datasets with various focuses and characteristics have been proposed recently, enabling MLLMs to achieve surprising results on evaluation benchmarks. To develop more capable MLLMs, in this paper, we aim to investigate a more fundamental question: ``what makes for good visual instructions?''. By conducting a comprehensive empirical study, we find that instructions focused on complex visual reasoning tasks are particularly effective in improving the performance of MLLMs on evaluation benchmarks. Building upon this finding, we design a systematic approach to automatically creating high-quality complex visual reasoning instructions. Our approach employs a synthesis-complication-reformulation paradigm, leveraging multiple stages to gradually increase the complexity of the instructions while guaranteeing quality. Based on this approach, we create the synthetic visual reasoning instruction dataset consisting of 32K examples, namely ComVint, and fine-tune four MLLMs on it. Experimental results demonstrate that our dataset consistently enhances the performance of all the compared MLLMs, e.g., improving the performance of MiniGPT-4 and BLIP-2 on MME-Cognition by 32.6% and 28.8%, respectively. Our code and data are publicly available at the link: https://github.com/RUCAIBox/ComVint.